AI är på väg att ta dina data från sociala medier: Kan du göra något åt det?
Key Takeaways
Samtidigt som det finns en växande oro för integriteten för användarinformation på sociala medieplattformar, har det rapporterats att vissa av dessa plattformar har sålt tillgång till användardata till företag inom artificiell intelligens (AI) för att träna sina generativa AI-modeller. Detta väcker frågor om de etiska implikationerna och potentiella konsekvenserna av sådana handlingar.
Det är känt att ovannämnda plattformar som Meta, Reddit, Tumblr och WordPress.com har deltagit i avtal om licensiering av data för träning av artificiell intelligens.
Användare kan vidta några blygsamma åtgärder för att skydda sin information genom att ändra sekretessinställningar, vägra att dela och vara försiktiga när de publicerar innehåll på internet.
På senare tid har företag inom sociala medier utforskat nya metoder för att kapitalisera på användarinformation genom att ingå avtal med företag inom artificiell intelligens. Det väcker dock frågan om vilka åtgärder vanliga individer kan vidta för att skydda sina personuppgifter och digitala skapelser från att utnyttjas i sådana transaktioner.
Plattformar för sociala medier ingår avtal med AI-företag
Användningen av information från sociala medier för att träna modeller för artificiell intelligens har väckt stor debatt, men det verkar som om företag inom sociala medier inte är villiga att lämna ifrån sig användardata.
Meta har integrerat data från sociala medier i sina generativa AI-funktioner, som introducerades under Meta Connect-evenemanget. Dessa funktioner inkluderar Meta AI och funktioner som att generera AI-drivna emojis för plattformar som WhatsApp.
Som Mike Clark, Director of Product Management på Meta, uppgav i ett Meta Newsroom-inlägg :
De artificiella intelligensmodeller som används i de funktioner som visades under vårt senaste evenemang, känt som Connect, tränades med offentligt tillgängligt innehåll från både Instagram och Facebook, inklusive bilder och medföljande bildtexter.
Denna trend verkar inte sakta ner i Enligt Reuters nådde Reddit ett avtal med Google för att göra den sociala medieplattformens innehåll tillgängligt för träning av AI-modeller.
Reddits S-1-ansökan för dess börsintroduktion, inlämnad den 22 februari 2024, bekräftar att företaget undersöker licensavtal. I ansökan anges följande:
Användningen av Reddit-data har visat sig vara avgörande för utvecklingen av modern teknik för artificiell intelligens, inklusive stora språkmodeller (LLM).Följaktligen förväntar vi oss att Reddits omfattande lagring av konversationsinformation och expertis kommer att förbli avgörande för att förfina och förbättra kapaciteten hos dessa avancerade lingvistiska system.
Reddit har inlett ett program som gör det möjligt för externa enheter att få tillgång till, granska och presentera både tidigare och aktuella data från plattformen, med målet att använda denna information för att förbättra stora språkmodeller (LLM).
Och medan Meta och Reddit är några av de största namnen inom sociala medier, är de inte de enda plattformarna som använder data från sociala medier för att träna AI. Enligt en rapport från 404 Media förbereder sig Tumblr och WordPress.com för att sälja användardata till Midjourney och OpenAI.
Kan du stoppa plattformar från att sälja dina sociala mediedata för AI-utbildning?
Användning av plattformar som Facebook, Instagram, Reddit, Tumblr och WordPress.com kan leda till att ens offentligt tillgängliga innehåll införlivas i utvecklingsprocessen för Language Model Learners (LLMs).
Om du till exempel använder Washington Posts sökverktyg för att se vilka webbplatser som ingick i Googles C4-datauppsättning, som användes som en del av Bards utbildning, ser du att Reddit.com står för 7,9 miljoner tokens.
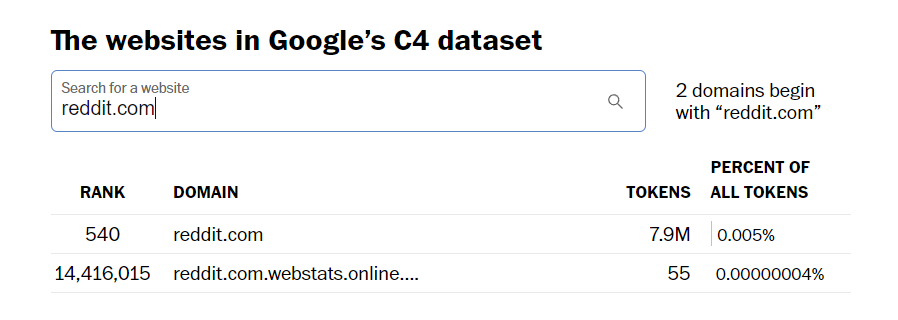
Datauppsättningen omfattar ett stort antal innehållskällor, inklusive Tumblr.com med sin betydande representation på cirka 1,6 miljoner tokens, samt mindre webbplatser som min egen som använder WordPress.com, som bidrar minimalt med endast cirka 14 000 tokens. Det är värt att notera att även dessa blygsamma personliga bloggar ingår i datasetet.
De nya avtalen mellan företag inom artificiell intelligens och sociala nätverk innebär aktiv marknadsföring av sådana data, i motsats till passiv utvinning från onlinekällor.
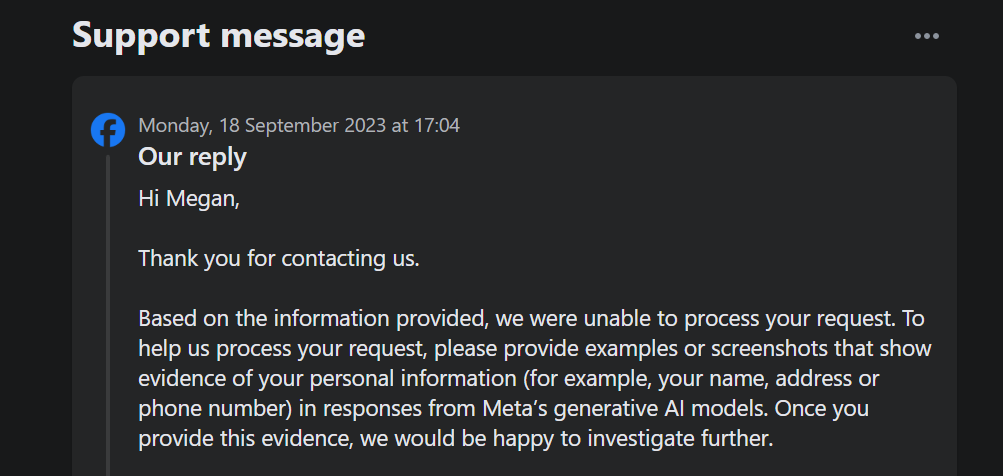
Men när det gäller framtida bearbetning, vad kan du göra åt det? Meta har infört ett formulär för generativa AI-rättigheter för registrerade som gör att du kan invända mot eller begränsa behandlingen av dina personuppgifter från tredje part för att utbilda Metas generativa AI-modeller.
Det är värt att notera att detta alternativ inte tillåter invändningar mot Metas hantering av användardata i syfte att utbilda system för artificiell intelligens. När man försökte lämna in en invändning via det angivna formuläret upptäcktes det dessutom att bevis på att ens personliga information används i Metas AI-utgångar krävdes som en del av supportprocessen.
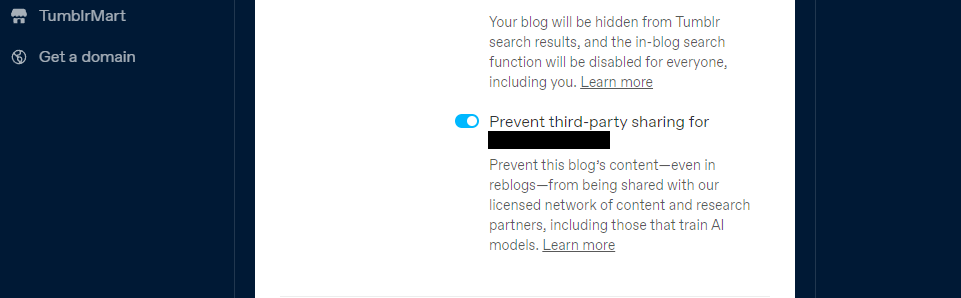
Tumblr erbjuder en lösning som gör det möjligt för användare att neka spridning av sina offentliga blogginlägg till externa enheter genom sin kontokonfiguration. För att komma åt denna funktion, navigera till din profilsida och skrolla ner tills du hittar alternativen för “Synlighet”. Därifrån väljer du det alternativ som förhindrar obehörig delning av din blogg med tredje part.
När du använder plattformar som Instagram är en möjlig strategi att ändra sekretessinställningarna för ditt konto för att begränsa tillgängligheten. Även om denna åtgärd inte ger en absolut garanti för att din information inte kommer att utnyttjas, kan byte till ett privat konto fungera som en formidabel avskräckande faktor med tanke på förekomsten av datainsamlingsmetoder som är inriktade på offentligt tillgängligt innehåll.
Alternativt har du möjlighet att konfigurera ditt Twitter-konto så att det är privat. Det är dock viktigt att notera att denna åtgärd inte ger ett absolut integritetsskydd för dina uppgifter.
Ett gemensamt uttalande av olika nationella informationskommissionärer och experter runt om i världen har också föreslagit några åtgärder för individer som vill minimera integritetsrisken för dataskrapning av AI-företag. Råden omfattar bl.a:
Läs igenom villkoren och sekretesspolicyn för denna webbplats för att förstå dess praxis när det gäller delning av personuppgifter.
När man delar personuppgifter på internet är det viktigt att vara försiktig och återhållsam, särskilt när man lämnar ut känsliga uppgifter.
⭐Hantera dina sekretessinställningar.
När man överväger vilket innehåll man väljer att dela på internet är det viktigt att behålla ett långsiktigt perspektiv och noggrant överväga de potentiella konsekvenserna av sådana avslöjanden i både omedelbar och avlägsen framtid.
Om du misstänker att dina personuppgifter har hämtats utan tillstånd från en social nätverksplattform eller webbplats är det tillrådligt att kontakta respektive tjänsteleverantör för förtydligande. Om du inte är nöjd med deras svar kan du överväga att lämna in ett klagomål till lämplig dataskyddsbyrå.
Du har möjlighet att ta bort specifika uppgifter som potentiellt kan nås av tredje part, även om information som publiceras offentligt på din profil redan kan ha extraherats av andra.
Tyvärr är vanliga användares möjligheter att skydda sina uppgifter från AI-företag begränsade.Den slutliga tillsynen och befogenheten i denna fråga kan kräva ingripande av tillsynsorgan.