Hur du förbättrar din Python-kod med samtidighet och parallellism
Viktiga lärdomar
Samtidighet och parallellism är grundläggande principer för prestanda i beräkningsuppgifter, och båda har unika egenskaper som skiljer dem från varandra.
Concurrency möjliggör effektiv resursallokering och ökad responsivitet i applikationer, medan parallellism spelar en viktig roll för att uppnå topprestanda och skalningsfunktioner.
Python erbjuder en mängd olika metoder för att hantera samtidiga operationer, inklusive användning av trådar genom det inbyggda trådbiblioteket, samt stöd för asynkron programmering med hjälp av asyncio-ramverket. Dessutom gör multiprocessing-modulen det möjligt för utvecklare att utnyttja kraften i parallell bearbetning i sina applikationer.
Concurrency avser förmågan hos ett system att köra flera processer eller trådar samtidigt, medan parallellism är förmågan att dela upp en uppgift i mindre deluppgifter och köra dem samtidigt i olika delar av systemet. I Python finns det olika metoder för att hantera samtidighet och parallellism, t.ex. multiprocessing, trådning, asynkron programmering med async/await och användning av bibliotek som Celery eller Dask för distribuerad databehandling. Dessa alternativ kan dock leda till förvirring när man ska välja det lämpligaste tillvägagångssättet för en specifik situation.
Fördjupa dig i de olika resurser och ramverk som effektivt kan underlätta implementeringen av samtidiga programmeringstekniker i Python, samt vad som skiljer dem från varandra.
Att förstå samtidighet och parallellism
Samtidighet och parallellism är två viktiga begrepp som beskriver hur uppgifter utförs i datorsystem, vart och ett med sina unika egenskaper.
⭐ Concurrency är ett programs förmåga att hantera flera uppgifter samtidigt utan att nödvändigtvis utföra dem exakt samtidigt. Det kretsar kring idén att interfoliera uppgifter och växla mellan dem på ett sätt som verkar simultant. 
⭐ Parallellism , å andra sidan, innebär att flera uppgifter utförs parallellt. Detta sker vanligtvis med hjälp av flera CPU-kärnor eller processorer. Med parallellism uppnås verklig samtidig körning, vilket gör att du kan utföra uppgifter snabbare och är väl lämpat för beräkningsintensiva operationer. 
Betydelsen av samtidighet och parallellitet
Betydelsen av samtidighet och parallellitet inom databehandling är odiskutabel, eftersom det gör att flera uppgifter kan utföras samtidigt, vilket ökar effektiviteten och minskar den totala exekveringstiden.Detta tillvägagångssätt har blivit allt viktigare på grund av den växande efterfrågan på snabbare och effektivare bearbetningskapacitet inom ett brett spektrum av tillämpningar, från vetenskapliga simuleringar till automatisering av arbetsflöden. Genom att utnyttja kraften i flerkärniga processorer och distribuerade system möjliggör samtidig och parallell bearbetning bättre resursutnyttjande och ökad skalbarhet, vilket i slutändan leder till bättre prestanda och ökad produktivitet.
Optimerad resursallokering kan uppnås genom concurrency eftersom det möjliggör effektivt utnyttjande av systemtillgångar, vilket garanterar att processer fortsätter att utvecklas produktivt istället för att passivt vänta på externa resurser.
Förmågan att förbättra applikationernas responsivitet, särskilt när det gäller användargränssnitt och webbserverinteraktioner, är en betydande fördel med concurrency.
Förbättrade prestanda kan uppnås genom parallellism, särskilt i beräkningsuppgifter som är starkt beroende av centrala processorenheter (CPU), t.ex. komplicerade beräkningar, datamanipulering och modelleringssimuleringar.
Skalbarhet är en kritisk aspekt av systemdesign och kräver både samtidig exekvering och parallell bearbetning för att uppnå optimal prestanda i stor skala. Förmågan att hantera ökande arbetsbelastningar med bibehållen effektivitet är av största vikt i modern programvaruutveckling.
Mot bakgrund av framväxande trender inom hårdvaruteknik som prioriterar flerkärnig bearbetningskapacitet, har det blivit absolut nödvändigt för programvarusystem att effektivt utnyttja parallellism för att säkerställa deras långsiktiga livskraft och hållbarhet.
Concurrency i Python
Concurrent execution kan uppnås i Python genom att använda antingen threading eller asynkrona tekniker, vilket underlättas av asyncio-biblioteket.
Trådning i Python
Trådning är en inneboende funktion i Python-programmering som gör det möjligt att skapa och hantera flera samtidiga uppgifter inom en enhetlig process. Denna mekanism är särskilt fördelaktig för uppgifter med tunga input/output-operationer eller för uppgifter som kan dra nytta av parallell exekvering.
Pythons trådmodul tillhandahåller ett gränssnitt på hög nivå för att skapa och hantera trådar. Även om GIL (Global Interpreter Lock) begränsar trådar när det gäller verklig parallellitet, kan de fortfarande uppnå samtidighet genom att effektivt sammanlänka uppgifter.
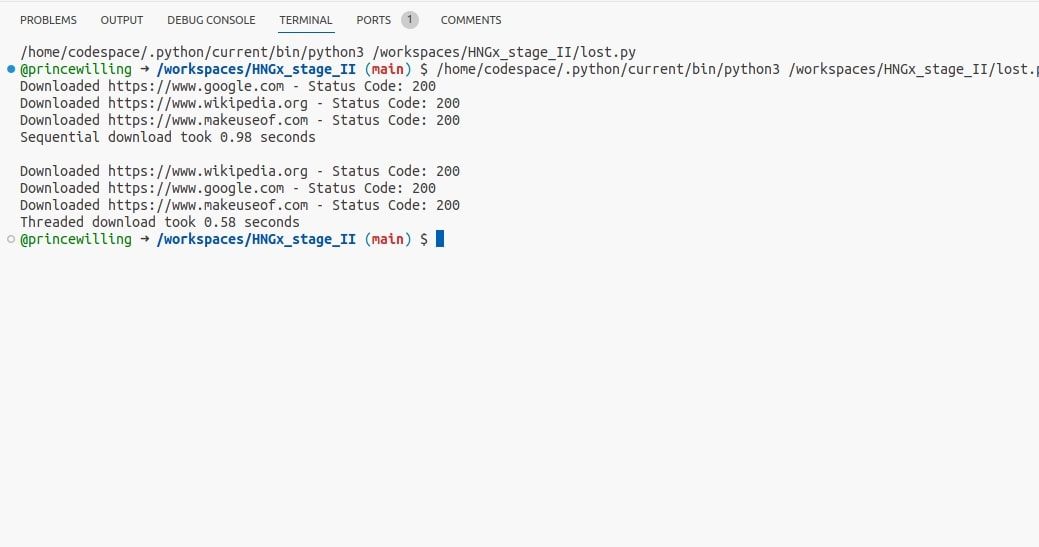
Den medföljande koden visar ett exempel på samtidig programmering genom användning av trådar i Python.Den använder Python Request-biblioteket för att initiera en HTTP-förfrågan, vilket är en typisk operation som involverar I/O-operationer (input-output) och kan resultera i blockerande uppgifter. Dessutom använder koden tidsmodulen för att bestämma hur länge programmet ska köras.
import requests
import time
import threading
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# function to request a URL
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
# Execute without threads and measure execution time
start_time = time.time()
for url in urls:
download_url(url)
end_time = time.time()
print(f"Sequential download took {end_time - start_time:.2f} seconds\n")
# Execute with threads, resetting the time to measure new execution time
start_time = time.time()
threads = []
for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
# Wait for all threads to complete
for thread in threads:
thread.join()
end_time = time.time()
print(f"Threaded download took {end_time - start_time:.2f} seconds")
Exekveringen av detta program visar en märkbar förbättring av effektiviteten när samtidiga trådar används för att utföra I/O-intensiva operationer, trots den marginella tidsskillnaden mellan sekventiella och parallella exekveringar.
Asynkron programmering med Asyncio
asyncio tillhandahåller en händelseslinga som hanterar asynkrona uppgifter som kallas coroutineÂs. CoroutineÂs är funktioner som du kan pausa och återuppta, vilket gör dem idealiska för I/O-bundna uppgifter. Biblioteket är särskilt användbart i scenarier där uppgifterna måste vänta på externa resurser, t.ex. nätverksförfrågningar.
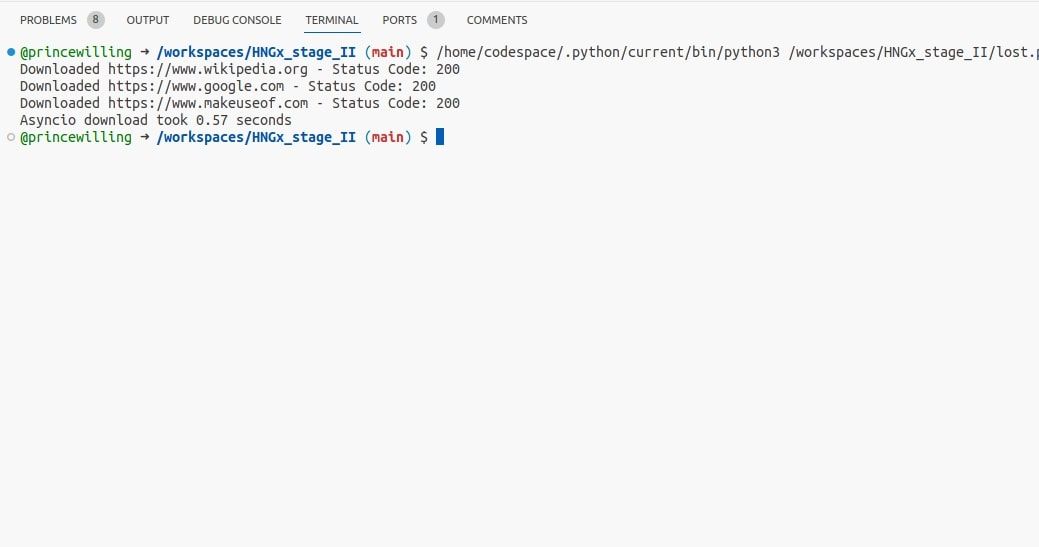
För att anpassa det tidigare exemplet med synkron sändning av begäran för användning med asynkron programmering i Python, måste du göra några ändringar. För det första, istället för att använda requests.get() och time.sleep() , som är blockerande operationer som pausar exekveringen tills den är slutförd respektive förfluten tid, bör du använda icke-blockerande alternativ som asyncio och aiohttp . Detta innebär att den befintliga koden packas in i en asynkron funktion med async def , och att de traditionella I/O-operationerna ersätts med sina asynkrona motsvarigheter. Exempelvis kan async with aiohttp.ClientSession().post(url) användas för att skicka en POST-begäran asynkront utan att vänta på ett svar. Dessutom kan felhantering och loggning också behöva justeras för att passa det nya async-ramverket.
import asyncio
import aiohttp
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# asynchronous function to request URL
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"Downloaded {url} - Status Code: {response.status}")
# Main asynchronous function
async def main():
# Create a list of tasks to download each URL concurrently
tasks = [download_url(url) for url in urls]
# Gather and execute the tasks concurrently
await asyncio.gather(*tasks)
start_time = time.time()
# Run the main asynchronous function
asyncio.run(main())
end_time = time.time()
print(f"Asyncio download took {end_time - start_time:.2f} seconds")
Med hjälp av den medföljande koden kan man effektivt utföra flera samtidiga nedladdningar av webbsidor genom att utnyttja asyncio och utnyttja kraften i asynkrona I/O-operationer. I motsats till traditionella trådningstekniker som är bättre lämpade för CPU-intensiva uppgifter, är detta tillvägagångssätt särskilt effektivt för att optimera I/O-bundna processer.
Parallellism i Python
Du kan implementera parallellism med Pythons multiprocessmodul , vilket gör att du kan dra full nytta av flerkärniga processorer.
Multiprocessing in Python
Pythons multiprocessing-modul erbjuder en metod för att utnyttja parallellism genom att skapa individuella processer, var och en utrustad med sin egen Python-tolk och minnesdomän. På så sätt kringgår denna metod Global Interpreter Lock (GIL) som är vanligt förekommande i CPU-bundna uppgifter.
import requests
import multiprocessing
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# function to request a URL
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
def main():
# Create a multiprocessing pool with a specified number of processes
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)
start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
# Close the pool and wait for all processes to finish
pool.close()
pool.join()
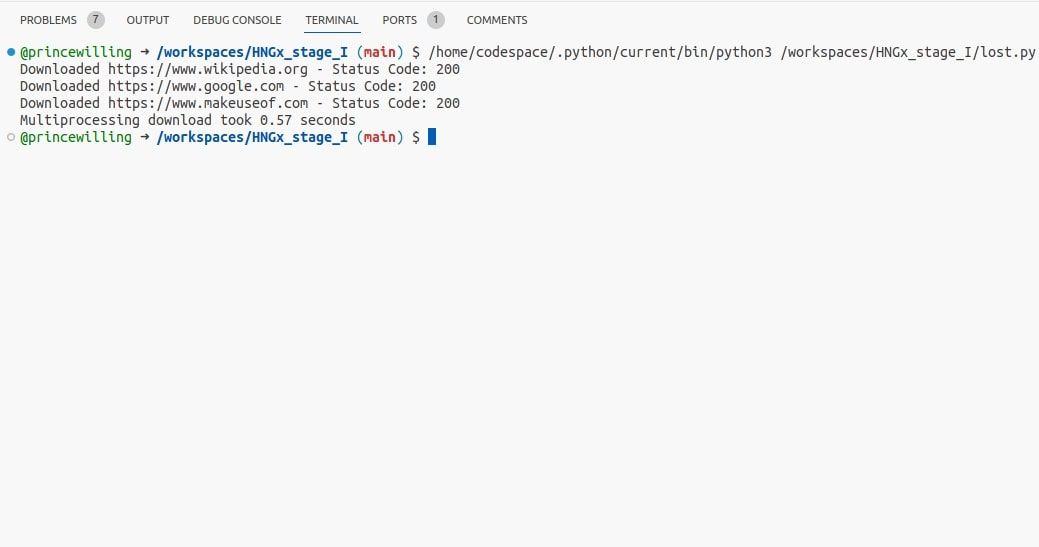
print(f"Multiprocessing download took {end_time-start_time:.2f} seconds")
main()
Multiprocessing möjliggör samtidig körning av download_url funktionen över flera processer, vilket underlättar parallell bearbetning av den givna URL:en.
När ska man använda samtidig eller parallell bearbetning
Beslutet att välja samtidig eller parallell bearbetning beror på egenskaperna hos de operationer som ska utföras och kapaciteten hos det underliggande systemets hårdvaruresurser.
Vid hantering av input/output (I/O)-centrerade operationer, som filläsning/skrivning eller nätverksbegäran, rekommenderas användning av concurrency på grund av dess förmåga att hantera flera uppgifter samtidigt. Dessutom kan det användas i situationer där minnesbegränsningar utgör en utmaning.
När användning av multiprocessing är lämpligt för CPU-intensiva operationer som kan förbättras genom samtidig körning och när det är en prioritet att säkerställa robust separation av processer, eftersom varje process misslyckande inte bör påverka de andra i onödan.
Dra nytta av samtidig körning och parallellism
Parallellism och samtidig körning är användbara metoder för att förbättra effektiviteten och genomströmningen i Python-program. Det är dock viktigt att förstå skillnaderna mellan dessa tekniker för att kunna fatta ett välgrundat beslut om vilket tillvägagångssätt som passar bäst i en viss situation.
Python tillhandahåller en omfattande uppsättning verktyg och moduler som gör det möjligt för utvecklare att förbättra kodens effektivitet genom att utnyttja antingen samtidiga eller parallella bearbetningstekniker, oavsett om de aktuella uppgifterna främst är beräknings- eller input/output-intensiva till sin natur.