데이터 세트 조작 및 데이터 프레임 관리를 위한 기본 도구로서 판다의 활용은 오랜 기간에 걸쳐 널리 확립되어 왔습니다. 그러나 인공 지능 영역의 발전과 함께 새롭게 등장한 오픈 소스 라이브러리인 판다AI는 판다의 프레임워크 내에 혁신적인 인공 지능 기능을 통합했습니다.
판다AI는 생성형 인공지능 기능을 통합하여 판다의 기존 기능을 보강합니다. 이를 통해 사용자는 대화형 인터페이스를 통해 데이터 분석을 수행할 수 있으며, PandasAI는 요청을 처리하고 기본 작업에 대한 이해를 단순화하는 방식으로 결과를 제시합니다.
PandasAI 설치하기
PandasAI 은 PyPI(Python 패키지 색인)를 통해 사용할 수 있습니다. 로컬 IDE를 사용하는 경우 새 가상 환경을 생성합니다. 그런 다음 pip 패키지 관리자를 사용하여 설치합니다.
pip install pandasai
Google Colab을 사용하는 동안 발생할 수 있는 잠재적인 문제는 다음과 같은 오류 메시지 형태로 표시됩니다:
IPython 버전이 축소되지 않도록 요청합니다. 이러한 작업은 실행하지 마시기 바랍니다. 상황을 해결하려면 앞서 언급한 코드 블록을 다시 실행하여 런타임을 새로 고쳐주세요.
전체 소스 코드는 GitHub 리포지토리를 통해 액세스할 수 있습니다.
샘플 데이터셋 이해하기
PandasAI로 조작할 샘플 데이터셋은 Kaggle의 캘리포니아 주택 가격 데이터셋입니다. 이 데이터 세트에는 1990년 캘리포니아 인구 조사의 주택에 대한 정보가 포함되어 있습니다. 이 데이터 집합에는 주택에 대한 통계를 제공하는 10개의 열이 있습니다. 이 데이터 집합에 대해 자세히 알아볼 수 있는 데이터 카드는 Kaggle 에서 사용할 수 있습니다. 아래는 데이터 집합의 처음 다섯 행입니다.

이 표의 모든 열은 특정 주거지와 관련된 특정 통계 값에 해당합니다.
대규모 언어 모델에 판다AI 연결하기
판다AI를 OpenAI와 같은 대규모 언어 모델(LLM)에 연결하려면 해당 API 키에 액세스해야 합니다. 이를 얻으려면 OpenAI 플랫폼 로 이동하세요. 그런 다음 계정에 로그인합니다. 다음에 표시되는 옵션 페이지에서 API를 선택합니다.

프로필을 클릭하고 ‘API 키 보기’ 옵션을 선택하여 새 API 키를 직접 생성하세요. 다음 페이지에 액세스하면 “새 비밀 키 만들기” 버튼을 클릭하세요. 마지막으로 새로 생성한 API 키에 이름을 지정합니다.
OpenAI에 의한 API 키 생성은 판다AI와 OpenAI를 연결하기 위해 필요하며, 이 키에 접근할 수 있는 개인이 사용자를 대신하여 OpenAI에 요청할 수 있으므로 안전하게 보관해야 합니다. 결과적으로 OpenAI는 이러한 거래에 대해 귀하의 계정으로 비용을 청구합니다.
향후 약간의 수정을 통해 자주 활용해야 하므로, 제공된 코드 스니펫을 필요한 조정 없이 최신 Python 구성에 통합하시기 바랍니다.
import pandas as pd
from pandasai import PandasAI
# Replace with your dataset or dataframe
df = pd.read_csv("/content/housing.csv")
# Instantiate a LLM
from pandasai.llm.openai import OpenAI
llm = OpenAI(api_token="your API token")
pandas_ai = PandasAI(llm)
앞서 설명한 코드는 판다AI뿐만 아니라 판다도 가져옵니다. 그런 다음 데이터 세트를 읽어들입니다. 궁극적으로 OpenAI LLM의 인스턴스를 제작합니다.
정보 통신을 위한 준비가 완료되었습니다.
PandasAI를 사용하여 간단한 작업 수행
pandas_ai(df, prompt='What are the first five rows of the dataset?')
현재 출력은 이전 데이터 세트 개요와 일치하므로 PandasAI가 정확하고 신뢰할 수 있는 결과를 생성한다는 것을 나타냅니다.
카탈로그를 검사하여 포함된 열의 수를 확인합니다.
pandas_ai(df, prompt='How many columns are in the dataset? ')
이 코드는 캘리포니아 주택 데이터 집합에 존재하는 열 수에 해당하는 값 10을 반환합니다.
데이터 집합에서 누락된 데이터의 인스턴스가 있는지 검사합니다.
pandas_ai(df, prompt='Are there any missing values in the dataset?')
PandasAI 모듈이 총\_침실 열에 207개의 누락된 데이터 인스턴스가 있음을 확인했으며, 이는 예상과 일치하는 결과입니다.
PandasAI는 쉽게 수행할 수 있는 광범위한 간단한 작업을 제공하며, 이전에 나열된 작업에만 제한이 없습니다.
PandasAI를 이용한 복잡한 쿼리 수행
PandasAI 라이브러리는 복잡한 데이터 분석 요청도 처리할 수 있습니다. 예를 들어, 주택 데이터 세트로 작업할 때 섬에 위치하고 가격이 10만 달러 이상이며 방이 10개 이상인 주택이 몇 채나 되는지 물어볼 수 있습니다.
pandas_ai(df,prompt= "How many houses have a value greater than 100000,"
" are in an island and total bedrooms is more than 10?")
얻은 결과는 5이며, 이는 판다AI가 생성한 결과와 일치합니다.
데이터 분석가가 복잡한 쿼리를 작성하고 수정하는 데는 상당한 시간이 필요할 수 있습니다. 반대로 원하는 목적만 명확히 이해하고 있다면, 판다스AI를 통해 단 두 줄의 자연어로도 이 작업을 수행할 수 있습니다.
판다AI로 차트 그리기
시각화는 데이터 분석가가 사람이 쉽게 이해할 수 있는 형식으로 정보를 제시할 수 있게 해주기 때문에 모든 데이터 분석 절차에서 필수적인 요소입니다.판다AI 라이브러리에는 데이터 프레임을 전달하고 원하는 구성을 지정하여 차트를 생성할 수 있는 기능이 포함되어 있습니다.
데이터 세트 내의 각 열에 대한 히스토그램을 구성하는 것으로 시작하면 다양한 특징의 분포를 파악할 수 있습니다.
pandas_ai(df, prompt= "Plot a histogram for each column in the dataset")
데이터를 추가로 분석한 결과, 청소년의 소셜 미디어 사용과 우울증 사이에는 양의 상관관계가 있는 것으로 확인되었습니다.
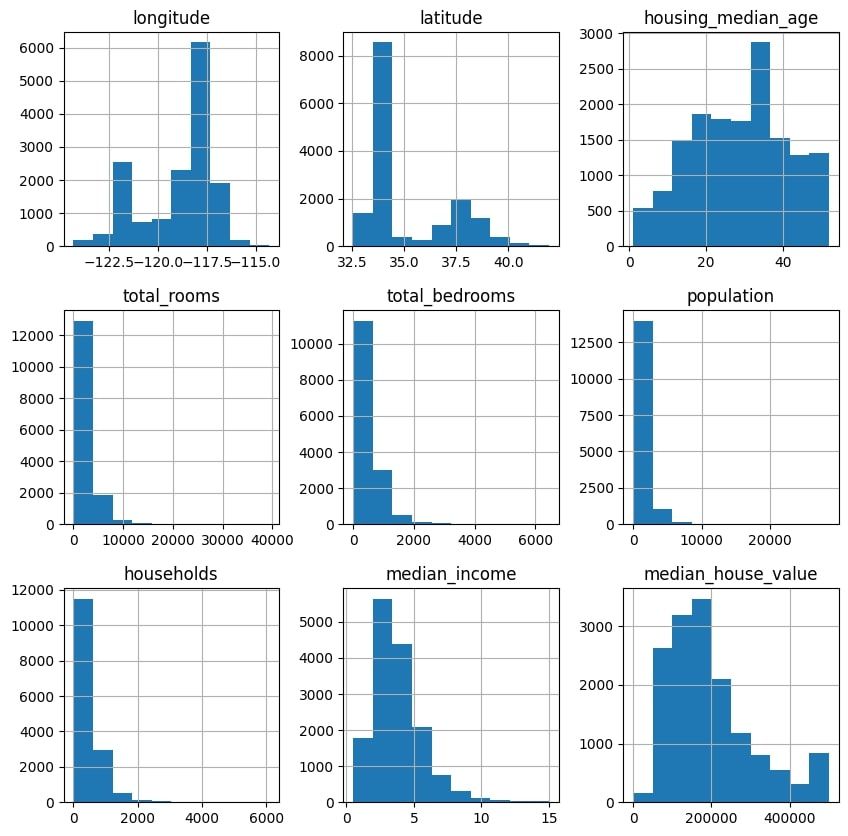
판다AI 알고리즘은 열 이름에 대한 특정 입력 없이도 데이터의 각 열에 대한 히스토그램을 자동으로 생성하는 기능을 보여주었습니다.
판다AI 라이브러리는 미리 정의된 도표 세트를 사용하여 시각화를 자율적으로 생성하는 기능을 보유하고 있으며, 특정 도표가 지정되지 않은 경우 제공된 데이터를 기반으로 적절한 도표를 선택합니다. 예를 들어, 주택 데이터 세트 내의 정보 간의 상관관계를 파악하고자 하는 경우 다음과 같은 쿼리를 통해 의도를 전달할 수 있습니다:
pandas_ai(df, prompt= "Plot the correlation in the dataset")
상관관계 행렬은 아래와 같이 PandasAI에 의해 시각화됩니다:
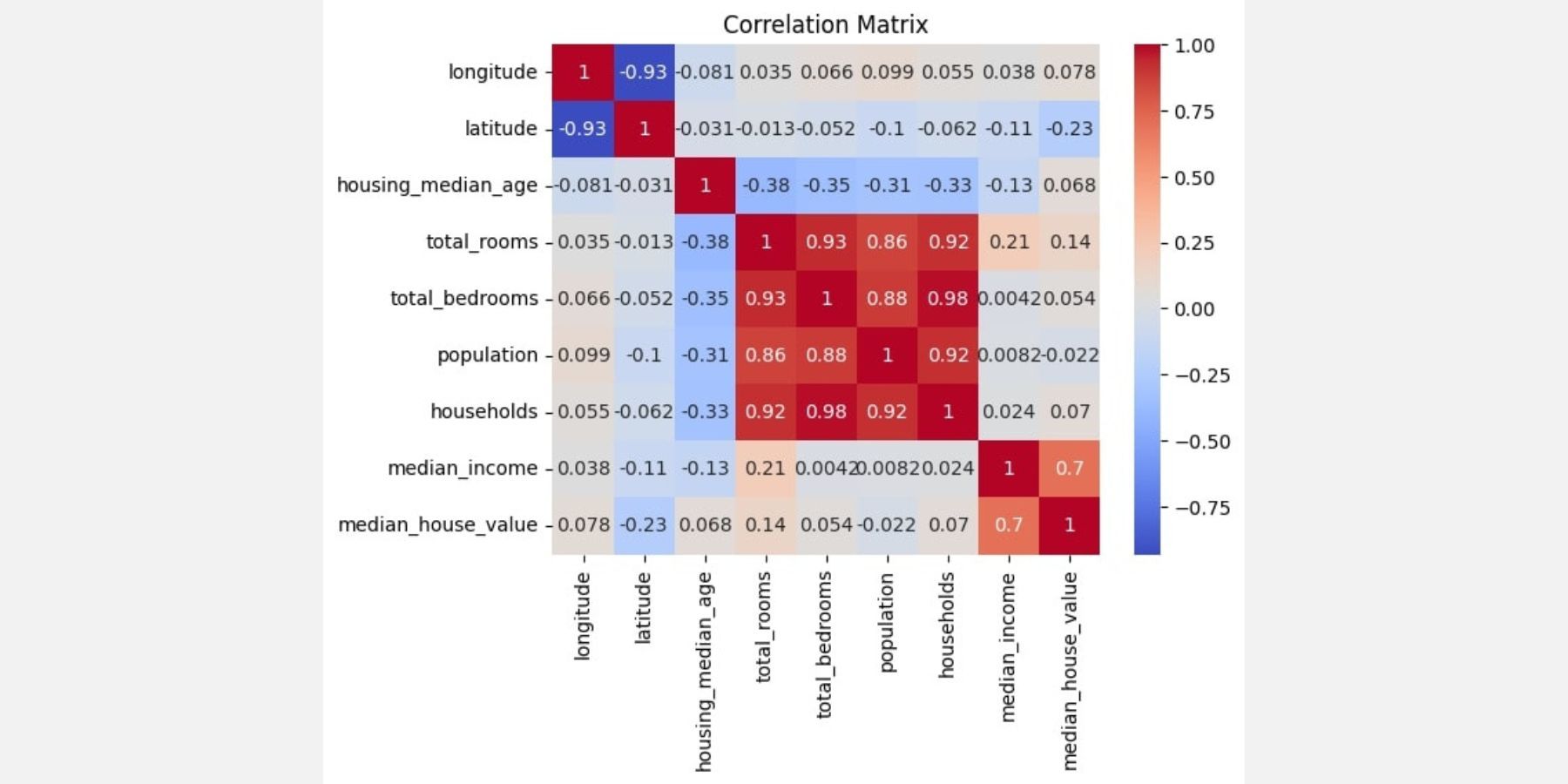
라이브러리는 히트 맵을 선택하여 데이터를 시각화하는 동시에 데이터 세트의 다양한 요소 간의 관계를 추가로 분석할 수 있는 상관관계 행렬을 생성합니다.
여러 개의 데이터 프레임을 판다AI 인스턴스에 전달하기
데이터 분석에서 여러 개의 데이터 세트를 관리하는 것은 특히 초보 사용자에게는 어려운 일이 될 수 있습니다. 이 문제를 해결하기 위해 PandasAI는 데이터에 대한 다양한 연산을 수행하기 위해 적절한 프롬프트와 함께 두 개 이상의 데이터 프레임을 전달하기만 하면 쉽게 결합할 수 있는 직관적인 솔루션을 제공합니다.
판다스 라이브러리를 활용하여 두 개의 개별 데이터 프레임을 생성합니다.
employees_data = {
'EmployeeID': [1, 2, 3, 4, 5],
'Name': ['John', 'Emma', 'Liam', 'Olivia', 'William'],
'Department': ['HR', 'Sales', 'IT', 'Marketing', 'Finance']
}
salaries_data = {
'EmployeeID': [1, 2, 3, 4, 5],
'Salary': [5000, 6000, 4500, 7000, 5500]
}
employees_df = pd.DataFrame(employees_data)
salaries_df = pd.DataFrame(salaries_data)
두 데이터 세트를 모두 PandasAI 인스턴스에 전달하여 두 데이터 프레임을 모두 포함하는 쿼리를 PandasAI에 제출할 수 있습니다.
pandas_ai([employees_df, salaries_df], "Which employee has the largest salary?")
이 프로그램은 실제로 정답인 “Olivia”를 출력합니다.
데이터와 대화하며 손쉽게 분석을 수행할 수 있게 되어 데이터 분석이 더욱 쉬워졌습니다.
판다AI를 구동하는 기술 이해
판다AI를 활용하면 데이터 분석 프로세스가 간소화되어 데이터 분석가의 작업 속도가 빨라지고 데이터 처리 시간이 단축되는 등 상당한 이점을 얻을 수 있습니다.그러나 그 기본 메커니즘은 다소 모호한 상태로 남아 있으며, 근본적인 수준에서 판다AI의 기능에 대한 통찰력을 얻으려면 생성 인공 지능에 대한 포괄적인 이해가 필요합니다. 이러한 지식은 생성 AI의 영역에서 이루어지고 있는 발전에 대해 더 깊이 이해할 수 있게 해줄 뿐만 아니라 이러한 발전을 따라잡을 수 있게 해줍니다.