Så analyserar du dokument med LangChain och OpenAI API
Att utvinna insikter från dokument och data är avgörande för att kunna fatta välgrundade beslut. När man hanterar känslig information uppstår dock problem med integriteten. LangChain, i kombination med OpenAI API, gör att du kan analysera dina lokala dokument utan att behöva ladda upp dem online.
Genom lokal lagring av data, användning av inbäddningar och vektoriseringar för undersökning, samt utförande av åtgärder inom det egna systemet, upprätthåller OpenAI effektivt integriteten. Det är viktigt att notera att information som kunderna skickar in via deras API inte används för att träna modeller eller förbättra tjänster.
Konfigurera din miljö
Följ dessa steg för att skapa en ny virtuell Python-miljö och installera de nödvändiga biblioteken:Skapa först en ny Python-miljö genom att använda den venv modul som medföljer Python 3.x. Detta förhindrar eventuella kompatibilitetsproblem mellan olika versioner av installerade paket. För att göra detta, öppna din terminal eller kommandotolk och navigera till önskad katalog där du vill skapa den virtuella miljön. Väl där anger du följande kommando:bashpython -m venv myenvErsätt “myenv” med det namn du föredrar för din virtuella miljö. Aktivera sedan den nyskapade miljön med antingen kommandot ./bin/activate (på Windows) eller source bin/activate (på macOS eller Linux). Efter aktiveringen installerar du de nödvändiga biblioteken genom att köra kommandot
pip install langchain openai tiktoken faiss-cpu pypdf
Användningen av varje bibliotek kan sammanfattas enligt följande:
LangChain är ett mångsidigt verktyg som underlättar skapandet och hanteringen av lingvistiska kedjor för olika textbearbetnings- och analysuppgifter. Plattformen erbjuder en rad funktioner som dokumentinläsning, textsegmentering, generering av inbäddning och vektorlagring, allt för att effektivisera din språkrelaterade verksamhet på ett enkelt och effektivt sätt.
Den uppskattade plattformen OpenAI ger användarna möjlighet att utföra förfrågningar och hämta svar från avancerade lingvistiska modeller, vilket ger en värdefull resurs för dem som söker insiktsfull analys eller hjälp.
TikTokoken fungerar som ett verktyg för att kvantifiera antalet tecken i en angiven textmassa, vilket möjliggör en korrekt redovisning av tokenanvändningen under interaktioner med Open AI API, där avgifterna bestäms av mängden text som används.
FAISS är ett effektivt verktyg som gör att du kan skapa och underhålla ett arkiv med vektorrepresentationer, vilket underlättar snabb åtkomst till liknande kodade vektorer genom deras inbäddningar.
PyPDF2 är ett Python-paket som underlättar extrahering av text från PDF-filer (Portable Document Format). Programvaran effektiviserar processen för att ladda PDF-dokument och möjliggör hämtning av deras innehåll för efterföljande manipulation eller analys.
När installationen av alla bibliotek har slutförts är din arbetsyta nu förberedd och utrustad med de verktyg som krävs för att påbörja arbetet.
Skaffa en OpenAI API-nyckel
För att kunna använda de tjänster som tillhandahålls av OpenAI API är det obligatoriskt att inkludera en API-nyckel i din förfrågan. En sådan inkludering gör det möjligt för API-leverantören att bekräfta äktheten hos den begärande parten och samtidigt verifiera om avsändaren har den behörighet som krävs för att få tillgång till de tillgängliga funktionerna.
För att erhålla en OpenAI API-nyckel, gå till OpenAI-plattformen .
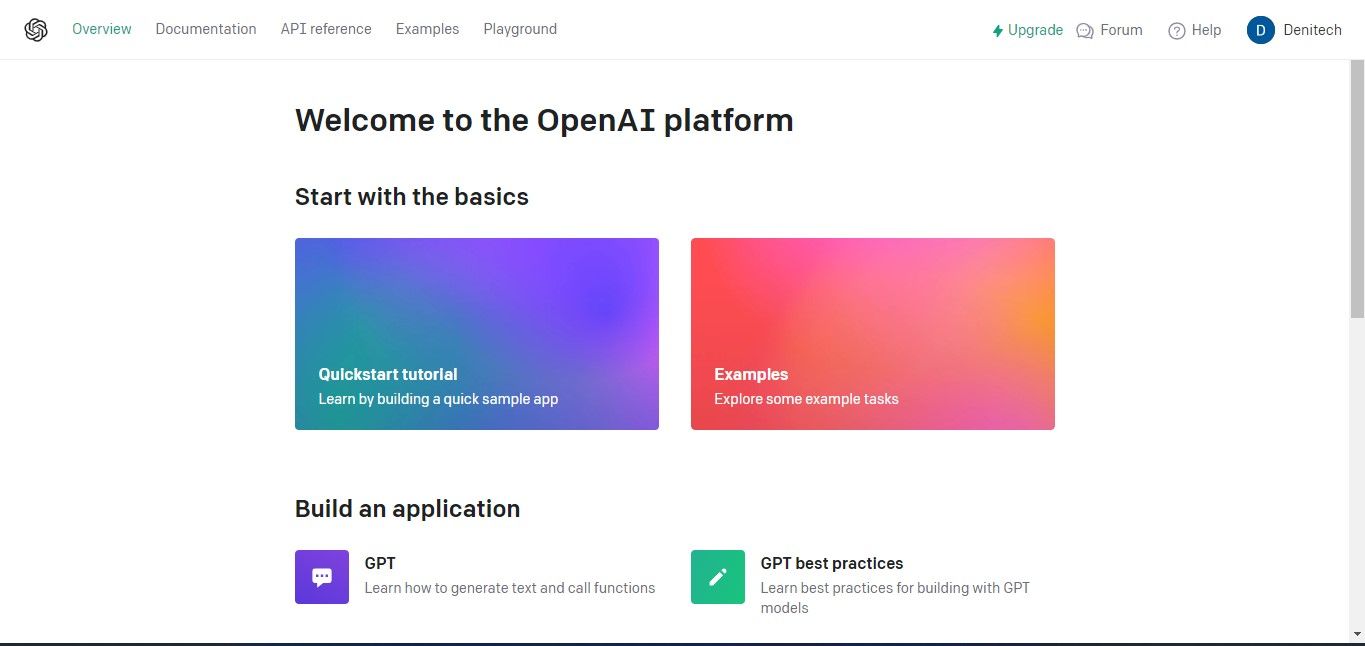
För att få tillgång till API-nycklarna, vänligen navigera till profilavsnittet längst upp till höger på ditt kontos instrumentpanel och välj “Visa API-nycklar”. Denna åtgärd kommer omedelbart att visa API-nyckelsidan för ytterligare hantering.
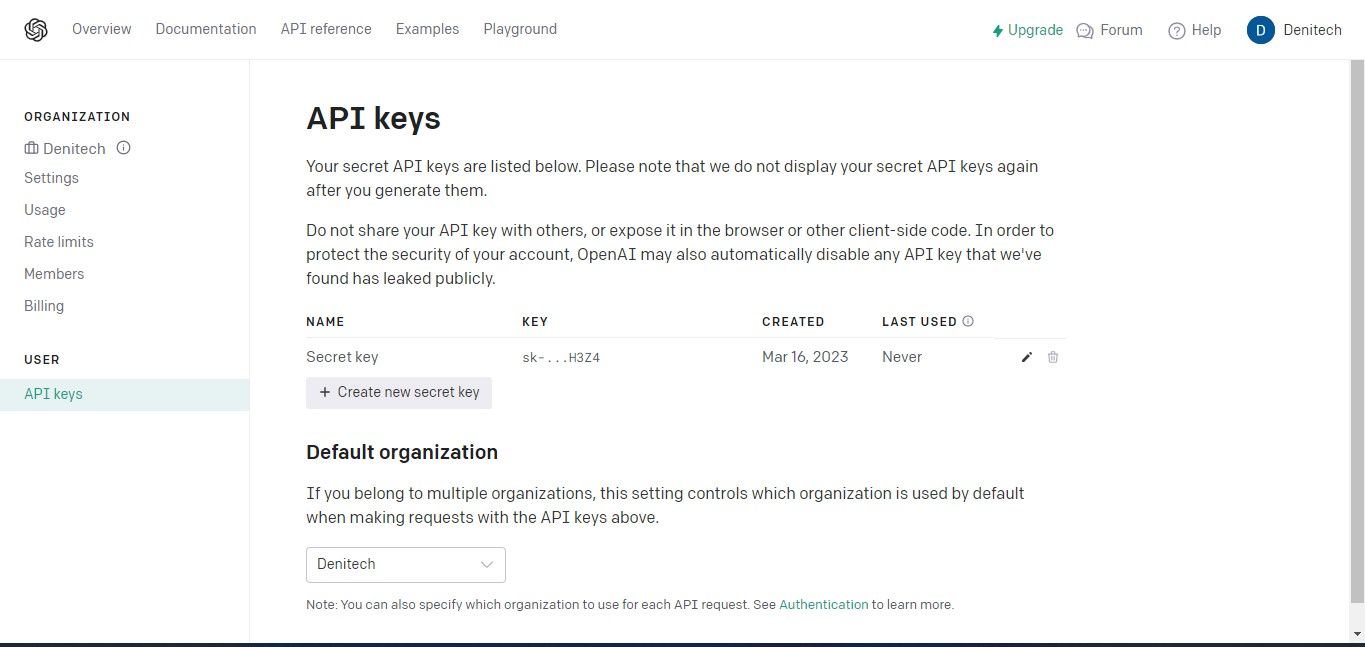
Klicka på knappen “Skapa ny hemlig nyckel” för att påbörja processen med att generera en API-nyckel för din användning med OpenAI. När den har genererats anger du ett namn på nyckeln och klickar sedan på alternativet “Skapa ny hemlig nyckel” för att slutföra skapandet av din nyckel. Det är viktigt att du förvarar den genererade API-nyckeln på ett säkert sätt eftersom den av säkerhetsskäl kanske inte är tillgänglig via ditt OpenAI-konto. Om du förlägger eller förlorar den hemliga nyckeln måste du skapa en ny i dess ställe.
Den fullständiga källkoden kan nås via ett GitHub-förvar, som ger användarna möjlighet att utforska och använda projektets innehåll.
Importera nödvändiga bibliotek
För att en användare ska kunna använda de paket som har installerats i sin virtuella miljö är det nödvändigt att införliva dem genom en importhandling.
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
Vid en granskning av koden framgår det tydligt att processen innebär att importera nödvändiga beroenden inom LangChain-ramverket, vilket ger tillgång till ett omfattande utbud av funktioner som erbjuds av ramverket.
Laddar dokumentet för analys
Till att börja med skapar du en variabel som fungerar som en lagringsplats för din API-nyckel. Denna enhet ska användas senare i skriptet för valideringsändamål.
# Hardcoded API key
openai_api_key = "Your API key"
Vid distribution av kod på produktionsnivå som kan delas med externa enheter är det lämpligt att undvika att införliva känslig information som API-nycklar direkt i källkoden. Istället för att implementera detta tillvägagångssätt erbjuder en miljövariabel en säkrare och mer praktisk lösning för att hantera sådana referenser i ett delat sammanhang.
Visst! Här är ett exempel på hur du kan implementera detta i Python med PyPDF2-biblioteket för att arbeta med PDF-filer och den inbyggda open() funktionen för att läsa vanliga textfiler:pythonimport PyPDF2from io import BytesIOdef load_document(file_path):“““Laddar ett dokument från den angivna filsökvägen.”””# Kontrollera om filen finns innan du försöker öppna ittry:if not file_path.endswith(’.pdf’):# Dokumentet är inte en PDF-fil, så försök att öppna som en textfil iställetwith open(file_path, ‘r’) as f:return f.read()elif file_path.endswith(’.pdf’):
def load_document(filename):
if filename.endswith(".pdf"):
loader = PyPDFLoader(filename)
documents = loader.load()
elif filename.endswith(".txt"):
loader = TextLoader(filename)
documents = loader.load()
else:
raise ValueError("Invalid file type")
När dokumenten har lästs in skapas en instans av CharacterTextSplitter . Denna splitter ansvarar för att dela upp den inlästa dokumentationen i mer hanterbara delar, där varje del bestäms av enskilda tecken.
text_splitter = CharacterTextSplitter(chunk_size=1000,
chunk_overlap=30, separator="\n")
return text_splitter.split_documents(documents=documents)
Bearbetning av innehållet i mindre, sammanhängande segment underlättar effektiv hantering och upprätthåller en viss grad av relevant kontextuell överlappning, vilket visar sig vara fördelaktigt i företag som textanalys och datainhämtningsoperationer.
Sökning i dokumentet
För att extrahera information från det inlämnade dokumentet, utveckla en funktion som accepterar en sökterm tillsammans med en datainhämtningskomponent som indata. Denna funktion kommer att använda den tillhandahållna retrievern tillsammans med en instansiering av Open AI:s naturliga språkmodell för att skapa ett RetrievalQA-objekt.
def query_pdf(query, retriever):
qa = RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),
chain_type="stuff", retriever=retriever)
result = qa.run(query)
print(result)
Den aktuella funktionen använder den instansierade fråge-svarsmodellen för att utföra förfrågan och visa resultatet.
Skapa huvudfunktionen
Huvudfunktionen styr den allmänna utvecklingen av programmet genom att acceptera användarens inmatning av ett dokuments filnamn och därefter ladda det angivna dokumentet. Därefter skapar den en instans av OpenAIEmbeddings som är utformad för ordinbäddningar och bygger ett vektorarkiv baserat på det tidigare bearbetade dokumentet och dess motsvarande ordinbäddningar. Slutligen sparas den uppbyggda vektordatabasen till ett lokalt lagringsmedium i form av en fil.
När persistensskiktet har initialiserats och all nödvändig data har laddats övergår systemet till en iterativ fas där användarna uppmanas att skicka in frågor via ett textgränssnitt. Under denna process delegeras den primära funktionaliteten till metoden query_pdf , som anropas tillsammans med den ansvariga vector repository retriever som erhölls under initialiseringen. Denna cykel fortsätter på obestämd tid tills användaren bestämmer sig för att avsluta sessionen genom att ange ordet “exit”.
def main():
filename = input("Enter the name of the document (.pdf or .txt):\n")
docs = load_document(filename)
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectorstore = FAISS.from_documents(docs, embeddings)
vectorstore.save_local("faiss_index_constitution")
persisted_vectorstore = FAISS.load_local("faiss_index_constitution", embeddings)
query = input("Type in your query (type 'exit' to quit):\n")
while query != "exit":
query_pdf(query, persisted_vectorstore.as_retriever())
query = input("Type in your query (type 'exit' to quit):\n")
Inbäddningar sammanfattar de komplicerade sammankopplingar som finns mellan lexikala objekt och fungerar som en abstrakt representation av skrivet eller talat språk i ett numeriskt format. Med andra ord erbjuder vektorer en metod för att avbilda textpassager genom en serie numeriska värden, vilket möjliggör databehandling och analys av lingvistiska data.
Den aktuella koden omvandlar textinnehållet i dokumentet till vektorrepresentationer med hjälp av de inbäddningar som produceras av OpenAIEmbeddings och indexerar därefter dessa nämnda vektorrepresentationer med FAISS (Facebook AI Similarity Search) för att underlätta snabb hämtning och jämförelse av liknande vektormönster. Detta möjliggör granskning av det inlämnade dokumentet.
Att införliva attributet __name__ med dess motsvarande värde "__main__" är ett viktigt steg för att exekvera huvudfunktionen när skriptet körs som ett fristående program. Genom att använda denna konstruktion möjliggörs sömlös exekvering av den primära funktionen vid användarinteraktion utan att kräva några externa uppmaningar eller ingripanden.
if __name__ == "__main__":
main()
Detta program fungerar som ett terminalbaserat verktyg. Som en förbättring kan man använda Streamlit för att införliva ett grafiskt användargränssnitt för applikationen via Internet.
Utföra dokumentanalys
För att utföra en dokumentanalys, placera det dokument som du avser att undersöka i katalogen för ditt projekt och starta därefter programvaran. Systemet kommer att begära identifiering av det specifika dokument som skall analyseras genom att uppmana dig att ange dess fullständiga beteckning. Ange därefter en rad förfrågningsvillkor som verktyget förväntas behandla under granskningsproceduren.
Den grafiska framställning som tillhandahålls här visar de resultat som erhållits vid bearbetning av en PDF-fil (Portable Document Format), vilket illustreras i den skärmdump som finns under detta uttalande.
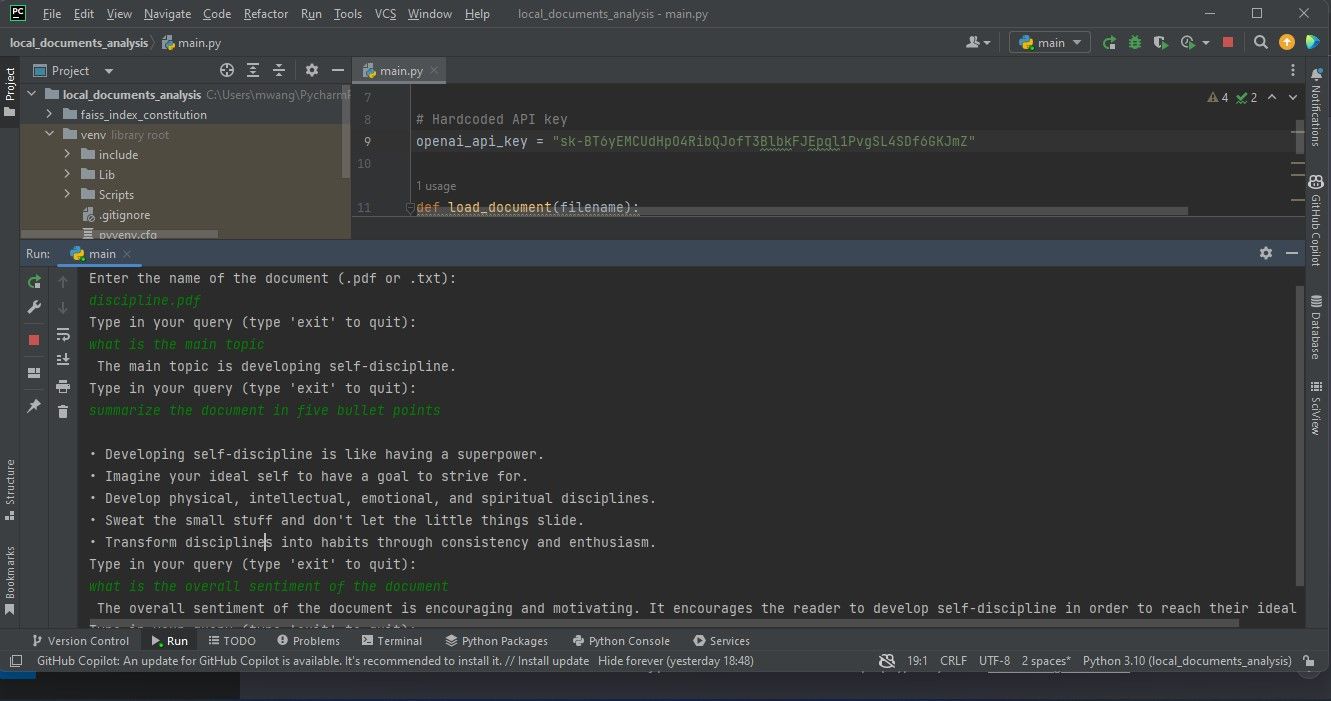
Följande bild visar resultatet av en undersökning av ett dokument som innehåller programmeringskod.
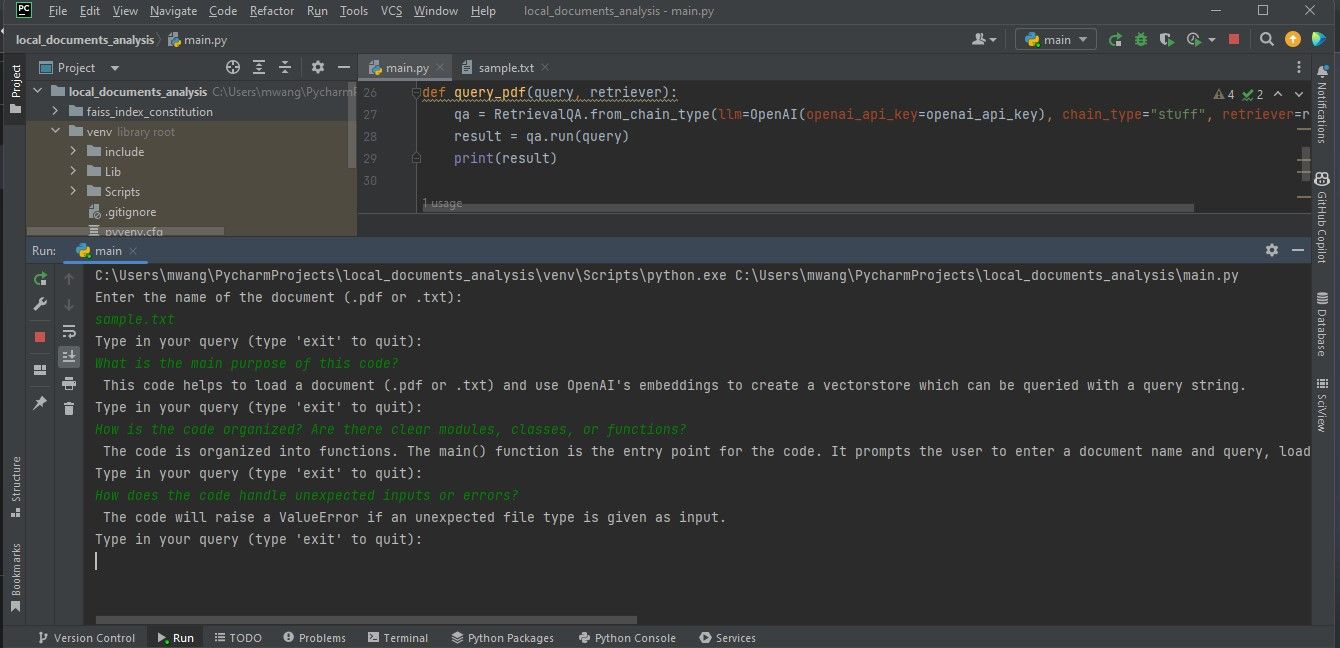
För att säkerställa en korrekt analys av de önskade filerna är det viktigt att de är i antingen PDF- eller textformat. Om dokumenten är i alternativa filtyper finns det olika online-resurser tillgängliga för att konvertera dessa filer till ett lämpligt PDF-format för grundlig undersökning och tolkning.
Förstå tekniken bakom stora språkmodeller
LangChain effektiviserar utvecklingsprocessen för applikationer som använder avancerade funktioner för naturligt språk genom att abstrahera komplexa tekniska detaljer, så att användarna kan fokusera på sin avsedda funktionalitet utan att fördjupa sig för mycket i den komplicerade AI-drivna språkmodelleringen. Det är viktigt att ha en omfattande förståelse för den underliggande tekniken som möjliggör dessa modeller för att fullt ut kunna förstå hur den specifika applikation som utvecklas fungerar.