Hur man skrapar data från en webbplats med Google Sheets
Web scraping är en kraftfull teknik för att extrahera information från webbplatser och analysera dem automatiskt. Även om du kan göra detta manuellt kan det vara en tråkig och tidskrävande uppgift. Web scraping-verktyg gör processen snabbare och mer effektiv, samtidigt som de kostar mindre.
Google Sheets har faktiskt förmågan att fungera som en allomfattande lösning för webbskrapningsändamål, med tillstånd av dess inbyggda IMPORTXML-funktion. Denna funktion gör det möjligt för användare att enkelt extrahera information från olika webbplatser, som sedan kan användas för en rad applikationer som dataanalys, rapportering och alla uppgifter som kräver datadriven insikt.
IMPORTXML-funktionen i Google Kalkylark
Med hjälp av den inbyggda funktionen i Google Kalkylark, som kallas “IMPORTXML”, är det möjligt att extrahera information från olika webbkällor, inklusive XML-, HTML-, RSS- och CSV-format. Implementeringen av denna funktion har potential att effektivisera processen för att samla in data från webbplatser utan att kräva omfattande programmeringsexpertis.
Här är den grundläggande syntaxen för IMPORTXML:
=IMPORTXML(url, xpath_query)
URL (Uniform Resource Locator) anger adressen till en viss webbsida som man vill extrahera information från genom webbskrapningstekniker.
XPath-frågan representerar det exakta språk som används för att välja specifik information från ett XML-dokument, som beskriver de önskade data som man vill extrahera däri.
XPath, eller XML Path Language, fungerar som ett navigeringsverktyg för att utforska och extrahera information från XML-dokument, inklusive HTML. Med hjälp av detta språk kan användarna identifiera de specifika platserna för önskade dataelement i en HTML-struktur. Att förstå grunderna i XPath-frågor är avgörande för att effektivt kunna använda IMPORTXML-funktionen.
Förstå XPath
XPath erbjuder en rad funktioner och operatorer som gör det möjligt att manipulera och filtrera data i ett HTML-dokument. Även om det skulle ligga utanför denna artikel att ge en fullständig översikt över både XML och XPath, kommer jag här att presentera flera grundläggande principer för XPath:
Att välja element genom att använda avgränsare som snedstreck ("/") och dubbla snedstreck (//) gör det möjligt att identifiera specifika sökvägar i ett HTML-dokument. Till exempel kommer “/html/body/div” att identifiera alla förekomster av “div”-element som finns i “body”-avsnittet i ett HTML-dokument som finns i katalogen “html”.
För att identifiera och extrahera specifika attribut från en given webbsida kan man använda olika urvalskriterier baserade på namnkonventioner för attribut eller andra identifierbara mönster. Genom att använda en lämplig väljare, som “@href” i detta fall, är det möjligt att rikta in och hämta alla förekomster av “href”-attribut som finns i dokumentet. Detta tillvägagångssätt möjliggör effektiv hämtning av relevant information samtidigt som irrelevant data filtreras bort.
Filtrering av element med hjälp av predikater inom hakparenteser är en mekanism som gör att man kan välja specifika element baserat på vissa kriterier som anges inom hakparenteser. Detta kan göras genom att använda attribut eller klasser av HTML-taggar. Ett exempel skulle vara att välja alla element med attributet class lika med “container” med hjälp av syntaxen /div[@class="container"] .
XPath erbjuder en rad funktioner, inklusive möjligheten att avgöra om ett givet element ingår i ett annat element med funktionen “contains()”, kontrollera om ett elements taggnamn börjar med en angiven sträng med funktionen “starts-with()”, och extrahera textvärdet för ett element med funktionen “text()”. Dessa funktioner gör det möjligt för användare att utföra riktade operationer på XML-dokument baserat på specifika kriterier.
Hur man extraherar XPath från en webbplats
Att extrahera ett elements XPath med IMPORTXML kan vara en utmanande uppgift för dem som är bekanta med funktionens syntax, har kunskap om webbplatsens URL och har identifierat det specifika element som de vill hämta. Processen innebär att man identifierar den unika identifieraren eller attributen som är kopplade till det önskade elementet och sedan använder denna information tillsammans med XPath-formeln för att generera den lämpliga sökvägen till elementet inom webbsidans XML-struktur.
Man behöver inte memorera en webbsidas arkitektur i sin helhet för att få information från den med hjälp av IMPORTXML. I själva verket tillhandahåller varje plattform för webbsurfning ett effektivt verktyg som gör att man enkelt kan återge XPath för ett givet element.
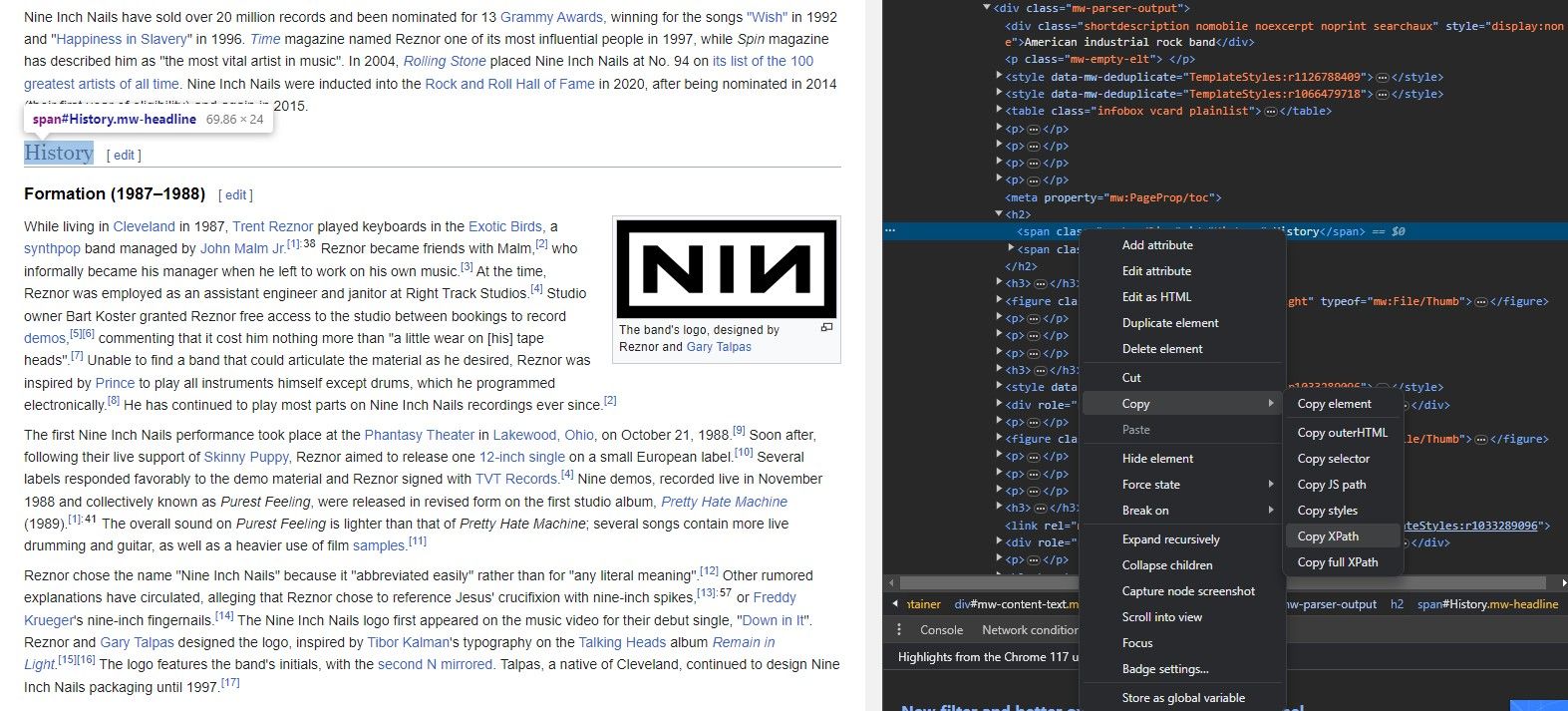
Verktyget “Inspect Element” gör det möjligt att extrahera en XML Path Language (XPath) från olika komponenter på webbsidan med hjälp av en förenklad process, enligt nedan:
Öppna den önskade webbsidan med hjälp av ett internetbaserat program, t.ex. Google Chrome eller Mozilla Firefox.
Hämta önskat dataelement genom att identifiera dess plats i webbsidans källkod med hjälp av ett web scraping-verktyg som Beautiful Soup eller Scrapy.
⭐Högerklicka på elementet.
För att komma åt funktionen “Inspektera element” kan man välja den från snabbmenyn genom att högerklicka på webbsidan och hålla ned musknappen. Detta gör att webbläsaren visar en interaktiv panel som presenterar sidans underliggande HTML-markering, med det specifika elementet i fråga visuellt urskiljbart i denna kod.
Klicka först på det element du vill ändra på din webbsida. Leta sedan upp alternativet “Inspektera” i snabbmenyn som visas när du högerklickar. När detta är gjort väljer du önskat element från listan över element som visas i HTML-koden för vidare redigering eller manipulering.
Klicka på knappen nedan för att generera ett XPath-uttryck för det valda elementet, som sedan enkelt kan kopieras till urklipp.
Nu när vi har fått den nödvändiga informationen kan vi börja med att demonstrera den praktiska tillämpningen av IMPORTXML genom att extrahera URL:er från en given webbsida.
Hur man skrapar länkar från en webbplats med IMPORTXML
Med hjälp av de kraftfulla funktionerna i IMPORTXML kan man extrahera ett omfattande utbud av information från olika webbplatser. Detta omfattar inte bara textinnehåll utan även multimediatillgångar som bilder och videor, samt praktiskt taget alla tänkbara komponenter som finns på webbplatsen. Bland dessa komponenter är hyperlänkar särskilt framträdande eftersom de är viktiga för att förstå strukturen och hierarkin på en webbsida. Genom att granska de destinationer som en viss sida är länkad till kan man få värdefulla insikter om webbplatsens karaktär och fokus.
Genom att använda IMPORTXML i Google Sheets kan man snabbt extrahera webbadresser från webbsidor, vilket underlättar efterföljande analys med hjälp av de många funktioner som finns tillgängliga i plattformen.
Skrapa alla länkar
För att extrahera alla webbadresser som finns på en viss webbsida kan man använda följande metod:
=IMPORTXML(url, "//a/@href")
Det angivna XPath-uttrycket hämtar varje “href”-attribut som är associerat med varje instans av ett “a”-element och isolerar och samlar därmed framgångsrikt alla hyperlänkar som finns på webbsidan.
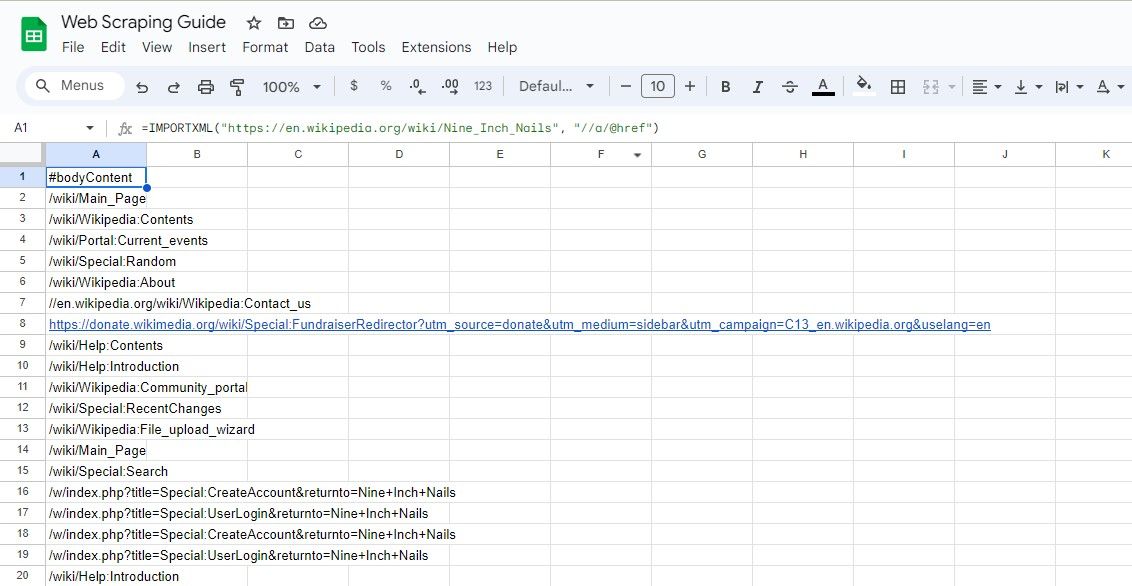
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
Den ovan nämnda algoritmen extraherar varje hyperlänk som finns i en Wikipedia-post.
Att skriva in webbsidans URL i en separat cell och referera till den däri är ett smart tillvägagångssätt, eftersom det hjälper till att hålla formlerna kortfattade samtidigt som man undviker rörighet och komplexitet.En liknande taktik kan användas när man formulerar XPath-frågor för sömlös navigering i samband med dataanalys.
Scraping All Link Texts
För att hämta innehållet i hyperlänkarna utöver deras respektive Uniform Resource Locators kan man använda följande tillvägagångssätt:
=IMPORTXML(url, "//a")
Den aktuella förfrågan omfattar hämtning av alla element, varigenom den extraherade länktexten och tillhörande URL:er kan erhållas från resultatet.
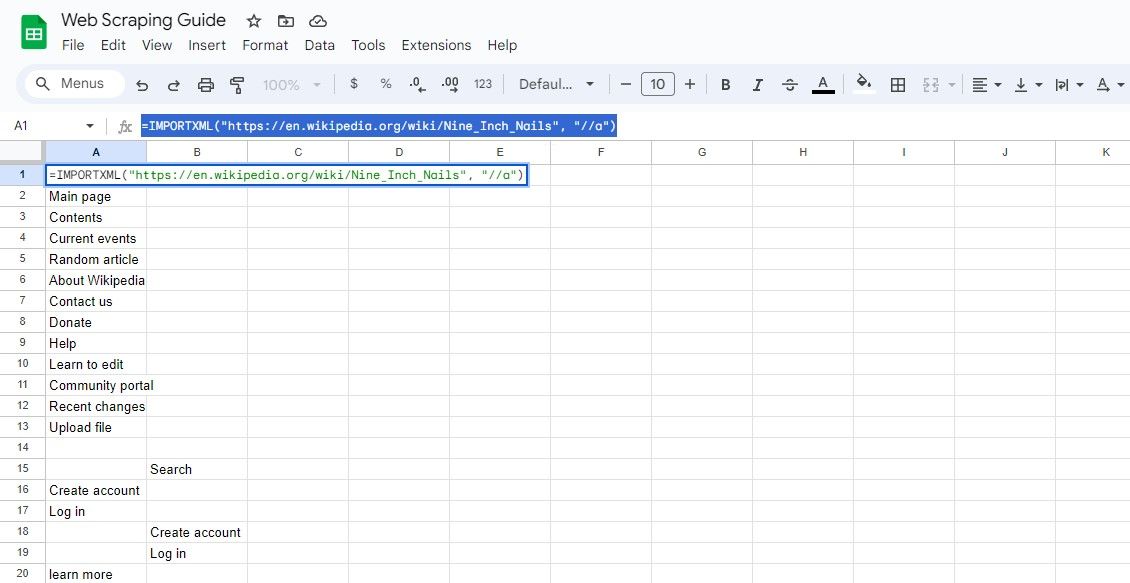
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
Den ovan nämnda formuleringen hämtar ankartexten i den identiska Wikipedia-posten.
Hur man skrapar specifika länkar från en webbplats med IMPORTXML
Ibland är det nödvändigt att hämta webbsidor från vissa webbplatser som innehåller vissa nyckelord eller som ligger inom angivna områden på webbsidan.
Genom att använda XPath kan man exakt identifiera och lokalisera det önskade elementet.
Skrapning av länkar som innehåller ett nyckelord
För att extrahera webbadresser som innehåller ett visst nyckelord med XPath kan man använda funktionen “contains()”:
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
Den angivna frågan hämtar href-värdena för HTML-element vars href-attribut innehåller en specifik sökterm, enligt de angivna kriterierna.
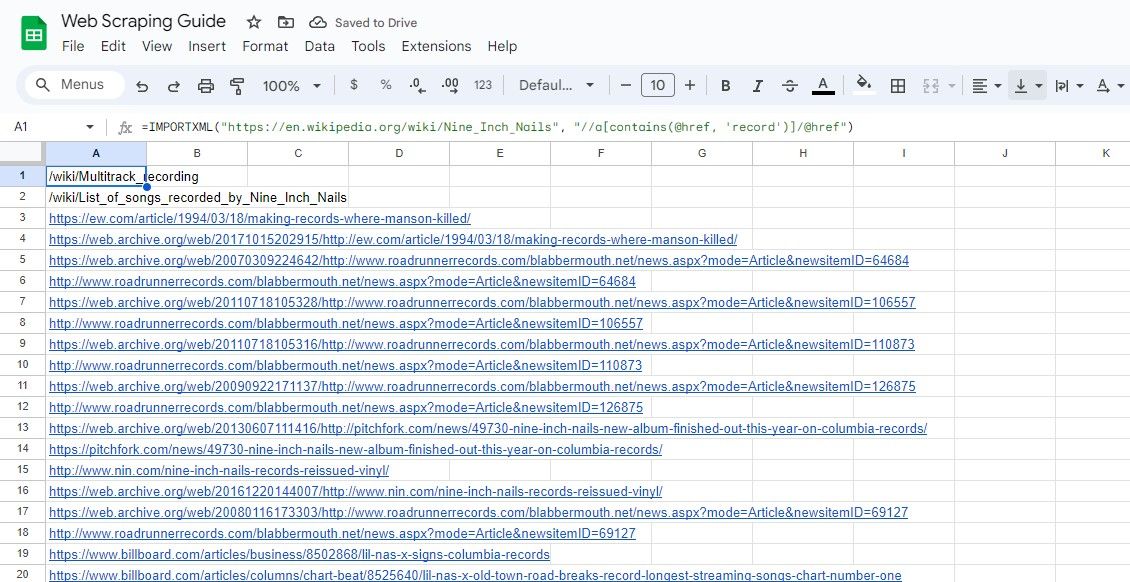
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
Den föregående algoritmen extraherar varje hyperlänk som är inbäddad i en angiven instans av skriftligt innehåll som finns på online-encyklopedin, där termen “record” finns i länkens kropp.
Skrapning av länkar inom ett avsnitt
För att extrahera länkar från en specifik del av en webbsida kan man använda ett XPath-uttryck för att identifiera det önskade avsnittet. Som en illustration kan du titta på följande kodavsnitt:
=IMPORTXML(url, "//div[@class='section']//a/@href")
Den ovannämnda förfrågan gäller valet av hyperlänkattribut som är associerade med HTML-element kategoriserade som “div” och har beteckningen “section”, där nämnda attribut vanligtvis används för att identifiera länkar eller navigera mellan webbsidor, vilket underlättar användarinteraktion på digitala plattformar.
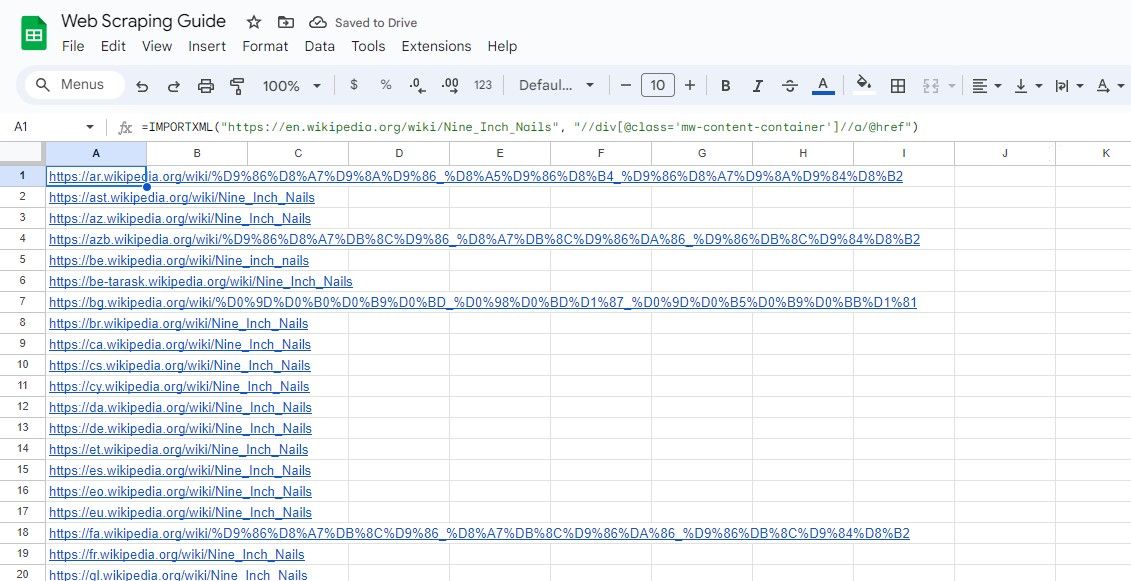
Den ovan nämnda formeln riktar sig till alla hyperlänkar som är inbäddade i ett HTML-element med klassattributet “mw-content-container” och inbäddat i ett containerelement med id-attributet inställt på “mainpage”.
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class='mw-content-container']//a/@href")
Det är viktigt att inse att IMPORTXML:s funktionalitet sträcker sig längre än till enkla web scraping-operationer.Med IMPORT-funktionerna kan användare enkelt importera strukturerade datatabeller direkt till Google Sheets från olika källor på internet. Denna funktion gör det möjligt för användare att effektivt samla in och organisera information utan att behöva manuellt mata in varje enskild del av data.
Även om både Google Kalkylark och Microsoft Excel har en mängd liknande funktioner, är det viktigt att notera att IMPORT-funktionerna är exklusiva för Google Kalkylark. Följaktligen måste alternativa strategier undersökas när man försöker extrahera data från webbkällor till Microsoft Excel.
Förenkla webbskrapning med Google Sheets
Att använda Google Sheets tillsammans med IMPORTXML-funktionen ger en anpassningsbar och tillgänglig metod för att extrahera information från webbsidor, vilket gör det till ett populärt val bland dem som vill samla in data online.
Genom att använda XPath och formulera effektiva frågor med IMPORTXML kan man utnyttja hela dess kapacitet och extrahera ovärderlig information från internetkällor. Genom att initiera datautvinning via web scraping kommer du att höja din förmåga att analysera webben till ett avancerat stadium.