Hur man läser och skriver XML-filer med Java
XML-filer kan användas för en mängd olika ändamål, bland annat datalagring. Innan JSON blev populärt var XML det format som föredrogs för att representera, lagra och transportera strukturerad data.
Trots att XML har blivit allt vanligare i modern tid kan man fortfarande stöta på XML då och då. Det är därför viktigt att lära sig att arbeta med detta format. Utforska hur man använder Document Object Model (DOM) Application Programming Interface (API) för att läsa och skriva XML-dokument med Java som ditt primära verktyg.
Krav för XML-bearbetning i Java
Java Standard Edition, eller SE, innehåller Java API for XML Processing, vanligen kallat JAXP, ett omfattande ramverk som omfattar olika aspekter av XML-hantering. Denna omfattande repertoar består av flera integrerade komponenter, bl.a:
Document Object Model (DOM) omfattar en uppsättning klasser som underlättar hantering av XML-komponenter, inklusive element, noder och attribut. Eftersom den är utformad för att läsa in en hel XML-fil i minnet för bearbetning är den dock inte idealisk för att hantera stora dokument på ett effektivt sätt.
Simple API for XML (SAX) är en lättviktig parsningsmekanism som utformats speciellt för hantering av XML-dokument. Till skillnad från DOM (Document Object Model), som bygger upp en hel trädstruktur under bearbetningen, fungerar SAX genom att utlösa händelser baserade på det XML-innehåll som påträffas under parsningen av en fil. Detta tillvägagångssätt minskar minnesförbrukningen och ger större flexibilitet när det gäller hantering av stora datamängder. Att använda SAX kan dock vara något svårare än att använda DOM eftersom det bygger på händelsebaserade programmeringsparadigmer.
StAX, eller Streaming API for XML, är ett nyare tillskott inom XML-bearbetning. Detta kraftfulla verktyg har imponerande prestanda när det gäller filtrering, bearbetning och modifiering av strömmar och lyckas uppnå sina mål utan att XML-dokument behöver laddas in i minnet. I motsats till den händelsestyrda arkitektur som SAX API föredrar, använder StAX en pull-typ-metod som gör det enklare och mer användarvänligt när det gäller kodning.
För att kunna hantera XML-data i en Java-applikation är det nödvändigt att införliva vissa paket som underlättar denna funktionalitet. Dessa paket tillhandahåller olika metoder och klasser för att parsa, manipulera och generera XML-dokument.
import javax.xml.parsers.*;
import javax.xml.transform.*;
import org.w3c.dom.*;
Förbereda ett XML-exempel
För att förstå exempelkoden och begreppen bakom den, använd detta exempel på en XML-fil från Microsoft . Här är ett utdrag:
<?xml version="1.0"?>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications
with XML.</description>
</book>
<book id="bk102">
<author>Ralls, Kim</author>
...snipped...
Läsa XML-filen med DOM API
För att effektivt bearbeta en XML-fil med hjälp av DOM Application Programming Interface (Document Object Model) måste vi först skapa en instans av klassen DocumentBuilder , som underlättar parsningen av XML-dokumentet.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Man kan nu välja att lagra hela dokumentet i sitt minne, med början från XML-rotelementet, som i detta fall motsvarar elementet “catalog”.
// XML file to read
File file = "<path_to_file>";
Document document = builder.parse(file);
Element catalog = document.getDocumentElement();
Genom att använda detta tillvägagångssätt får man fullständig tillgång till hela XML-dokumentet, med början i dess huvudnod, nämligen “catalog”-elementet.
Extrahera information med DOM API
När du har fått fram rotelementet med hjälp av XML-parsern, kan du använda DOM API (Document Object Model) för att få tillgång till värdefull information i det. Ett praktiskt tillvägagångssätt är t.ex. att hämta alla omedelbara efterföljare till rotelementet och iterera genom dem. Observera dock att metoden getChildNodes() returnerar alla typer av barn, inklusive textnoder och kommentarsnoder, som inte är relevanta för vår nuvarande uppgift. Därför bör vi specifikt rikta in oss på endast child-elementen när vi bearbetar dessa resultat.
NodeList books = catalog.getChildNodes();
for (int i = 0, ii = 0, n = books.getLength() ; i < n ; i\\+\\+) {
Node child = books.item(i);
if ( child.getNodeType() != Node.ELEMENT_NODE )
continue;
Element book = (Element)child;
// work with the book Element here
}
För att hitta ett visst child-element under dess parent i ett XML-dokument med C#, kan man skapa en statisk metod som itererar över samlingen av child-noder för att identifiera det önskade elementet baserat på dess namn. Om elementet upptäcks under denna process returneras det, annars blir resultatet null.
static private Node findFirstNamedElement(Node parent,String tagName)
{
NodeList children = parent.getChildNodes();
for (int i = 0, in = children.getLength() ; i < in ; i\\+\\+) {
Node child = children.item(i);
if (child.getNodeType() != Node.ELEMENT_NODE)
continue;
if (child.getNodeName().equals(tagName))
return child;
}
return null;
}
Observera att DOM API klassificerar textinnehållet i ett element som en enskild nod av kategorin TEXT\_NODE. Textinnehållet kan bestå av flera sammanhängande textnoder, vilket kräver särskild hantering för att hämta texten för ett visst element:
static private String getCharacterData(Node parent)
{
StringBuilder text = new StringBuilder();
if ( parent == null )
return text.toString();
NodeList children = parent.getChildNodes();
for (int k = 0, kn = children.getLength() ; k < kn ; k\\+\\+) {
Node child = children.item(k);
if (child.getNodeType() != Node.TEXT_NODE)
break;
text.append(child.getNodeValue());
}
return text.toString();
}
Med hjälp av de medföljande verktygsfunktionerna kan vi undersöka ett exempel som extraherar relevanta data från ett XML-dokument som representerar en katalog över böcker.Den efterföljande koden visar omfattande information om varje enskild publikation som finns i katalogen:
NodeList books = catalog.getChildNodes();
for (int i = 0, ii = 0, n = books.getLength() ; i < n ; i\\+\\+) {
Node child = books.item(i);
if (child.getNodeType() != Node.ELEMENT_NODE)
continue;
Element book = (Element)child;
ii\\+\\+;
String id = book.getAttribute("id");
String author = getCharacterData(findFirstNamedElement(child, "author"));
String title = getCharacterData(findFirstNamedElement(child, "title"));
String genre = getCharacterData(findFirstNamedElement(child, "genre"));
String price = getCharacterData(findFirstNamedElement(child, "price"));
String pubdate = getCharacterData(findFirstNamedElement(child, "pubdate"));
String descr = getCharacterData(findFirstNamedElement(child, "description"));
System.out.printf("%3d. book id = %s\n" \\+
" author: %s\n" \\+
" title: %s\n" \\+
" genre: %s\n" \\+
" price: %s\n" \\+
" pubdate: %s\n" \\+
" descr: %s\n",
ii, id, author, title, genre, price, pubdate, descr);
}
Här följer en steg-för-steg-förklaring av koden:
Koden går igenom ynglingarna i avkomman, eller rotkomponenten, som fungerar som en grund för hela strukturen.
För varje enskild barnnod, som motsvarar en viss bok, kontrollerar programmet om dess underliggande datastruktur har egenskapen att vara en ELEMENT\_NODE. Om denna förutsättning inte är uppfylld fortsätter processen till nästa iteration.
Om en underordnad nod av typen ELEMENT\_NODE påträffas i DOM-trädets genomgångsprocess, kommer egenskapen child att tvingas in i en instans av gränssnittet Element .
Den efterföljande exekveringen av programmet innebär extrahering av flera attribut och teckendata som är associerade med ett specificerat bokelement, såsom dess unika identifierare (“id”), författarnamn, titel, genre, pris, publiceringsdatum och beskrivande information. Den extraherade informationen skrivs sedan ut till konsolen med hjälp av metoden System.out.printf() för presentationssyften.
Så här ser utdata ut:
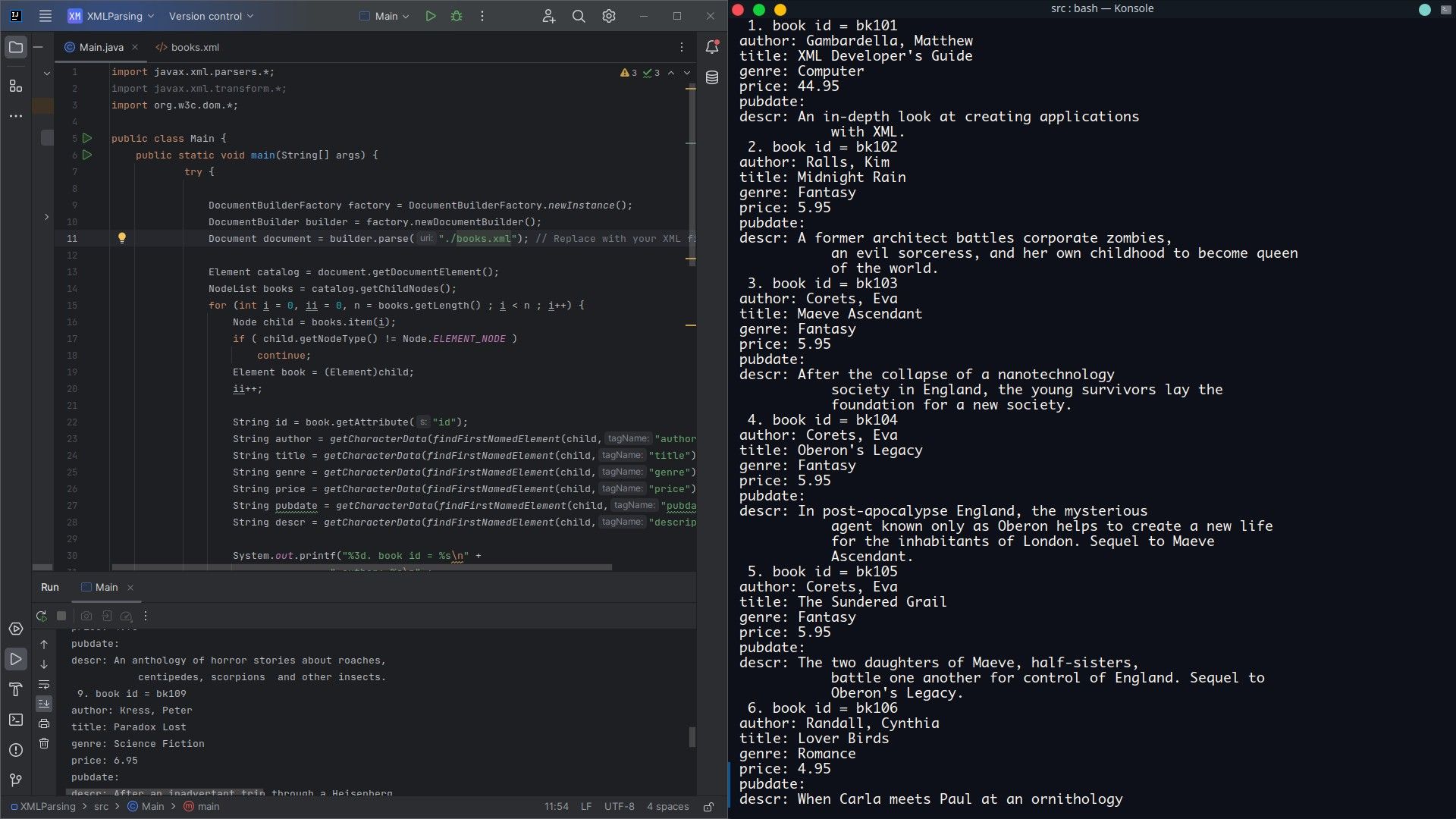
Skriva XML-utdata med hjälp av Transform API
Java erbjuder XML Transformation API som ett sätt att manipulera XML-data. Detta API används tillsammans med identitetstransformationen för att producera utdata. För att illustrera detta kan du tänka dig att utöka den tidigare exempelkatalogen genom att införliva ett nytt bokelement.
Informationen om ett litterärt verk, inklusive författare och titel, kan hämtas från en extern resurs, t.ex. en databas eller en fastighetsfil. Den angivna fastighetsfilen fungerar som en modell för detta ändamål.
id=bk113
author=Jane Austen
title=Pride and Prejudice
genre=Romance
price=6.99
publish_date=2010-04-01
description="It is a truth universally acknowledged, that a single man in possession of a good fortune must be in want of a wife." So begins Pride and Prejudice, Jane Austen's witty comedy of manners-one of the most popular novels of all time-that features splendidly civilized sparring between the proud Mr. Darcy and the prejudiced Elizabeth Bennet as they play out their spirited courtship in a series of eighteenth-century drawing-room intrigues.
För att bearbeta ett XML-dokument är det nödvändigt att använda den parsing-teknik som beskrevs tidigare. Detta innebär att man bryter ner filens textbaserade struktur och extraherar relevant information för vidare analys eller manipulation.
File file = ...; // XML file to read
Document document = builder.parse(file);
Element catalog = document.getDocumentElement();
Med hjälp av klassen Properties i programmeringsspråket Java kan man effektivt hämta och bearbeta information som lagras i en separat extern konfigurationsfil som kallas “properties”-fil. Denna process innebär minimal kodningskomplexitet och effektiviserar integrationen av användardefinierade preferenser eller inställningar med den övergripande applikationslogiken.
String propsFile = "<path_to_file>";
Properties props = new Properties();
try (FileReader in = new FileReader(propsFile)) {
props.load(in);
}
Efter inläsning av egenskapsfilen kan man extrahera de önskade värdena för addition från filen.
String id = props.getProperty("id");
String author = props.getProperty("author");
String title = props.getProperty("title");
String genre = props.getProperty("genre");
String price = props.getProperty("price");
String publish_date = props.getProperty("publish_date");
String descr = props.getProperty("description");
Skapa nu ett tomt bokelement.
Element book = document.createElement("book");
book.setAttribute("id", id);
Att införliva de enskilda komponenterna i boken i textkorpusen är en okomplicerad uppgift. För att underlätta denna process kan man sammanställa en katalog över nödvändiga beteckningar genom att organisera dem i en samling som kallas “Lista”. Genom att utföra en återkommande operation inom denna lista kan respektive post på ett effektivt sätt fogas till den bredare narrativa ramen.
List<String> elnames =Arrays.asList("author", "title", "genre", "price",
"publish_date", "description");
for (String elname : elnames) {
Element el = document.createElement(elname);
Text text = document.createTextNode(props.getProperty(elname));
el.appendChild(text);
book.appendChild(el);
}
catalog.appendChild(book);
Den ovan nämnda katalogkomponenten har för närvarande ytterligare en nyligen introducerad bokentitet. Den enda återstående uppgiften är att formulera det reviderade XML-dokumentet (Extensible Markup Language) som omfattar dessa uppdateringar.
För att kunna generera ett XML-dokument med hjälp av en transformator måste man först skapa en instansiering av transformatorn. Detta kan åstadkommas genom att implementera den nödvändiga koden i ett programmeringsspråk eller en utvecklingsmiljö. I Python kan man t.ex. använda biblioteket transformers och dess tillhörande funktioner för att konstruera en instans av en transformator för användning med uppgifter för bearbetning av naturligt språk.
TransformerFactory tfact = TransformerFactory.newInstance();
Transformer tform = tfact.newTransformer();
tform.setOutputProperty(OutputKeys.INDENT, "yes");
tform.setOutputProperty("{http://xml.apache.org/xslt}indent-amount", "3");
Du kan använda metoden setOutputProperty() för att ange önskad indragningsnivå i den genererade utdatan.
Det sista steget innebär att konverteringsprocessen körs. Resultatet visas genom utdataflödet, vilket kan observeras genom att övervaka konsolen eller terminalen där programmet körs.
tform.transform(new DOMSource(document), new StreamResult(System.out));
För att spara utdata från programmet till en fil istället för att skriva ut det till konsolen, kan man använda följande tillvägagångssätt:
tform.transform(new DOMSource(document), new StreamResult(new File("output.xml")));
För att kunna läsa och skriva XML-filer (Extensible Markup Language) med hjälp av programmeringsspråket Java måste en rad proceduråtgärder utföras sekventiellt. Dessa inkluderar att definiera ett XML-dokumentobjekt, skapa noder i dokumentet, koppla underordnade element till överordnade noder, specificera elementattribut, lägga till eller infoga nya noder på olika positioner i dokumentet, och slutligen stänga alla öppna taggar innan processen avslutas.
Nu vet du hur man läser och skriver XML-filer med Java
Att använda Java för att analysera och manipulera Extensible Markup Language (XML) är en oumbärlig färdighet som man ofta stöter på i praktiska tillämpningar. Document Object Model (DOM) och Transformation API:er är särskilt användbara för detta ändamål.
Att få ett omfattande grepp om Document Object Model (DOM) är oumbärligt för utvecklare som försöker skapa skript på klientsidan för webbaserade applikationer eller webbplatser. Lyckligtvis är DOM:s arkitektur standardiserad för olika programmeringsspråk, vilket möjliggör konsekvent manipulation genom kod som skrivits på språk som Java och JavaScript.