Hur man bygger en chatbot med Streamlit och Llama 2
Llama 2 är en stor språkmodell med öppen källkod som har utvecklats av Meta. Just den här modellen har imponerande kapacitet, vilket gör den till en formidabel utmanare i jämförelse med andra slutna modeller som GPT-3.5 och PaLM. Faktum är att många experter hävdar att Llama 2 överträffar dessa alternativ när det gäller prestanda. Arkitekturen i denna modell består av tre distinkta förtränade och finjusterade generativa textmodeller, var och en med varierande nivåer av komplexitet. Dessa modeller inkluderar versioner med 7 miljarder, 13 miljarder respektive 70 miljarder parametrar.
Fördjupa dig i Llama 2:s dialogiska potential genom att konstruera en chattbot som använder Streamlit och Llama 2:s funktioner för att interagera med användare i realtid.
Att förstå Llama 2: Funktioner och fördelar
Hur avvikande är Llama 2, den senaste iterationen av den stora språkmodellen, i jämförelse med dess tidigare version, Llama 1?
Den utökade modellen har en betydligt mer omfattande arkitektur som omfattar så många som 70 miljarder parametrar. Ett så stort antal parametrar underlättar inlärningen av alltmer komplexa relationer i ordsekvenser.
Reinforcement Learning from Human Feedback (RLHF) har visat sig vara ett effektivt sätt att förbättra konversationsapplikationer, vilket resulterar i mer naturliga och övertygande svar som kan genereras över ett brett spektrum av komplexa dialoger. Införlivandet av RLHF i dessa modeller förbättrar inte bara deras förmåga att förstå sammanhang utan gör det också möjligt för dem att ge mer sammanhängande och relevanta svar, vilket ger en förbättrad användarupplevelse.
Införandet av den innovativa teknik som kallas “grouped-query attention” har avsevärt påskyndat inferensprocessen och därmed möjliggjort utvecklingen av mycket funktionella applikationer som chatbots och virtuella assistenter.
Den aktuella versionen uppvisar en överlägsen effektivitetsnivå med avseende på både minnesanvändning och beräkningsresurser, jämfört med dess föregående iteration.
Llama 2 är licensierat med öppen källkod och icke-kommersiellt ramverk, vilket gör det möjligt för forskare och utvecklare att använda och modifiera dess funktioner fritt utan några begränsningar eller begränsningar som införs av kommersiella intressen.
Llama 2 uppvisar överlägsen prestanda i olika aspekter jämfört med dess tidigare iteration, vilket gör det till ett exceptionellt robust instrument för många verktyg, inklusive chatbot-interaktioner, virtuella hjälpare och naturlig språkförståelse.
Skapa en strömlinjeformad miljö för utveckling av chatbotar
För att kunna börja bygga din applikation är det nödvändigt att skapa en utvecklingsmiljö som separerar ditt nuvarande projekt från eventuella redan existerande projekt som lagras på din enhet.
Börja med att skapa en virtuell miljö med hjälp av Pipenv-biblioteket på följande sätt:
pipenv shell
Därefter installerar vi de programvarukomponenter som krävs för att bygga upp samtalsagenten.
pipenv install streamlit replicate
Streamlit är ett mångsidigt utvecklingsramverk för webbapplikationer med öppen källkod som är utformat för att underlätta snabb driftsättning av maskininlärning och datavetenskapliga projekt.
I huvudsak hänvisar “Replicate” till en molnplattform som ger användarna tillgång till ett omfattande utbud av maskininlärningsmodeller med öppen källkod som enkelt kan distribueras och användas i olika applikationer.
Hämta din Llama 2 API Token från Replicate
För att få en Replicate token key måste du först registrera ett konto på Replicate med ditt GitHub-konto.
Replicate tillåter endast inloggning via ett GitHub-konto .
När du har öppnat instrumentpanelen går du till fliken “Utforska” och letar upp sökfältet. Ange “Llama 2 chat” i sökfältet för att visa den specifika modellen med namnet “llama-2-70b-chat”.
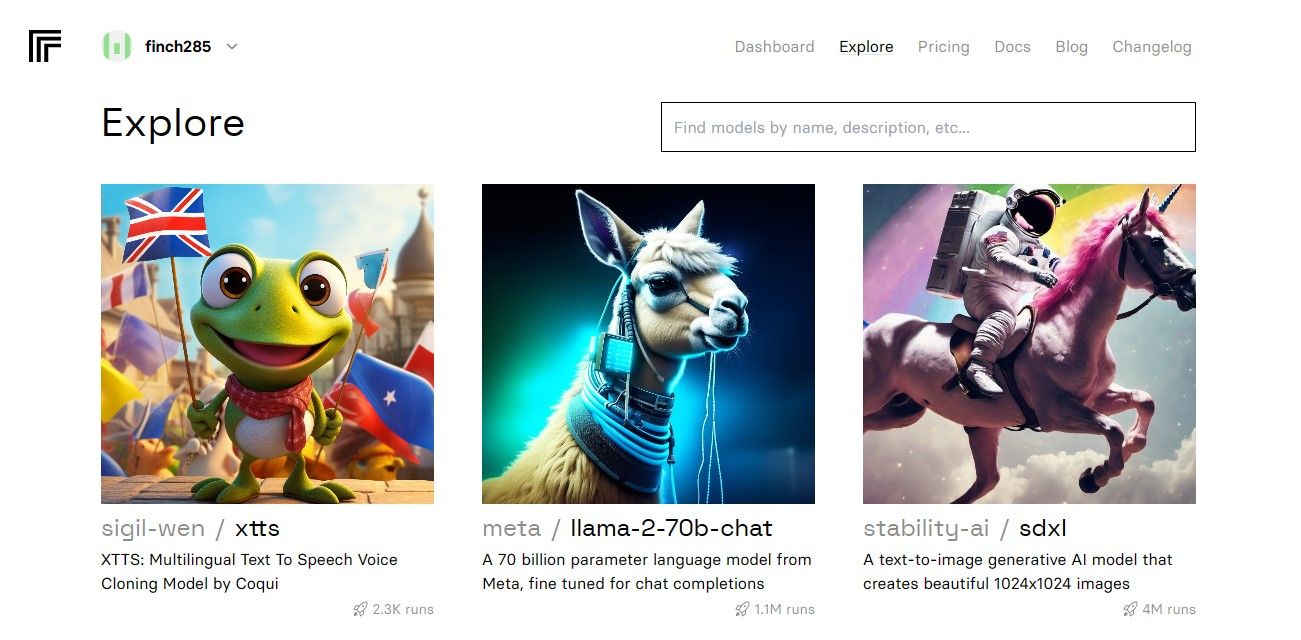
Välj alternativet “Llama 2 API Endpoint” i rullgardinsmenyn och klicka på det. När du har gjort det navigerar du till avsnittet “API Token”. Här hittar du en knapp som heter “Python Application”. Genom att klicka på den här knappen får du tillgång till de nödvändiga autentiseringsuppgifter som krävs för att använda Llama 2 API i dina Python-projekt.
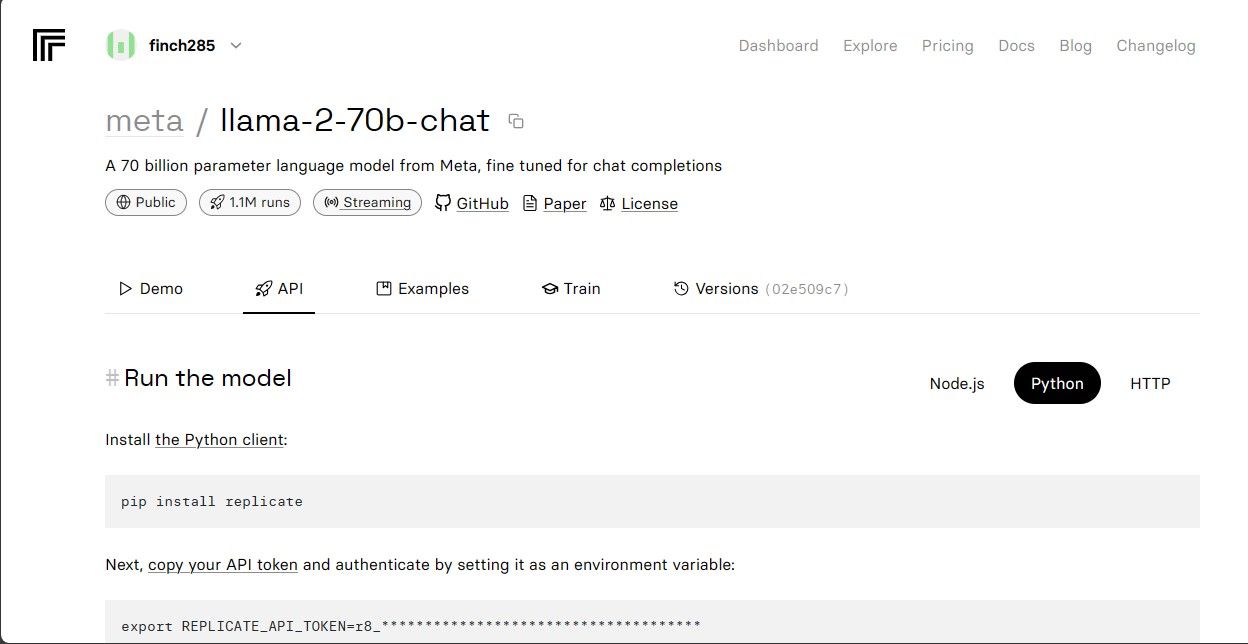
Vänligen kopiera API-token för replikeringssyften och se till att den lagras säkert för framtida användning.
Den fullständiga källkoden finns tillgänglig via vårtGitHub -arkiv, som är en omfattande resurs för utvecklare att använda och bidra till projektet.
Bygga chattboten
För att påbörja utvecklingen av Llama Chatbot ska du först skapa två separata filer - en med namnet “llama\_chatbot.py” som fungerar som det primära skriptet för att implementera chattbotens funktionalitet, och en annan fil med namnet “.env” som är särskilt utformad för att innehålla känslig information som hemliga nycklar och API-token som krävs för korrekt drift. Genom att följa denna inledande konfiguration kan du effektivt isolera känsliga data från den huvudsakliga källkoden och samtidigt säkerställa sömlös integration med externa tjänster.
För att kunna använda olika funktioner i llama_chatbot.py skriptet är det nödvändigt att importera flera bibliotek. Processen för att importera dessa bibliotek innebär att ange deras respektive namn och se till att de är korrekt integrerade med den befintliga kodbasen. Detta möjliggör sömlös drift och utförande av chatbotens avsedda funktionalitet.
import streamlit as st
import os
import replicate
Därefter kommer vi att fastställa de globala parametrarna för språkmodellen “llama-2-70b-chat” genom att initiera dess tillhörande variabler.
# Global variables
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default='')
# Define model endpoints as independent variables
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default='')
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default='')
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default='')
För att införliva Replicate API-token och modellinformationen i programmets miljövariabler bör du lägga till relevant information i filen “.env” med hjälp av en specifik formateringsstruktur. Detta möjliggör en sömlös integrering av dessa komponenter i ditt projekt.
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Replikera det tillhandahållna tokenet och se till att du har sparat motsvarande .env-fil.
Designa chatbotens konversationsflöde
Processen för att initiera användningen av språkmodellen Llama 2 för specifika uppgifter kan underlättas genom att generera en preliminär uppmaning som beskriver det önskade målet. Om målet t.ex. är att använda modellen som assistent, skulle ett lämpligt initieringsuttalande innebära att avsikten specificeras och att eventuella särskilda fokusområden eller domänexpertis som krävs för att uppfylla rollen på ett effektivt sätt beskrivs. Genom att ge tydliga instruktioner i förväg kommer den efterföljande interaktionen med den AI-drivna virtuella assistenten att ske mer effektivt och korrekt.
# Set Pre-propmt
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."
Inställningen av en chatbot-sida kan göras på olika sätt, beroende på önskat utseende och funktionalitet. Några viktiga saker att tänka på är designelement som färgscheman, typsnitt och layoutalternativ. Dessutom är det viktigt att bestämma vilken information eller vilka funktioner som ska visas på sidan, inklusive eventuella interaktiva komponenter som knappar eller formulär. De specifika detaljerna i arrangemanget kan variera beroende på individuella preferenser och krav, men att ha en tydlig plan på plats kan bidra till att säkerställa att slutresultatet uppfyller de avsedda målen och syftena.
# Set initial page configuration
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Initiera och upprätta sessionsspecifika variabelkonfigurationer genom att implementera en funktionell procedur.
# Constants
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
# Session State Variables
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPT
def setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
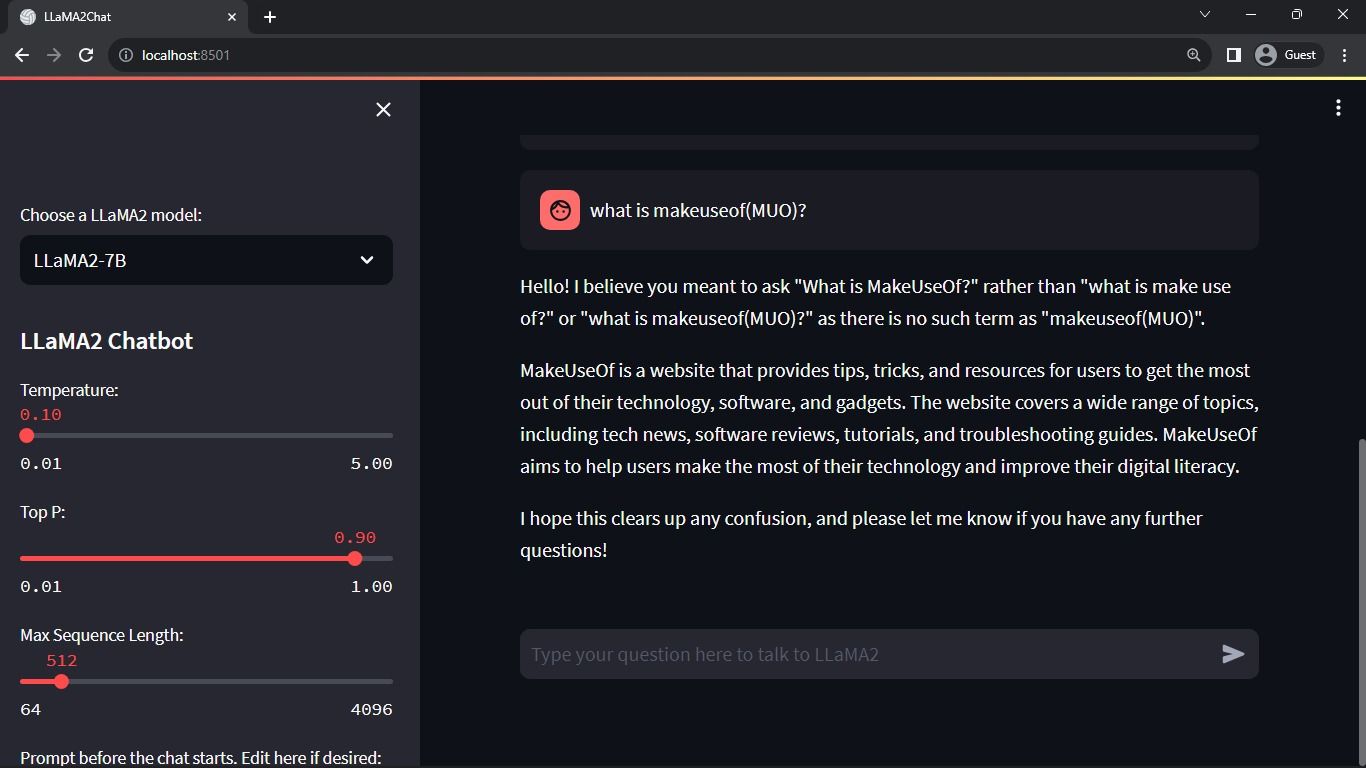
Den ovannämnda processen konfigurerar de avgörande parametrarna, t.ex. chat_dialogue , pre_prompt , llm , top_p , max_seq_len och temperature inom sessionens tillstånd. Dessutom underlättar det valet av Llama 2-modell enligt användarens preferenser.
Här är ett exempel på hur du kan skapa en funktion i Python som renderar sidofältets innehåll för din Streamlit-app:pythondef render_sidebar():# Kod för att generera HTML-kod för sidofältet går hitreturn “Ditt sidofältinnehåll går hit”
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt \\+ "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Den ovannämnda komponenten visar rubriken och konfigurationsparametrarna som kan ändras för att optimera prestandan hos Llama 2 chatbot, vilket underlättar nödvändiga justeringar för optimal funktionalitet.
Här är en möjlig implementering för att återge chatthistoriken i huvudinnehållsområdet i Streamlit-appen med HTML och CSS:pythonimport streamlit as stfrom transformers import GPT2LMHeadModel, GPT2Tokenizerfrom streamlit_chat import message# Ladda finjusterad modell och tokenizermodel = GPT2LMHeadModel.from_pretrained(‘meditations_model’)tokenizer = GPT2Tokenizer. from_pretrained(‘meditations_model’)# Definiera chatbot-funktiondef chatbot(text):input_ids = tokenizer.encode(text, return_tensors=‘pt’)output = modell. generate(input_ids=input_ids, max_length=
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
Metoden går igenom objektet chat_dialogue som lagras i sessionens tillstånd och visar varje kommunikation som utbyts mellan användaren och assistenten, tillsammans med respektive rollidentifierare (antingen “användare” eller “assistent”).
Det medföljande kodavsnittet verkar vara en platshållare för en funktion som bearbetar användarens inmatning, men ingen faktisk implementering ges. För att hantera användarinmatning på ett mer sofistikerat sätt skulle det vara nödvändigt att definiera och implementera en lämplig algoritm eller logik inom funktionen baserat på de specifika kraven i din applikation.
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Presentationskomponenten tillhandahåller ett gränssnitt för textinmatning för användare, så att de kan skicka meddelanden eller frågor inom konversationskontexten. När användarens inmatning tas emot läggs meddelandet till i den pågående dialogen som lagras som en del av de sessionsspecifika data, som inkluderar metadata som anger deltagarens roll som antingen “användare” eller “bot”.
Här är ett exempel på hur du kan implementera denna funktionalitet med Python och Hugging Face Transformers-biblioteket:pythonfrom transformers import LlamaTokenizer, LlamaForCausalLMimport torchdef generate_responses(input_text):# Ladda den förtränade Llama-tokenizern och modellenokenizer = LlamaTokenizer.from_pretrained(‘facebook/llama-base’)model = LlamaForCausalLM. from_pretrained(‘facebook/llama-base’)# Koda in texten som input IDsinputs = tokenizer(input_text, return_tensors=‘pt’).input_ids# Generate
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue \\+= f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue \\+ "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response \\+= item
message_placeholder.markdown(full_response \\+ "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Systemet genererar ett arkiv med tidigare kommunikation, som omfattar både mänsklig och AI-input, innan den uppskjutna replikeringsprocessen anropas. Detta möjliggör en sömlös dialogupplevelse genom att dynamiskt uppdatera gränssnittet med AI:ns senaste svar.
Den primära uppgiften för denna applikation är att rendera alla komponenter inom Streamlit-ramverket, som fungerar som ett omfattande gränssnitt för användare.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Applikationen använder en organiserad sekvens av operationer för att fastställa sessionens status quo, visa sidopanelen, registrera chattar, bearbeta användarinmatningar och producera hjälpsvar med hjälp av alla tidigare definierade funktioner.
Här är ett exempel på hur du kan ändra din funktion main() i index.js så att den använder funktionen renderApp() och startar programmet när skriptet körs:javascriptasync function main() {const app = createContext(null); // Skapa Provider-kontexten med initialvärdet null// Slå in funktionen renderApp med ett try-catch-block för felhanteringtry {renderApp(app, document.getElementById(‘root’));} catch (err) {console.error( Fel vid exekvering av rotkomponenten:\n${err. stack} );}}// Anropa main-funktionen för att köra programmetmain();Den här koden skapar en ny instans av Provider-kontexten genom att skicka null
def main():
render_app()
if __name__ == "__main__":
main()
Ditt program är nu förberett och utrustat för distribution, så att det enkelt kan köras.
Hantering av API-förfrågningar
För att implementera den begärda funktionaliteten är det nödvändigt att skapa en ny Python-modul som heter “utils.py” i projektets huvudkatalog. Denna modul kommer att innehålla en enda funktion som utför den angivna uppgiften. Nedan följer ett exempel på hur detta kan uppnås:pythondef some_function():# Function code goes here…
import replicate
import time
# Initialize debounce variables
last_call_time = 0
debounce_interval = 2 # Set the debounce interval (in seconds)
def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)
current_time = time.time()
elapsed_time = current_time - last_call_time
if elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."
last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt \\+ "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Funktionen innehåller en debouncing-mekanism för att minska risken för alltför frekventa och omfattande API-förfrågningar till följd av en användares interaktion, vilket säkerställer ett försiktigt resursutnyttjande.
Införliva svarsfunktionen debounced i llama_chatbot.py skriptet genom att implementera följande steg:
from utils import debounce_replicate_run
Kör nu applikationen:
streamlit run llama_chatbot.py
Förväntat resultat:
Interaktionen som visas i denna utmatning är en dialog mellan en AI-språkmodell och en mänsklig användare.
Verkliga tillämpningar av Streamlit och Llama 2 Chatbots
Flera exempel på praktisk användning av Llama 2-programvaran kan observeras i olika branscher, t.ex:
Chatbots är ett mångsidigt verktyg som används för att utveckla interaktiva agenter som kan föra diskussioner i realtid om en rad olika ämnen, med hjälp av naturlig språkbehandling och algoritmer för artificiell intelligens för att ge relevanta svar baserat på användarens input.
Detta verktyg innehåller teknik för förståelse av naturligt språk och är utformat för att utveckla konversationsagenter som kan förstå och svara på mänsklig kommunikation på ett sätt som efterliknar mänsklig interaktion.
Användningen av språköversättningsteknik är begränsad till att översätta språk i olika lingvistiska uppgifter.
Sammanfattning av text innebär att en längre text komprimeras till en kortare, mer koncis version som behåller den väsentliga innebörden och de viktigaste punkterna samtidigt som onödiga detaljer utelämnas. Denna process kan vara användbar i olika sammanhang, t.ex. journalistik, forskningsrapporter eller sociala medier, där snabb tillgång till information är avgörande. Genom att endast presentera de viktigaste aspekterna av ett visst ämne kan läsaren på ett effektivt sätt ta till sig de viktigaste idéerna utan att behöva läsa igenom ett helt dokument ord för ord.
Användningen av Llama 2 för forskningsändamål innebär att svara på förfrågningar som omfattar en rad olika ämnen.
Framtiden för AI
Den höga kostnaden för att använda stora språkmodeller som de som finns i GPT-3.5 och GPT-4 har begränsat kapaciteten hos mindre enheter att konstruera anmärkningsvärda tillämpningar av dessa, eftersom det ofta kostar mycket att få tillgång till API:erna för dessa modeller.
Avslöjandet av kraftfulla lingvistiska ramverk som Llama 2 för utvecklingsbranschen markerar inledningen av en ny epok inom artificiell intelligens. Denna händelse kommer att främja uppfinningsrik och fantasifull användning av dessa system i praktiska scenarier och därmed påskynda framstegen mot att uppnå artificiell superintelligens i en snabbare takt.