Hur man laddar ner och installerar Llama 2 lokalt
Meta släppte Llama 2 under sommaren Den nya versionen av Llama är finjusterad med 40% fler tokens än den ursprungliga Llama-modellen, fördubblar dess kontextlängd och överträffar avsevärt andra tillgängliga open-sourced-modeller. Det snabbaste och enklaste sättet att få tillgång till Llama 2 är via ett API via en onlineplattform. Men om du vill ha den bästa upplevelsen är det bäst att installera och ladda Llama 2 direkt på din dator.
Med hänsyn till detta har vi utvecklat en omfattande handledning som beskriver processen för att använda Text-Generation-WebUI för att ladda ner och köra en kvantiserad Llama 2 Large Language Model (LLM) på din persondator.
Varför installera Llama 2 lokalt
Att köra Llama 2 direkt kan motiveras av olika faktorer såsom integritetshänsyn, önskan om anpassning och behovet av offline-funktionalitet. Men om man är engagerad i forskning, förfining eller införlivande av Llama 2 i sitt arbete kanske det inte är lämpligt att använda dess API. Det primära syftet med att använda en lokal AI-modell som Llama 2 är att minska beroendet av externa AI-resurser och samtidigt ha flexibiliteten att använda artificiell intelligens när som helst och var som helst utan oro för att läcka potentiellt känslig information till företag och andra enheter.
För att inleda vår diskussion om installationsprocessen för Llama 2 i en lokal miljö ger jag dig en vältalig och detaljerad steg-för-steg-guide för att uppnå denna uppgift framgångsrikt.
Steg 1: Installera Visual Studio 2019 Build Tool
För att effektivisera processen har vi implementerat ett installationspaket med ett enda klick för Text-Generation-WebUI, som används för att gränssnitt med Llama 2 via ett grafiskt användargränssnitt. Det är dock viktigt att du skaffar Visual Studio 2019 Build Tools och installerar de nödvändiga komponenterna innan du fortsätter med installationen av det nämnda paketet.
Ladda ner: Visual Studio 2019 (Gratis)
Du kan få en kopia av vår communityversion av programvaran genom att ladda ner den nu.
⭐ Installera nu Visual Studio 2019 och öppna sedan programvaran. När du har öppnat kryssar du i rutan Desktop development with C\\+\\+ och trycker på installera. 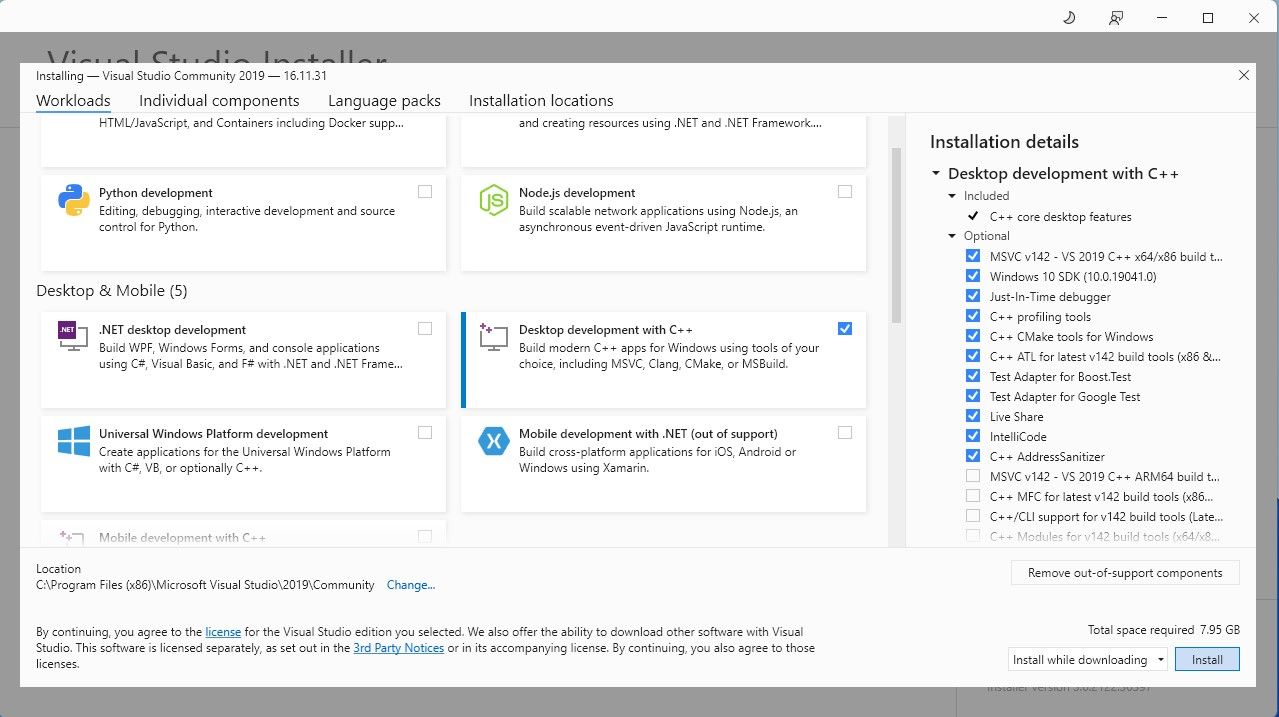
När installationen av Desktop development with C\+\+ är klar fortsätter du med att skaffa Text-Generation-WebUI one-click installer för en sömlös upplevelse.
Steg 2: Installera Text-Generation-WebUI
Installationsprogrammet för Text-Generation-WebUI är ett skript som genom automatisering skapar de nödvändiga katalogerna och konfigurerar Conda-miljön tillsammans med alla förutsättningar för att köra en Artificial Intelligence-modell.
För att få skriptet kan du ladda ner det praktiska installationsprogrammet genom att klicka på “Code” och sedan välja “Download ZIP”.
Ladda ner: Text-Generation-WebUI Installer (Gratis)
När du laddar ner ett ZIP-arkiv kan du välja att packa upp det och spara dess innehåll i en valfri katalog. För att göra detta extraherar du helt enkelt den komprimerade filen genom att öppna mappen som innehåller den, varefter du kan fortsätta att utforska den nyskapade mappen i lugn och ro.
⭐ I mappen bläddrar du nedåt och letar efter lämpligt startprogram för ditt operativsystem. Kör programmen genom att dubbelklicka på lämpligt skript.
Välj ett lämpligt operativsystem och en lämplig plattform för din programvara. Om du använder Windows som operativsystem, följ dessa steg för att konfigurera din programvara med en batchfil:1. Öppna File Explorer och navigera till den katalog där ditt projekt finns.2. Högerklicka på ett tomt område i mappen och välj “Ny” från snabbmenyn.3. Välj “Alla uppgifter” > “Batchfil” för att skapa en ny batchfil. Alternativt kan du trycka på Ctrl \+ Shift \+ B eller högerklicka och välja “Ny batchfil” från snabbmenyn.4. Standardtextredigeraren öppnas med ett tomt dokument. Kopiera och klistra in det medföljande kodavsnittet i dokumentet.5. Spara filen genom att trycka på Ctrl \+ S eller välja “File
⭐för MacOS, välj start_macos shell scrip
⭐ för Linux, start_linux shell script. 
En indikation på att ditt antivirusprogram har upptäckt potentiellt skadlig aktivitet kan visas, men det bör inte vara anledning till oro eftersom det helt enkelt är ett falskt positivt resultat av körningen av en batchfil eller ett skript. För att fortsätta med åtgärden, vänligen klicka på “Kör ändå” för att kringgå eventuella säkerhetsproblem och fortsätta med processen.
⭐ En terminal öppnas och installationen påbörjas. I början kommer installationen att pausa och fråga dig vilken GPU du använder. Välj lämplig typ av GPU som är installerad på datorn och tryck på enter. Om du inte har ett dedikerat grafikkort väljer du Ingen (jag vill köra modellerna i CPU-läge). Tänk på att körning i CPU-läge är mycket långsammare jämfört med att köra modellen med en dedikerad GPU. 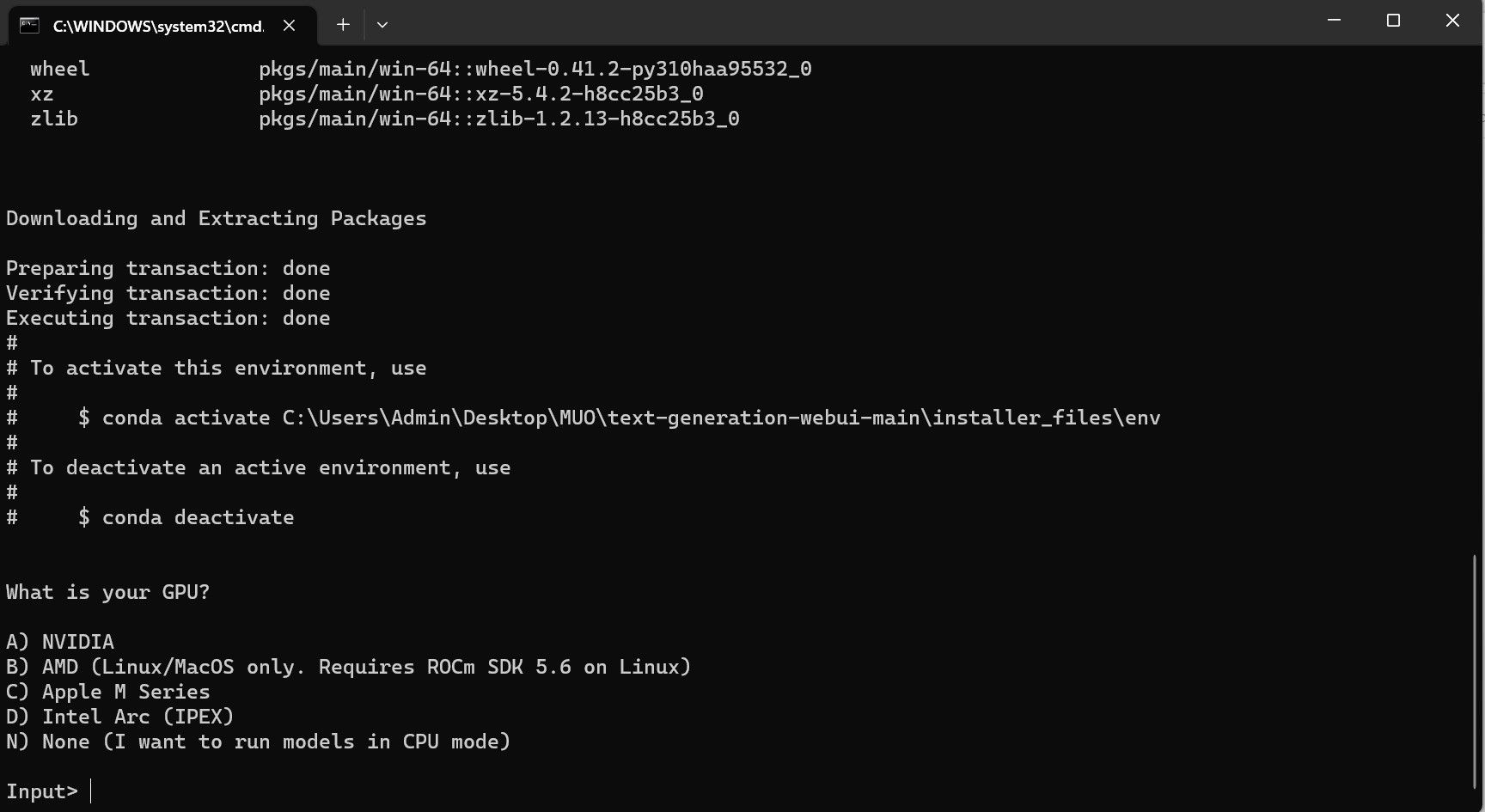
⭐ När installationen är klar kan du nu starta Text-Generation-WebUI lokalt. Du kan göra det genom att öppna din webbläsare och ange den angivna IP-adressen på webbadressen. 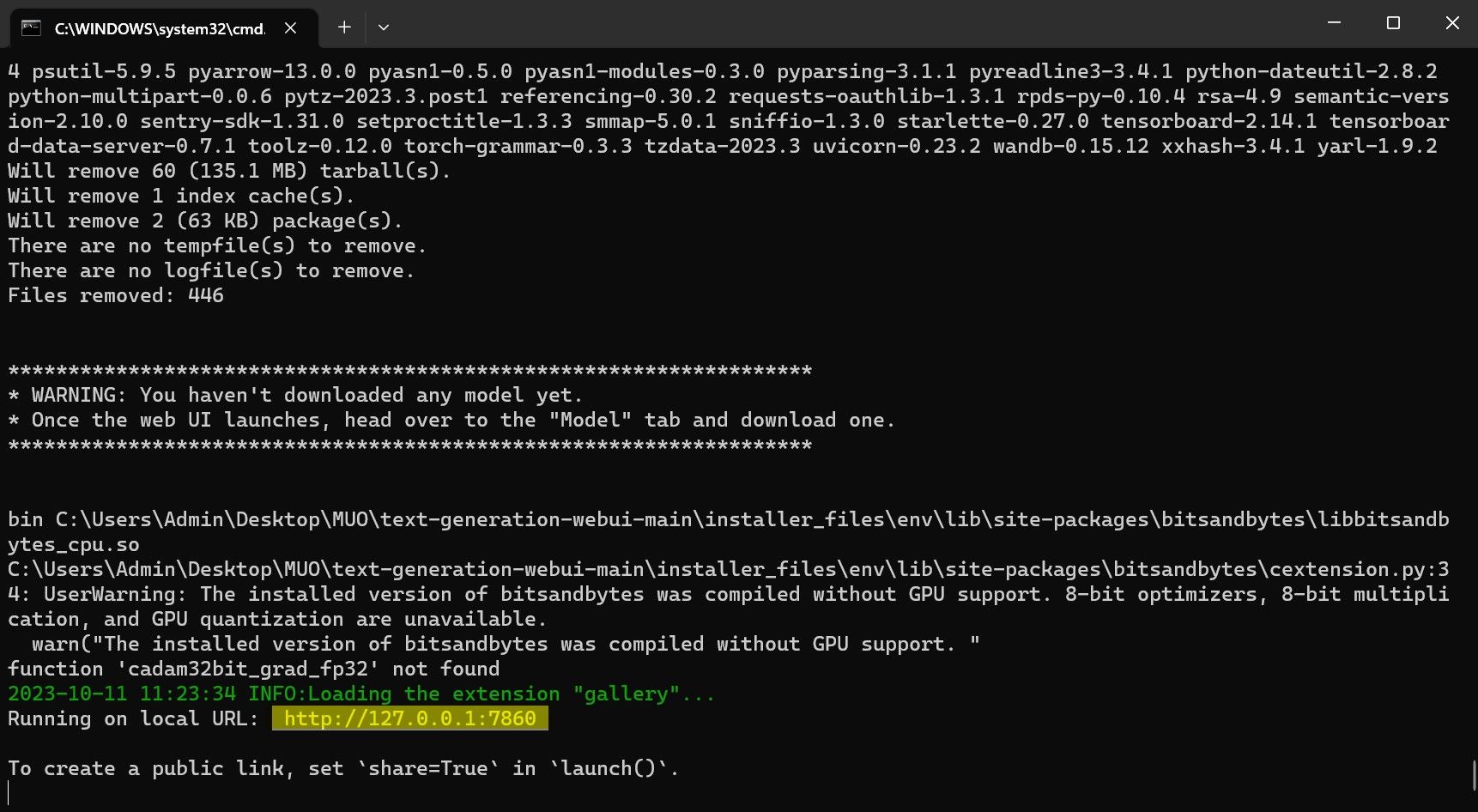
⭐ WebUI är nu klart för användning. 
Även om programvaran fungerar som en model loader, måste du ha Llama 2 för att kunna starta dess funktioner.
Steg 3: Ladda ner Llama 2-modellen
När du väljer en iteration av Llama 2 är det viktigt att ta hänsyn till flera faktorer. Det kan handla om parametrar, kvantisering, hårdvaruoptimering, dimensioner och avsedd användning, som alla kan utläsas av modellbeteckningen.
Storleken på de parametrar som används i träningssyfte kan betraktas som en parameter. I allmänhet resulterar större värden på denna parameter i mer kompetenta modeller, även om en sådan ökning kan komma på bekostnad av effektiviteten.
standard och chatt. Chattvarianten är särskilt anpassad för användning med konversationsagenter som chatbots, medan standardversionen fungerar som standardalternativ.
Processen att optimera hårdvara för effektiv körning av maskininlärningsmodeller kan kategoriseras som hårdvaruoptimering. Det handlar om att bestämma vilken specifik typ av hårdvaruplattform som skulle ge optimal prestanda för en viss modell. Till exempel är GPT-Q utformad och optimerad för att fungera effektivt på dedikerade grafikbehandlingsenheter (GPU), medan GGML fungerar effektivt på centrala processorenheter (CPU). Denna skillnad belyser vikten av att välja lämpliga hårdvarukonfigurationer baserat på de unika kraven för varje respektive maskininlärningsmodell för att uppnå önskade nivåer av prestanda och effektivitet.
Med kvantisering avses processen att minska intervallet eller nivån på de värden som tilldelas vikter och aktiveringar i en maskininlärningsmodell under inferens. Optimering av kvantisering för effektiv beräkning innebär att man anger en specifik precisionströskel, t.ex. q4, som anger en viss detaljnivå eller granularitet i vikt- och aktiveringsvärden.
Termen “Storlek” i detta sammanhang avser dimensionerna eller skalan för en viss modell, vilket kan uttryckas i termer av dess fysiska mått eller andra relevanta måttenheter.
Observera att vissa modeller kan vara strukturerade på olika sätt och kanske inte uppvisar identiska datapresentationsformat. En sådan nomenklatur är dock vanligt förekommande inom

Det aktuella fallet kan beskrivas som en måttligt proportionerad Llama 2-arkitektur, som har tränats med hjälp av 13 miljarder parametrar och anpassats specifikt för samtalsinferens genom användningen av en dedikerad central processorenhet (CPU).
För personer som använder en dedikerad GPU rekommenderar vi att de väljer en GPT-3-modell (GPT-3 Q). Å andra sidan bör användare som förlitar sig på en CPU välja GGML. Om du föredrar att interagera med AI:n på ett sätt som liknar ChatGPT kan du välja alternativet “chatta”. Men om du vill utforska AI: s hela utbud av funktioner, använd standardmodellen. När det gäller inställningar, var medveten om att mer omfattande modeller i allmänhet ger överlägsna resultat men kan leda till minskad effektivitet. Personligen föreslår jag att du börjar med en 7B-modellkonfiguration. När det gäller kvantisering är det viktigt att notera att inställningen “q4” endast är avsedd för inferensändamål och inte för träning eller optimering.
Ladda ner: GGML (Gratis)
Nedladdning: GPTQ (Gratis)
I samband med att du använder en specifik version av Llama 2, vänligen fortsätt att förvärva den önskade modellen för dina behov.
Mot bakgrund av min nuvarande konfiguration som ultrabook-användare tänker jag använda en Generalized Game Model (GG
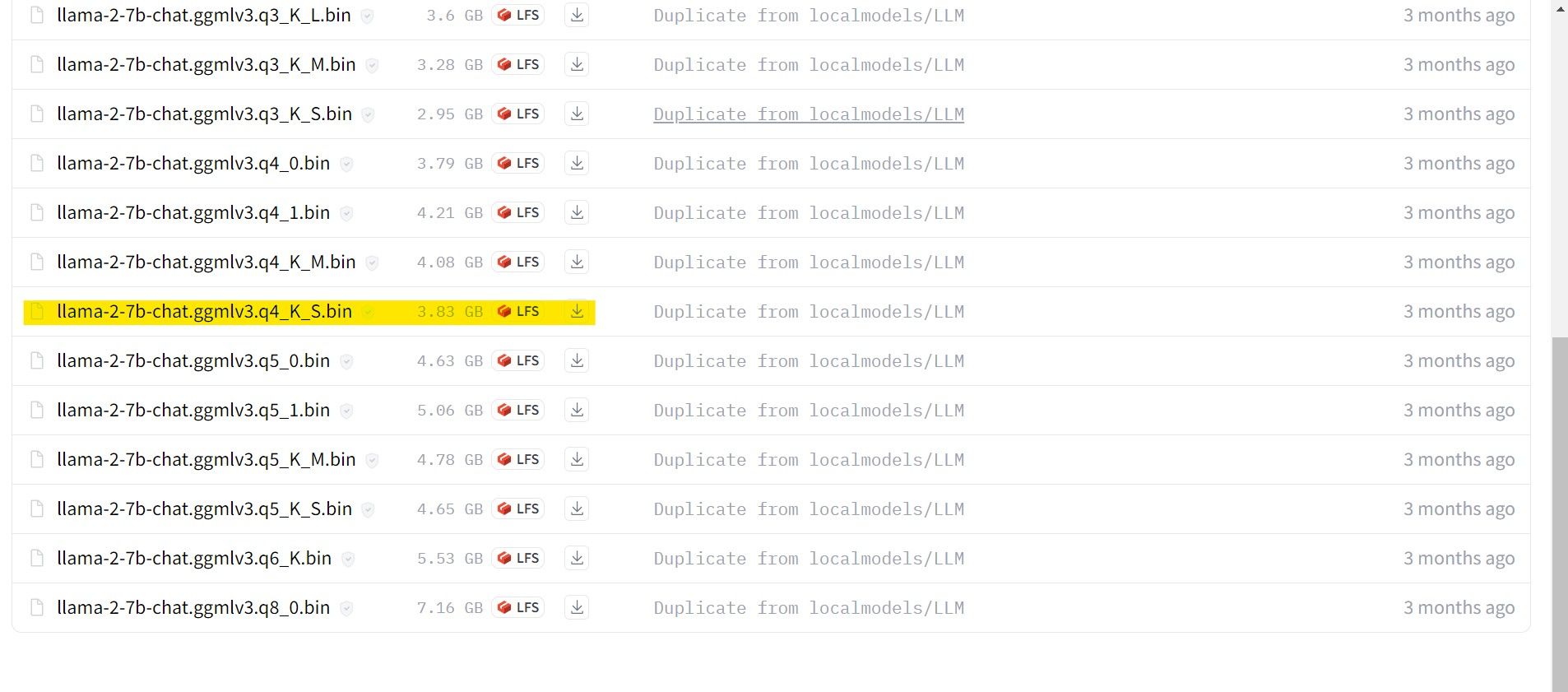
När nedladdningsprocessen har slutförts, se till att du överför den ovannämnda modellen till “text-generation-webui-main” katalogen som kan hittas i “models” mappen.
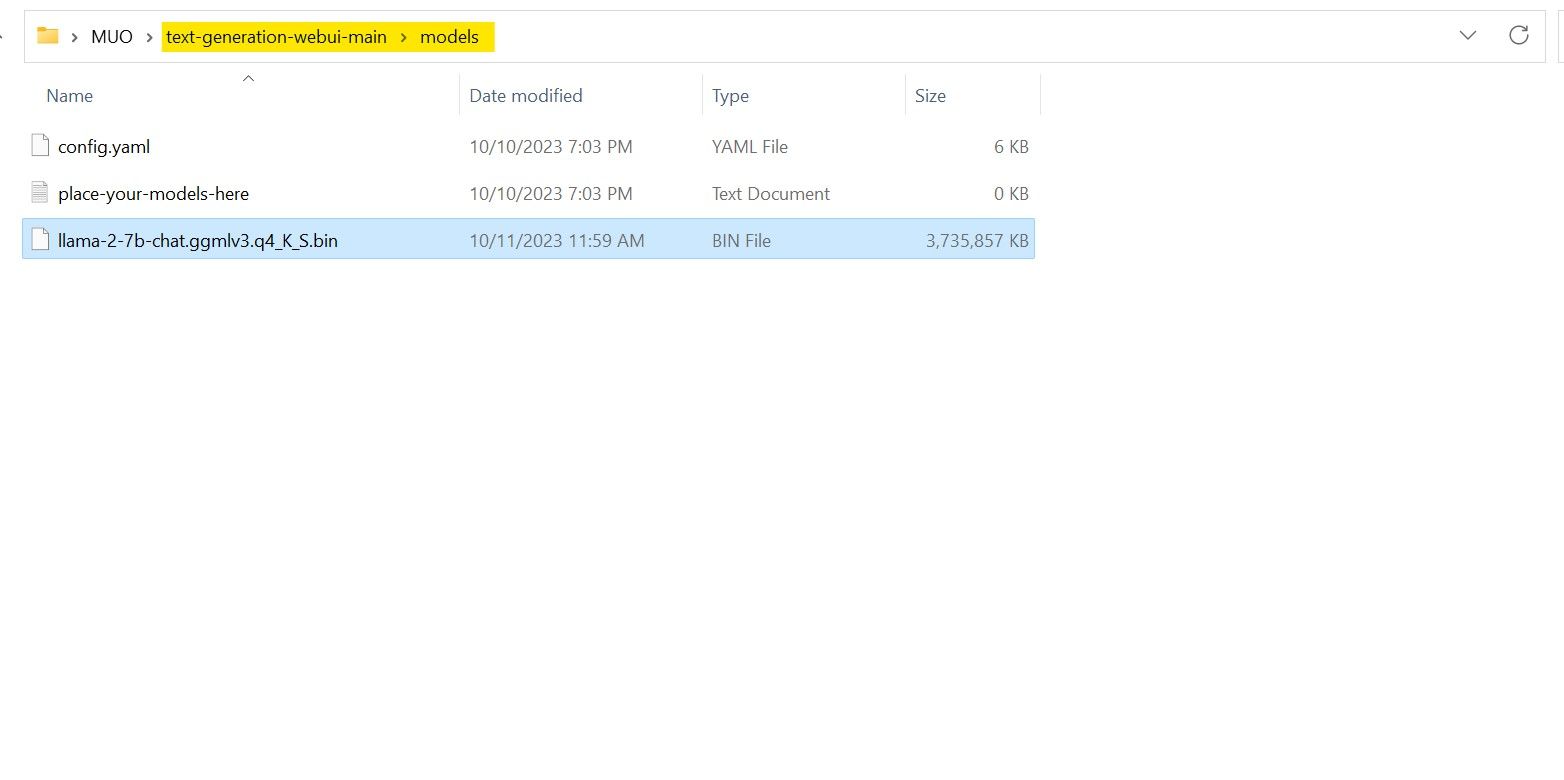
När modellen nu har laddats ner och lagrats i den angivna “modell”-katalogen är det viktigt att fortsätta med att konfigurera de nödvändiga komponenterna för att ladda modellen.
Steg 4: Konfigurera Text-Generation-WebUI
Låt oss nu påbörja konfigurationsfasen.
För att påbörja driften av Text-Generation-WebUI på ditt operativsystem ska du utföra lämpligt startkommando enligt beskrivningen i de föregående stegen.
Vänligen avstå från att använda svordomar eller vulgärt språk på denna plattform. Låt oss hålla en professionell ton i vår kommunikation.
⭐ Klicka nu på rullgardinsmenyn i Model loader och välj AutoGPTQ för dem som använder en GTPQ-modell och ctransformers för dem som använder en GGML-modell. Klicka slutligen på Ladda för att ladda din modell. 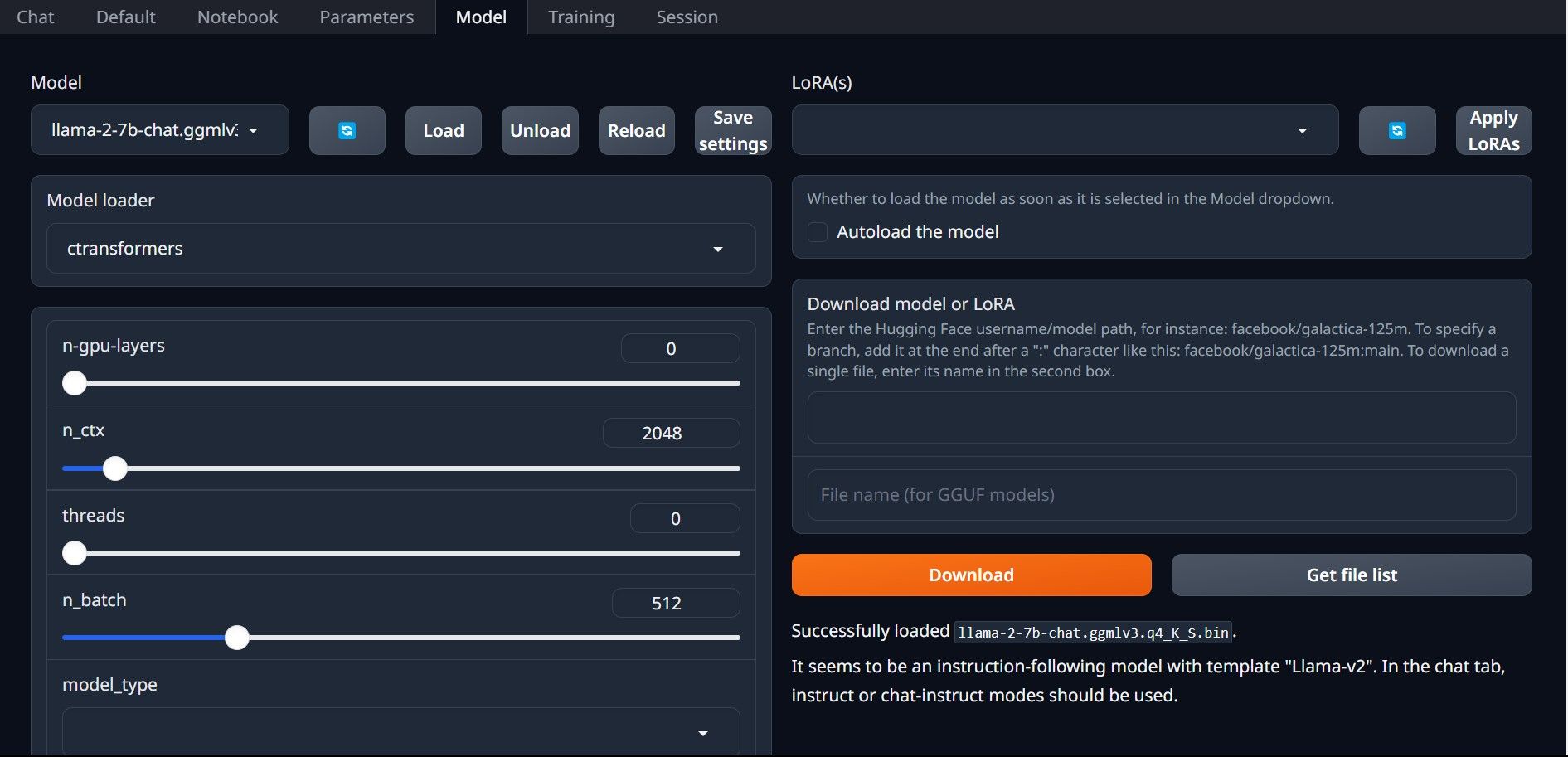
⭐ För att använda modellen, öppna fliken Chatt och börja testa modellen. 
Grattis, du har installerat Llama2 på din lokala maskin!
Prova andra LLMs
Nu när du har förvärvat förmågan att köra Llama 2 genom användning av Text-Generation-WebUI på din persondator, är det min förståelse att du på liknande sätt kan driva andra språkmodellavatarer bortom Llama. För att göra detta, kom ihåg den nomenklatur som används för att identifiera dessa avatarer, och notera att endast de med reducerad numerisk precision (vanligen kallad “q4”) kan användas på vanliga datorenheter. En mängd modeller som har genomgått denna kvantifieringsprocess kan hittas i HuggingFaces stora arkiv. Om du vill fördjupa dig ytterligare i alternativa avatarer kan du söka efter TheBloke i det ovan nämnda biblioteket och få ett överflöd av alternativ från vilka