Como construir um detector de plágio usando Python
Face ao crescimento exponencial dos conteúdos digitais, a sua proteção contra a duplicação e apropriação indébita assume uma importância primordial. O software de detecção de plágio serve como uma ajuda indispensável para educadores na avaliação de envios de alunos, instituições de pesquisa na verificação de trabalhos acadêmicos e autores na proteção de seus direitos de propriedade intelectual contra roubo.
O desenvolvimento de um software de detecção de plágio permite uma compreensão profunda da análise de sequência, recursos de manipulação de arquivos e design de interface do usuário. Além disso, a exploração de metodologias de processamento de linguagem natural refinará ainda mais a funcionalidade do aplicativo.
Módulo Tkinter e Difflib
A utilização do Tkinter em conjunto com o módulo Difflib permite o desenvolvimento de um sistema eficaz de detecção de plágio por meio de seus recursos versáteis na criação de interfaces de usuário interativas e visualmente atraentes em várias plataformas.
O módulo Difflib compreende um conjunto de classes e funções que facilitam a comparação de vários tipos de sequência, como strings, listas e arquivos dentro da biblioteca padrão da linguagem de programação Python. Utilizando este módulo, pode-se desenvolver aplicativos como um utilitário de correção de texto automatizado, um sistema de controle de versão simplificado ou até mesmo uma ferramenta de geração de resumo conciso.
Como construir um detector de plágio usando Python
Você pode localizar o código-fonte completo para construir uma ferramenta de detecção de plágio utilizando Python neste
uma referência de entrada e um elemento de representação gráfica. Esta função recuperará um documento de texto e apresentará seu conteúdo em um componente de exibição visual.
Utilize a função get() para recuperar o caminho do arquivo. Caso o usuário tenha negligenciado fornecer qualquer entrada, empregue o método askopenfilename() para invocar uma caixa de diálogo de arquivo que permite a seleção de um arquivo apropriado para fins de verificação de plágio. Simultaneamente, elimine quaisquer entradas anteriores que se estendam do início ao fim e substitua-as pelo caminho de arquivo escolhido enviado pelo usuário.
import tkinter as tk
from tkinter import filedialog
from difflib import SequenceMatcher
def load_file_or_display_contents(entry, text_widget):
file_path = entry.get()
if not file_path:
file_path = filedialog.askopenfilename()
if file_path:
entry.delete(0, tk.END)
entry.insert(tk.END, file_path)
Por favor, abra o arquivo especificado de maneira que permita a leitura e, posteriormente, armazene seu conteúdo na variável conhecida como “texto”. Após esta ação, esvazie o conteúdo do widget denominado “text\_widget” e substitua-o pelas informações obtidas anteriormente do arquivo.
with open(file_path, 'r') as file:
text = file.read()
text_widget.delete(1.0, tk.END)
text_widget.insert(tk.END, text)
Aqui está um trecho de código de exemplo em Python usando a biblioteca difflib para definir um método chamado “compare\_text()” que compara dois pedaços de texto e calcula sua porcentagem de similaridade utilizando a classe SequenceMatcher com a função de comparação padrão definida como None: pythonfrom difflib import SequenceMatcherdef compare_text(text1, text2): matcher=SequenceMatcher(None, text1, text2) ratio=matcher.ratio() similarity_percentage=round((ratio * 100), 2) if ratio > 0 else’N/A’retorna similarity_percentage
Utilize o método de proporção para obter uma representação decimal de similaridade, adequada para calcular porcentagens, empregando a função get\_opcodes() para reunir uma coleção de operações que podem ser usadas para identificar segmentos correspondentes dentro dos textos e, subsequentemente, fornecer a porcentagem de similaridade e correspondências identificadas lado a lado.
def compare_text(text1, text2):
d = SequenceMatcher(None, text1, text2)
similarity_ratio = d.ratio()
similarity_percentage = int(similarity_ratio * 100)
diff = list(d.get_opcodes())
return similarity_percentage, diff
Para realizar uma comparação entre dois textos inseridos em campos de entrada separados e exibir a porcentagem de similaridade resultante, podemos definir um método chamado show\_similarity(). Este método deve utilizar o método get() para recuperar o conteúdo de cada caixa de texto e então passar estes valores para outra função chamada compare\_text(). Também é necessário limpar o conteúdo do campo de saída onde a porcentagem de similaridade será exibida e remover quaisquer tags HTML existentes associadas ao texto realçado.
def show_similarity():
text1 = text_textbox1.get(1.0, tk.END)
text2 = text_textbox2.get(1.0, tk.END)
similarity_percentage, diff = compare_text(text1, text2)
text_textbox_diff.delete(1.0, tk.END)
text_textbox_diff.insert(tk.END, f"Similarity: {similarity_percentage}%")
text_textbox1.tag_remove("same", "1.0", tk.END)
text_textbox2.tag_remove("same", "1.0", tk.END)
a cadeia de caracteres opcode, a posição inicial da sequência inicial, o ponto de término da sequência primária, o início da sequência secundária e a conclusão da sequência secundária.
“substituir”, “excluir”, “inserir” ou “igual”. Isso indica que ocorreu uma alteração nas regiões correspondentes de ambas as fitas de DNA. Especificamente, um resultado de"substituição"resulta de instâncias em que a composição de nucleotídeos de um determinado segmento varia entre as duas sequências. Por outro lado, um veredicto"excluir"significa a presença de um fragmento de ácido nucleico em apenas uma das sequências em exame. Por fim, uma decisão de “inserção” denota a adição de uma sequência específica a uma das moléculas de DNA.
O problema da Subsequência Comum Mais Longa (LCS) envolve encontrar a subsequência mais longa que existe em ambas as sequências e, em seguida, determinar se ela possui uma relação “igual” ou “insertiva” com base em sua presença em cada sequência. Os valores obtidos a partir desta análise podem ser armazenados em variáveis apropriadas para processamento posterior. Além disso, se a sequência do opcode corresponder aos critérios fornecidos, uma tag específica pode ser adicionada à sequência de texto.
for opcode in diff:
tag = opcode[0]
start1 = opcode[1]
end1 = opcode[2]
start2 = opcode[3]
end2 = opcode[4]
if tag == "equal":
text_textbox1.tag_add("same", f"1.0\+{start1}c", f"1.0\+{end1}c")
text_textbox2.tag_add("same", f"1.0\+{start2}c", f"1.0\+{end2}c")
Inicialize a janela raiz do Tkinter instanciando uma instância de sua classe, definindo seu título e criando um quadro dentro dela. Embeleze a moldura com ajustes interespaciais adequados em todos os lados. Construa dois widgets de rótulos, cada um responsável por exibir conteúdo textual distinto. Especifique seus respectivos elementos pais e estipule as informações que devem exibir.
Crie um widget de texto com três entradas, duas para inserir textos a serem comparados e outra para mostrar os resultados da comparação. Especifique o contêiner pai, as dimensões e o estilo de quebra automática de texto como tk.WORD para garantir a quebra de linha adequada sem quebrar nenhuma palavra no texto.
root = tk.Tk()
root.title("Text Comparison Tool")
frame = tk.Frame(root)
frame.pack(padx=10, pady=10)
text_label1 = tk.Label(frame, text="Text 1:")
text_label1.grid(row=0, column=0, padx=5, pady=5)
text_textbox1 = tk.Text(frame, wrap=tk.WORD, width=40, height=10)
text_textbox1.grid(row=0, column=1, padx=5, pady=5)
text_label2 = tk.Label(frame, text="Text 2:")
text_label2.grid(row=0, column=2, padx=5, pady=5)
text_textbox2 = tk.Text(frame, wrap=tk.WORD, width=40, height=10)
text_textbox2.grid(row=0, column=3, padx=5, pady=5)
Utilize o GridLayoutManager para organizar cada elemento dentro de uma matriz estruturada, incorporando o uso da ferramenta packer para posicionar o “compare\_button” e o “text\_textbox\_diff”. Aplique quantidades adequadas de espaçamento conforme necessário para garantir o alinhamento adequado e o equilíbrio visual.
file_entry1 = tk.Entry(frame, width=50)
file_entry1.grid(row=1, column=2, columnspan=2, padx=5, pady=5)
load_button1 = tk.Button(frame, text="Load File 1", command=lambda: load_file_or_display_contents(file_entry1, text_textbox1))
load_button1.grid(row=1, column=0, padx=5, pady=5, columnspan=2)
file_entry2 = tk.Entry(frame, width=50)
file_entry2.grid(row=2, column=2, columnspan=2, padx=5, pady=5)
load_button2 = tk.Button(frame, text="Load File 2", command=lambda: load_file_or_display_contents(file_entry2, text_textbox2))
load_button2.grid(row=2, column=0, padx=5, pady=5, columnspan=2)
compare_button = tk.Button(root, text="Compare", command=show_similarity)
compare_button.pack(pady=5)
text_textbox_diff = tk.Text(root, wrap=tk.WORD, width=80, height=1)
text_textbox_diff.pack(padx=10, pady=10)
A passagem discute os benefícios potenciais da incorporação de inteligência artificial (IA) na indústria da construção, focando especificamente na melhoria da eficiência, segurança, sustentabilidade e qualidade. O autor sugere que a IA tem a capacidade de revolucionar vários aspectos dos projetos de construção, automatizando tarefas repetitivas, otimizando a alocação de recursos, prevendo riscos, aprimorando a comunicação entre as partes interessadas e facilitando a tomada de decisão baseada em dados. Além disso, a integração da IA pode contribuir para reduzir custos, minimizar desperdícios, promover a inovação e fomentar a colaboração entre as equipes de projeto. No entanto, existem desafios associados à implementação da IA na construção, como resistência dos trabalhadores, preocupações com o deslocamento do trabalho e dificuldades na adaptação das práticas atuais. No entanto, os proponentes argumentam que adotar a IA pode levar
text_textbox1.tag_configure("same", foreground="red", background="lightyellow")
text_textbox2.tag_configure("same", foreground="red", background="lightyellow")
A função mainloop() em Python, quando executada em um aplicativo Tkinter, ativa o loop de eventos da estrutura da GUI, fazendo com que ela monitore e responda continuamente às interações do usuário com a interface até que a janela seja fechada ou encerrada de outra forma pelo usuário.
root.mainloop()
Utilize uma abordagem abrangente integrando todos os elementos do projeto e, em seguida, execute o programa para detectar má conduta acadêmica.
Saída de exemplo do detector de plágio
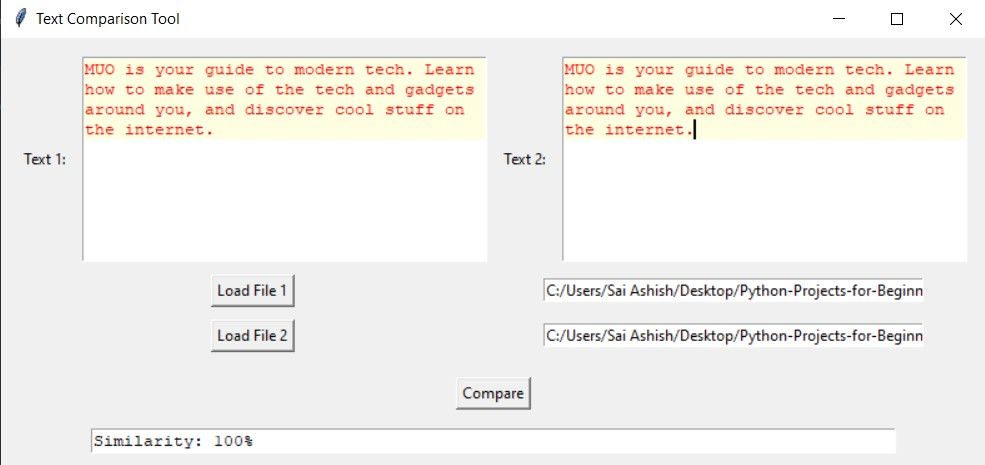
Ao executar o aplicativo, uma interface é exibida contendo duas caixas de texto e um botão denominado “Carregar arquivo 1”. Ao clicar neste botão, um navegador de arquivos surge permitindo a seleção de um arquivo desejado. Uma vez escolhido, o conteúdo é apresentado dentro da caixa de texto inicial. Da mesma forma, ao digitar um caminho de diretório e pressionar o botão"Carregar arquivo 2", outro conjunto de conteúdo aparece na caixa de texto secundária. Por fim, ao clicar na opção “Comparar” é indicada a compatibilidade total com ambos os textos mostrados na íntegra, com ênfase de 100%.
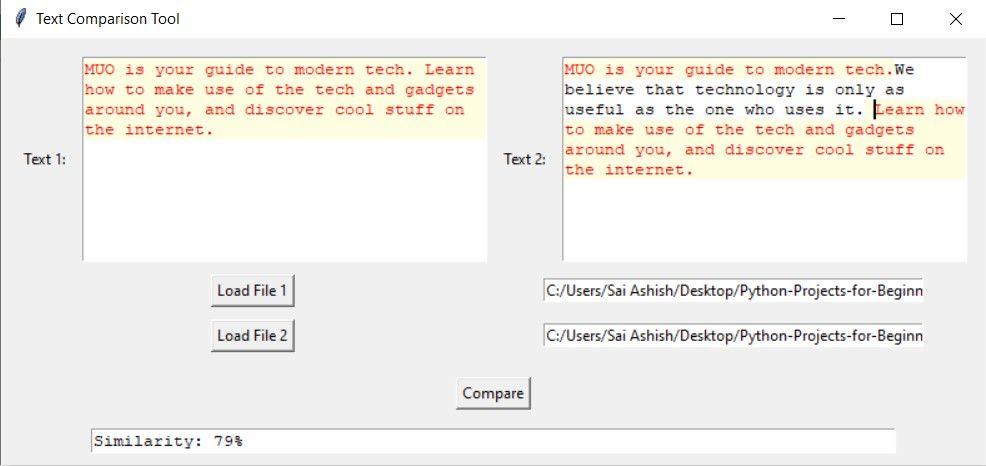
Se você inserir texto adicional em um campo e, posteriormente, iniciar a função “Comparar”, o software identificará e enfatizará todas as passagens correspondentes, desconsiderando o conteúdo restante.
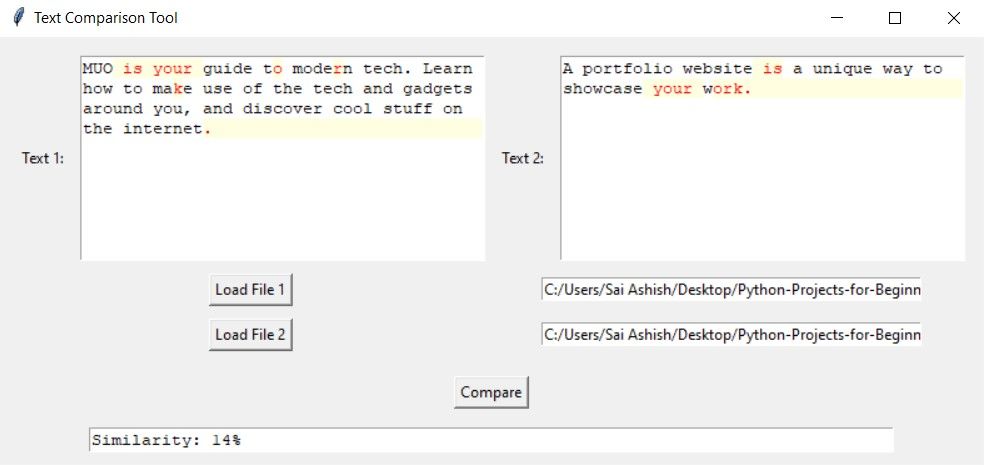
Nos casos em que existe pouca ou nenhuma semelhança entre dois textos, o software pode exibir certos caracteres ou frases como semelhantes; no entanto, o grau de semelhança indicado pela porcentagem fornecida geralmente será bem pequeno.
Usando NLP para detecção de plágio
O Difflib, embora seja uma ferramenta eficaz para comparação de texto, pode não ser adequado para determinadas tarefas devido à sua sensibilidade a pequenas variações, capacidade limitada de entender o contexto e potencial ineficácia ao lidar com quantidades substanciais de dados. Seria prudente explorar abordagens alternativas, como processamento de linguagem natural (NLP), que pode fornecer análise semântica, extrair recursos relevantes e possuir uma compreensão mais profunda do contexto.
Além disso, pode-se instruir seu modelo a reconhecer vários contextos linguísticos, treinando-o em vários idiomas e aprimorando seu desempenho por meio de algoritmos otimizados. Existem várias abordagens para detectar plágio, como utilizar a similaridade de Jaccard, empregar a similaridade do cosseno em modelos de espaço vetorial, alavancar a incorporação de palavras, conduzir a análise de sequência latente e implementar arquiteturas de sequência a sequência.