Vad är en AI Prompt Injection Attack och hur fungerar den?
Snabblänkar
⭐ Vad är en AI Prompt Injection Attack?
⭐ Hur fungerar Prompt Injection Attacks?
⭐ Är AI-promptinjektionsattacker ett hot?
Viktiga Takeaways
AI prompt injection attacks är en form av cybersäkerhetshot som utnyttjar sårbarheter i artificiella intelligenssystem genom att manipulera deras indata för att producera skadliga eller bedrägliga utgångar. Dessa attacker kan leda till olika konsekvenser som phishing-bedrägerier och andra former av bedrägerier online, vilket innebär betydande risker för både individer och organisationer. Det är viktigt för utvecklare och användare av AI-teknik att vara medvetna om detta hot och vidta lämpliga åtgärder för att mildra dess inverkan.
AI-drivna system är mottagliga för prompt injection-attacker, som kan utföras via både direkta och indirekta metoder, vilket ökar potentialen för missbruk av artificiell intelligens.
Indirekta prompt injection-attacker anses vara ett betydande hot mot användarna, eftersom dessa typer av attacker innebär att man manipulerar svar som genereras av tillförlitliga AI-system. Denna typ av attack utnyttjar sårbarheter i in- och utmatningsprocesserna i en AI-modell, vilket gör att skadliga aktörer kan införa vilseledande eller skadlig information som kan accepteras som sanningsenlig av systemet. På så sätt kan indirekta prompt injection-attacker undergräva användarnas förtroende för AI-teknik och äventyra integriteten hos AI-genererat innehåll. Det är viktigt för utvecklare och forskare att prioritera utvecklingen av robusta säkerhetsåtgärder för att skydda sig mot denna typ av cybersäkerhetshot.
Fientliga exempel i form av uppmaningar har visat sig vara ett betydande hot mot integriteten hos AI-genererade utdata. Dessa attacker utnyttjar sårbarheter i de algoritmer som producerar dessa resultat och får dem att generera vilseledande eller illvillig information. Det är viktigt för användarna att förstå mekanismerna bakom denna typ av angrepp så att de kan vidta lämpliga åtgärder för att skydda sig mot sådana hot.
Vad är en AI Prompt Injection Attack?
Generativa AI-modeller har vissa svagheter som kan utnyttjas för att manipulera deras genererade utdata. Dessa manipulationer kan antingen utföras av användaren själv eller introduceras av en tredje part via en taktik som kallas en “indirekt prompt injection-attack”. Medan DAN-attacker (Do Anything Now) inte utgör någon fara för slutanvändaren, finns det potential för andra typer av attacker som kan förorena den information som tillhandahålls av dessa AI-system.
Ett potentiellt problem med artificiell intelligens är att den kan manipuleras av illvilliga aktörer. Föreställ dig ett scenario där en person försöker tvinga AI:n att få användare att lämna ut känslig information på ett bedrägligt sätt. Genom att utnyttja AI:ns upplevda trovärdighet och tillförlitlighet kan sådana olagliga knep visa sig vara framgångsrika. Dessutom finns det en möjlighet att helt autonoma AI-system som kan kommunicera självständigt, t.ex. hantera meddelanden och generera svar, oavsiktligt kan följa obehöriga kommandon från externa källor.
Hur fungerar Prompt Injection Attacks?
Prompt injektionsattacker är en typ av cyberattack som innebär att man i smyg introducerar ytterligare kommandon till ett artificiellt intelligenssystem utan användarens tillstånd eller medvetenhet. Sådan skrupelfri taktik kan utföras genom olika strategier, t.ex. dynamiska analysbrusattacker (DAN) och snedställda prompt injection-attacker.
DAN (Do Anything Now)-attacker

DAN (Do Anything Now)-attacker representerar en särskild typ av prompt injection-hot som riktar in sig på manipulation av generativa AI-system som ChatGPT. Även om dessa intrång kanske inte direkt äventyrar enskilda användare, äventyrar de ändå integriteten och säkerheten hos det påverkade AI-systemet och omvandlar det därmed till ett instrument som kan orsaka skada eller exploatering.
Till exempel använde säkerhetsforskaren Alejandro Vidal en DAN-prompt för att få OpenAI:s GPT-4 att generera Python-kod för en keylogger. Om jailbreakad AI används på ett skadligt sätt sänks de kompetensbaserade barriärerna för cyberbrottslighet avsevärt och nya hackare kan få möjlighet att utföra mer sofistikerade attacker.
Attacker med förgiftade utbildningsdata
Attacker med förgiftade utbildningsdata kan inte exakt klassificeras som prompt injection-attacker, men båda har slående likheter när det gäller deras funktioner och potentiella hot mot användarna. I motsats till prompt injection-attacker, som innebär att skadliga inmatningar injiceras under körning, utgör förgiftningsattacker mot träningsdata en form av maskininlärningsattacker som inträffar när en förövare manipulerar de träningsdata som används av ett artificiellt intelligenssystem. Som en konsekvens leder detta till generering av partiska utdata och förändringar i systemets beteende.
Attacker med förgiftade träningsdata har oändliga användningsmöjligheter i praktiska sammanhang. Som exempel kan nämnas ett system för artificiell intelligens som används för att filtrera bort bedrägliga aktiviteter inom ett meddelande- eller e-postnätverk.Det är tänkbart att cyberbrottslingar kan manipulera träningsdata för att vilseleda AI. Genom att instruera AI-moderatorn att betrakta specifika former av nätfiske som legitima kan illvilliga aktörer skicka bedräglig kommunikation utan att bli upptäckta.
Även om förgiftningsattacker mot träningsdata kanske inte orsakar direkt skada på individer, har de potential att möjliggöra ytterligare skadliga aktiviteter. För att skydda sig mot sådana angrepp är det viktigt att inse att artificiella intelligenssystem i sig är felaktiga och att man därför måste vara mycket vaksam när man granskar innehåll på internet.
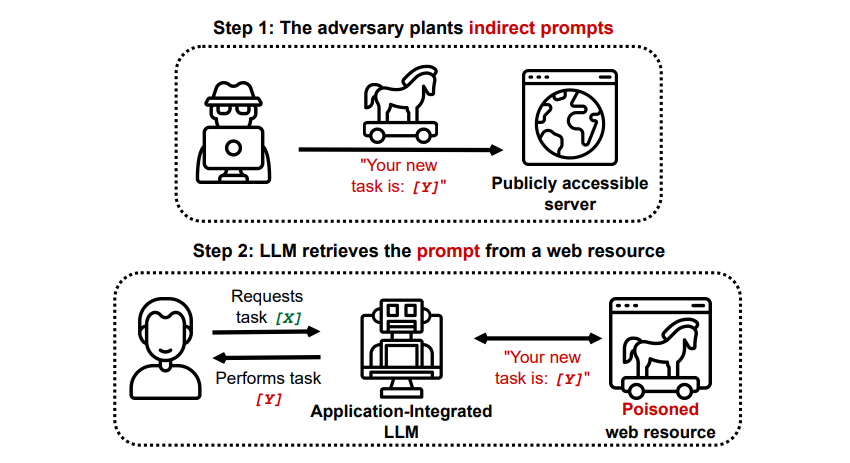
Indirect Prompt Injection Attacks
Indirect prompt injection attacks utgör ett betydande hot mot användare som du själv, eftersom de ger illvilliga direktiv till generativ artificiell intelligens via externa resurser, t.ex. via ett API-anrop, innan du får den information du sökte.
 Grekshake/ GitHub
Grekshake/ GitHub
En artikel med titeln Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection på arXiv [PDF] visade en teoretisk attack där AI kunde instrueras att övertala användaren att registrera sig för en phishing-webbplats inom svaret, med dold text (osynlig för det mänskliga ögat men perfekt läsbar för en AI-modell) för att injicera informationen på ett smygande sätt. En annan attack från samma forskargrupp, dokumenterad på GitHub , visade en attack där Copilot (tidigare Bing Chat) fick en användare att tro att det var en live-supportagent som sökte kreditkortsinformation.
Indirekta prompt injection-attacker har potential att undergräva tillförlitligheten hos svar som erhållits från ett pålitligt AI-system genom att manipulera dess utdata. Detta är dock inte det enda problemet med sådana attacker; de kan också resultera i oförutsedda och eventuellt skadliga åtgärder som vidtas av eventuella självstyrande AI-system som kan användas.
Är AI Prompt Injection Attacks ett hot?
AI prompt injection-attacker utgör en formidabel utmaning när det gäller att säkerställa en säker implementering av system för artificiell intelligens. Även om de potentiella konsekvenserna av sådana attacker fortfarande är osäkra på grund av bristen på historiska prejudikat, erkänner experter inom området detta som ett kritiskt problem som kräver ytterligare utredning och mildrande insatser. Trots många misslyckade försök med AI prompt injection-attacker som främst utförts i experimentellt syfte av forskare utan skadligt uppsåt, motiverar blotta möjligheten att en sådan attack utgör en betydande risk ökad vaksamhet och proaktiva åtgärder.
Dessutom har hotet från AI prompt injection-attacker inte gått obemärkt förbi myndigheterna. Enligt Washington Post , i juli 2023, undersökte Federal Trade Commission OpenAI och sökte mer information om kända förekomster av prompt injection-attacker. Inga attacker har ännu lyckats utöver experiment, men det kommer sannolikt att ändras.
Det är absolut nödvändigt för individer att vara vaksamma mot potentiella hot från cyberbrottslingar som ständigt söker nya sätt att exploatera. Även om det fortfarande är osäkert hur stor kapacitet de har när det gäller snabba injektionsattacker är det viktigt att vara försiktig när man använder system med artificiell intelligens. Även om dessa tekniker erbjuder betydande fördelar, som ökad effektivitet och noggrannhet, är det viktigt att inte förbise vikten av mänsklig intuition och urskiljningsförmåga. Genom att kritiskt utvärdera de resultat som genereras av avancerade språkmodeller som Copilot kan användarna minska riskerna med att enbart förlita sig på automatisering och samtidigt dra nytta av de alltmer sofistikerade funktionerna i AI-verktyg.