Hur man använder Scikit-LLM för textanalys med stora språkmodeller
Scikit-LLM är ett Python-paket som hjälper till att integrera stora språkmodeller (LLM) i scikit-learn-ramverket. Det hjälper till att utföra textanalysuppgifter. Om du är bekant med scikit-learn blir det lättare för dig att arbeta med Scikit-LLM.
Det bör erkännas att Scikit-LLM och scikit-learn har olika syften, där det förstnämnda är skräddarsytt för textanalysuppgifter medan det senare fungerar som ett mer omfattande allmänt maskininlärningsbibliotek.
Komma igång med Scikit-LLM
För att komma igång med Scikit-LLM behöver du installera biblioteket och konfigurera din API-nyckel. Installera biblioteket genom att öppna din IDE och skapa en ny virtuell miljö . Detta hjälper till att förhindra eventuella konflikter mellan biblioteksversioner. Kör sedan följande kommando i terminalen.
pip install scikit-llm
Genom att utföra denna instruktion underlättas installationen av Scikit-LLM, tillsammans med alla nödvändiga förutsättningar.
För att kunna konfigurera din API-nyckel för din tjänsteleverantör av Large Language Model (LLM) är det nödvändigt att skaffa en från dem. För de som söker en OpenAI API-nyckel, vänligen följ följande process:
Fortsätt till OpenAI API-sidan . Klicka sedan på din profil i det övre högra hörnet av fönstret. Välj Visa API-nycklar . Detta tar dig till sidan API-nycklar.
För att komma åt sidan med API-nycklar och skapa en ny hemlig nyckel, följ dessa steg på ett sofistikerat sätt:1. Navigera till den angivna webbsidan där API-nycklarna hanteras inom din applikations instrumentpanel eller kontrollpanel. Detta kan vara tillgängligt via huvudmenyn under “Inställningar” eller “Integrationer.“2. När du har öppnat den aktuella sidan letar du upp det avsnitt som är avsett för hantering av API-nycklar. Det är sannolikt placerat nära toppen av sidan eller visas som ett alternativ i en rullgardinsmeny.3. I det här avsnittet, leta efter en framträdande knapp märkt “Skapa ny hemlig nyckel”, som kommer att initiera processen för att generera en ny API-nyckel. Alternativt, om det inte finns någon sådan knapp, sök efter andra uppmaningar eller instruktioner som kan vägleda dig mot
Skapa en API-nyckel genom att klicka på knappen “Skapa hemlig nyckel” för att generera nödvändiga referenser. Det är viktigt att du sedan sparar denna information på ett säkert sätt, eftersom Open AI inte ger möjlighet att hämta den senare. Om du tappar bort nyckeln måste du skapa en ny i dess ställe.
Den fullständiga källkoden finns tillgänglig via aGitHub repository, som ger utvecklare enkel åtkomst och delningsmöjligheter för att samarbeta i projekt och bidra till utveckling av programvara med öppen källkod.
När du har fått din API-nyckel kan du navigera till din önskade IDE (Integrated Development Environment) och integrera modulen SKLLMConfig i Scikit-LLM-biblioteket. Denna integration gör det möjligt att manipulera konfigurerbara parametrar som rör användningen av expansiva lingvistiska modeller.
from skllm.config import SKLLMConfig
Se till att du har angett din Open AI API-nyckel och relevant organisationsinformation för den här kursen, eftersom det är en förutsättning för att den ska slutföras framgångsrikt.
# Set your OpenAI API key
SKLLMConfig.set_openai_key("Your API key")
# Set your OpenAI organization
SKLLMConfig.set_openai_org("Your organization ID")
Organisations-ID och namn är inte samma sak. Organisations-ID är en unik identifierare för din organisation. För att få ditt organisations-ID, gå till inställningssidan OpenAI Organization och kopiera det. Du har nu upprättat en koppling mellan Scikit-LLM och den stora språkmodellen.
Scikit-LLM kräver ett abonnemang på en pay-as-you-go-tjänst, eftersom den begränsade kvot som det kostnadsfria OpenAI-kontot har, med sin begränsning på tre förfrågningar per minut, inte räcker för optimal prestanda med Scikit-LLM.
Användning av ett kostnadsfritt testkonto kan leda till att ett fel som liknar följande meddelande visas när du försöker utföra textanalys.

Om du vill veta mer om hastighetsbegränsningar. Fortsätt till sidan Prisgränser för OpenAI .
Att använda en LLM-plattform innebär inte bara att förlita sig på Open AI; det finns alternativa LLM-tjänsteleverantörer som kan övervägas för dina behov.
Importera de nödvändiga biblioteken och ladda datasetet
Använd biblioteket pandas för att komma åt och bearbeta datasetet. Importera dessutom nödvändiga klasser från både Scikit-LLM och scikit-learn biblioteken.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
Till att börja med importerar och laddar du den datauppsättning som du tänker analysera för textinnehåll. I det här exemplet kommer vi att använda filmdatabasen IMDB som referens, men du kan justera den för att införliva din föredragna datauppsättning.
# Load your dataset
data = pd.read_csv("imdb_movies_dataset.csv")
# Extract the first 100 rows
data = data.head(100)
Du har möjlighet att använda alla data i din datauppsättning, snarare än att vara begränsad till bara de första 100 raderna.
Därefter kommer vi att extrahera funktions- och etikettkolumnerna från vårt dataset, följt av att dela upp det i en träningsuppsättning och en testuppsättning för vidare analys.
# Extract relevant columns
X = data['Description']
# Assuming 'Genre' contains the labels for classification
y = data['Genre']
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Klassificeringskategorin omfattar de beteckningar som är avsedda för förutsägelse, vilket i detta sammanhang betecknas med termen “Genre”.
Zero-Shot Text Classification With Scikit-LLM
Stora språkmodeller har förmågan till zero-shot textklassificering, vilket innebär att kategorisera omärkta data i fördefinierade klasser utan att kräva tidigare träning på märkt information. Detta tillvägagångssätt visar sig vara särskilt fördelaktigt i situationer där texter ska klassificeras i odefinierade kategorier utöver de som övervägdes under modellens utvecklingsfas.
För att utföra en zero-shot textklassificeringsuppgift med Scikit-LLM, kan du använda klassen ZeroShotGPTClassifier.
# Perform Zero-Shot Text Classification
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
# Print Zero-Shot Text Classification Report
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))
Resultatet blir följande:
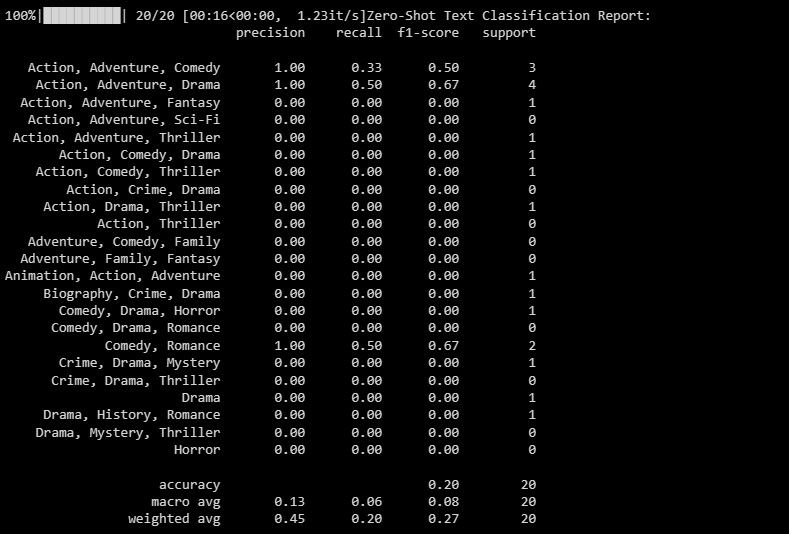
Klassificeringsrapporten erbjuder kvantitativa mätningar för var och en av de etiketter som modellen försöker klassificera.
Multi-Label Zero-Shot Text Classification With Scikit-LLM
I vissa situationer är det inte ovanligt att ett visst textstycke faller under mer än en kategori på en gång. Konventionella klassificeringsmetoder är dåligt utrustade för att hantera sådana fall effektivt. Genom sina avancerade funktioner har Scikit-LLM dock visat sig vara exceptionellt skickligt på att hantera dessa komplexa situationer genom att möjliggöra klassificering av nollbildstext med flera etiketter. Detta tillvägagångssätt innebär att flera beskrivande etiketter fästs på ett ensamt textprov, vilket har stor betydelse för att korrekt fånga och kategorisera information inom olika domäner.
Använd MultiLabelZeroShotGPTCklassificeraren för att fastställa vilken eller vilka etiketter som är tillämpliga på varje givet textutdrag.
# Perform Multi-Label Zero-Shot Text Classification
# Make sure to provide a list of candidate labels
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
# Convert the labels to binary array format using MultiLabelBinarizer
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
# Print Multi-Label Zero-Shot Text Classification Report
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
Ovan fastställer vi de potentiella beteckningar som vår text skulle kunna tilldelas som en utmanare.
Resultatet ser ut som nedan:
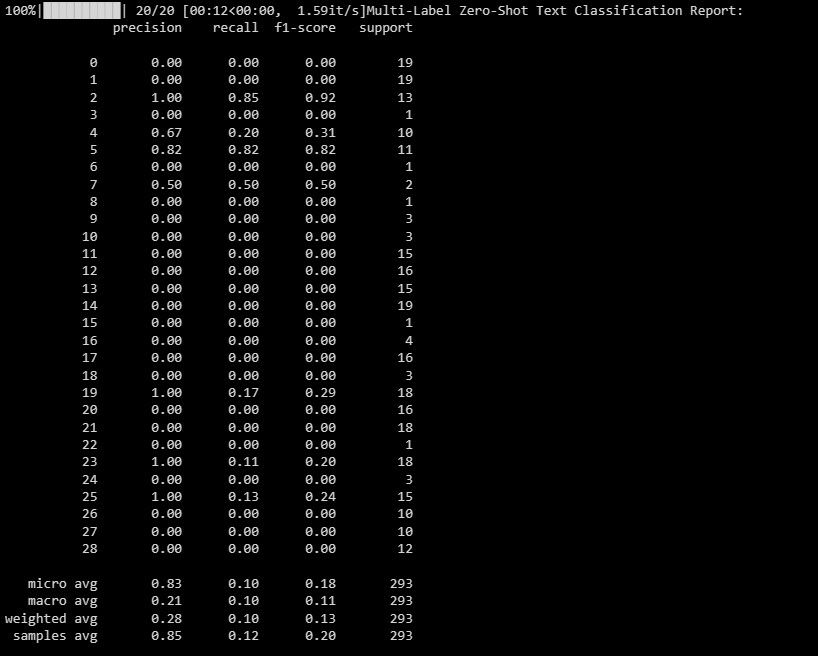
Det här dokumentet belyser hur din modell fungerar för olika etiketter i ett klassificeringsscenario med flera etiketter, och ger värdefulla insikter om hur effektiv den är för varje enskild beteckning.
Textvektorisering med Scikit-LLM
Scikit-LLM tillhandahåller GPTVectorizer, som möjliggör omvandling av textdata till en numerisk form som kan förstås av maskininlärningsalgoritmer genom textvektorisering.Denna omvandlingsprocess innebär att text konverteras till fastdimensionella vektorer med hjälp av GPT-modeller.
Ett sätt att åstadkomma detta är att använda metoden Term Frequency-Inverse Document Frequency.
# Perform Text Vectorization using TF-IDF
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
# Print the TF-IDF vectorized features for the first few samples
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5]) # Change to X_test_tfidf if you want to print the test set
Här är resultatet:
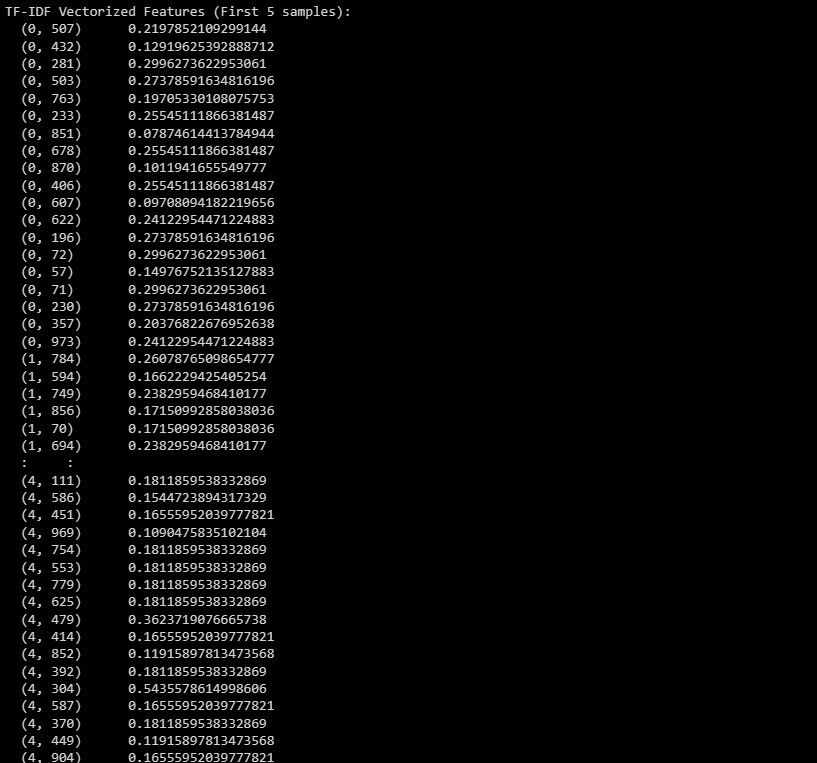
Ovanstående information avser den transformerade funktionsvisa representationen av de första fem instanserna i datasetet, vilket betecknas som TF-IDF-vektoriseringsresultatet.
Textsummering med Scikit-LLM
Textsummering är en process som innebär att man komprimerar ett skriftligt arbete samtidigt som man behåller dess väsentliga innehåll. GPTSummarizer, som finns tillgänglig via Scikit-LLM-biblioteket, använder avancerade språkmodeller baserade på GPT-arkitekturen för att producera kortfattade sammanfattningar av texter.
# Perform Text Summarization
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
Resultatet blir följande:
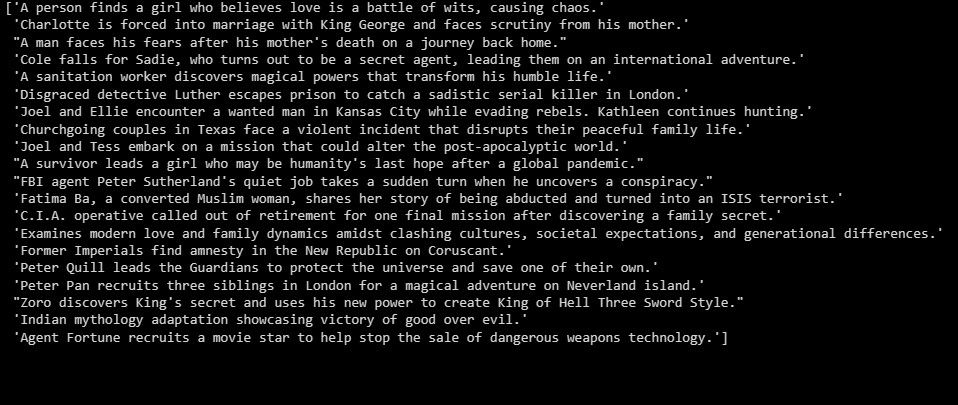
Ovanstående ger en översikt över de experimentella resultaten.
Bygg applikationer ovanpå LLM
Scikit-LLM erbjuder en mängd möjligheter till omfattande granskning av text med hjälp av avancerade språkmodeller. Det är viktigt att förstå grunderna i dessa modellers tekniska underbyggnad, eftersom det underlättar en grundlig förståelse av deras kraftfulla kapacitet och begränsningar, vilket är avgörande för att konstruera högpresterande programvarulösningar baserade på denna toppmoderna innovation.