Os 5 melhores geradores de imagens de IA de código aberto
Os avanços na inteligência artificial conduziram a uma abundância de modelos de geração de texto para imagem que podem ser acedidos com facilidade numa base regular. Embora seja simples obter as imagens pretendidas através de plataformas online, a utilização de geradores de texto-imagem de código aberto proporciona uma maior flexibilidade ao longo do processo de criação.
Podem ser encontrados online vários sintetizadores de texto-imagem de código aberto e de acesso livre, cada um centrado numa categoria específica de imagens. Consequentemente, depois de analisarmos minuciosamente estas opções, compilámos uma lista dos principais geradores de texto-imagem de IA de código aberto que podem ser utilizados atualmente pelos utilizadores.
1 Craiyon
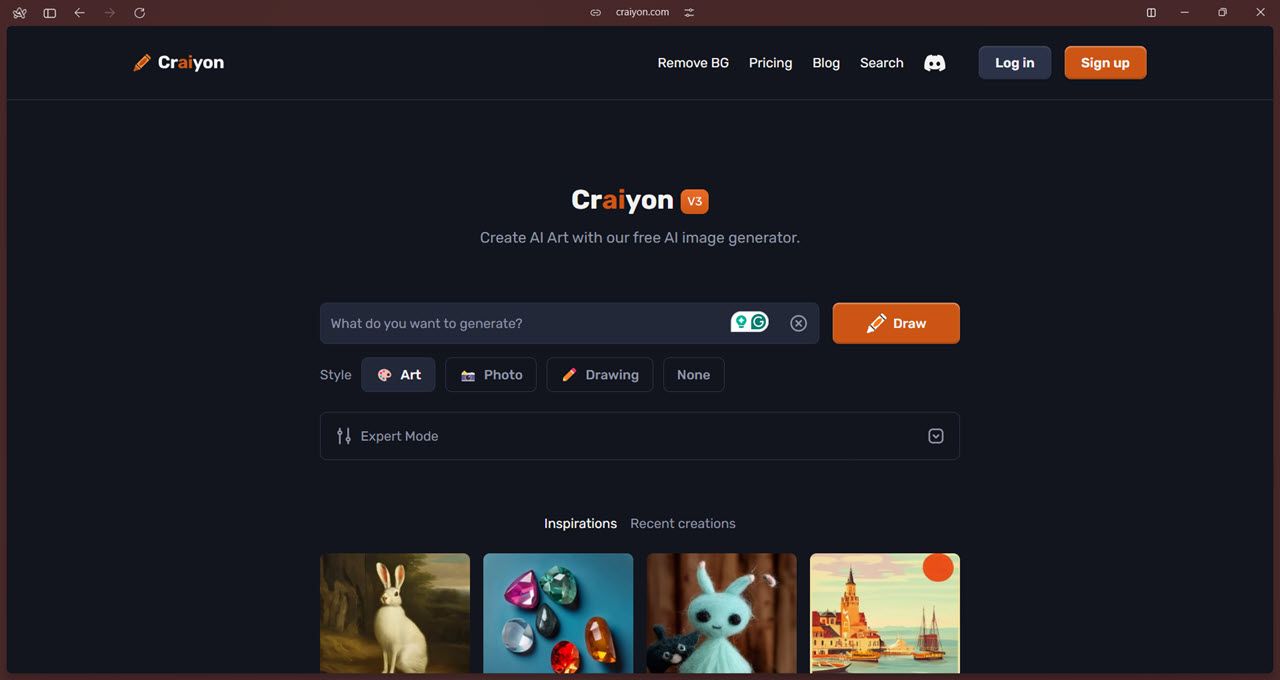
Craiyon é um dos geradores de imagens de IA de código aberto mais facilmente acessíveis. Ele é baseado no DALL-E Mini e, embora seja possível clonar o repositório do Github e instalar o modelo localmente no seu computador, o Craiyon parece ter abandonado essa abordagem em favor do seu site.
O repositório oficial do Github não é atualizado desde junho de 2022, mas o modelo mais recente ainda está disponível gratuitamente no site oficial do Craiyon . Também não existem aplicações para Android ou iOS.
Em termos de funcionalidades, este gerador de imagens de IA fornece os recursos padrão que se esperaria ao entrar em um prompt para a geração de uma imagem. Além disso, os utilizadores têm a capacidade de melhorar a resolução das imagens geradas através da utilização da função de aumento de escala. Estão disponíveis três estilos artísticos distintos para seleção sob a forma de “Arte”, “Fotografia” e “Desenho”. Em alternativa, a opção “Nenhum” permite que o próprio modelo determine o estilo.
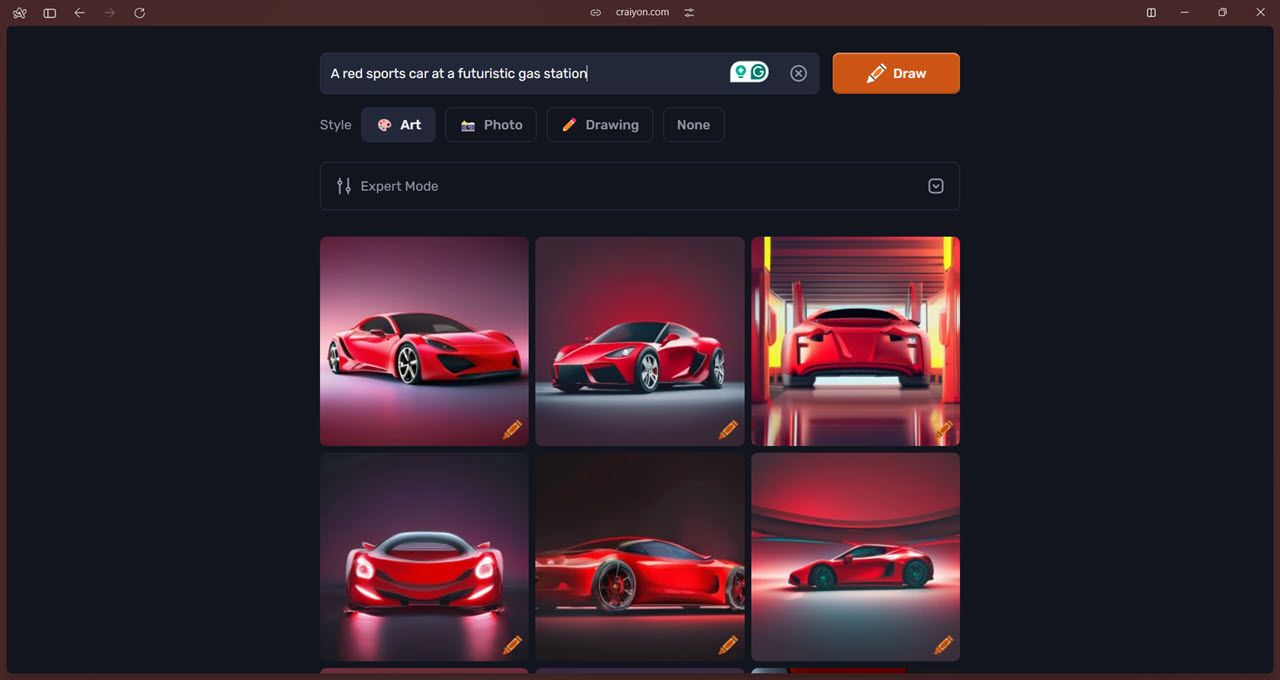
No Modo Especialista, a inclusão de palavras-chave negativas permite que o modelo evite determinadas entidades. A incorporação de previsões de mensagens facilitadas pelo ChatGPT aumenta a proficiência do utilizador na criação de mensagens abrangentes e elaboradas. Além disso, a funcionalidade de Remoção de Fundos orientada por IA acelera o processo de erradicação de cenários indesejados dos meios visuais através da automatização.
Craion é uma ferramenta de geração de imagens de IA com uma funcionalidade simples. Embora possa não ter características avançadas e detalhes intrincados, a sua simplicidade torna-a adequada para utilizadores que procuram uma solução básica, mas funcional, sem exigir elevados níveis de realismo nas imagens geradas.
A plataforma oferece uma política de utilização generosa, permitindo que os indivíduos acedam aos seus serviços sem incorrer em quaisquer custos.No entanto, aplicam-se certas limitações aos utilizadores gratuitos, tais como uma restrição ao número de imagens que podem ser processadas num período de sessenta segundos. Para desbloquear funcionalidades adicionais, incluindo uma experiência sem anúncios, tempos de processamento mais rápidos e a capacidade de armazenar resultados de imagens de forma segura, pode optar por atualizar para os planos de subscrição Supporter ou Professional. Estes planos estão disponíveis para pagamentos mensais com opções de faturação anual e fornecem vários níveis de personalização e suporte técnico, dependendo do pacote escolhido. Além disso, uma solução personalizada, conhecida como plano Custom, proporciona uma grande flexibilidade, oferecendo modelos de aprendizagem automática personalizados, capacidades de integração perfeita, serviço de apoio ao cliente prioritário e recursos de servidor exclusivos.
2 Stable Diffusion 1.5
O Stable Diffusion é um modelo de geração de texto para imagem de código aberto altamente conceituado que ganhou uma popularidade significativa desde o seu lançamento em 2022. Para além de ser um modelo independente, serve de base a vários outros modelos de geração de imagens, como os três exemplos acima mencionados. Desde a sua introdução, tem havido inúmeras implementações bem sucedidas desta abordagem inovadora à síntese de imagens.
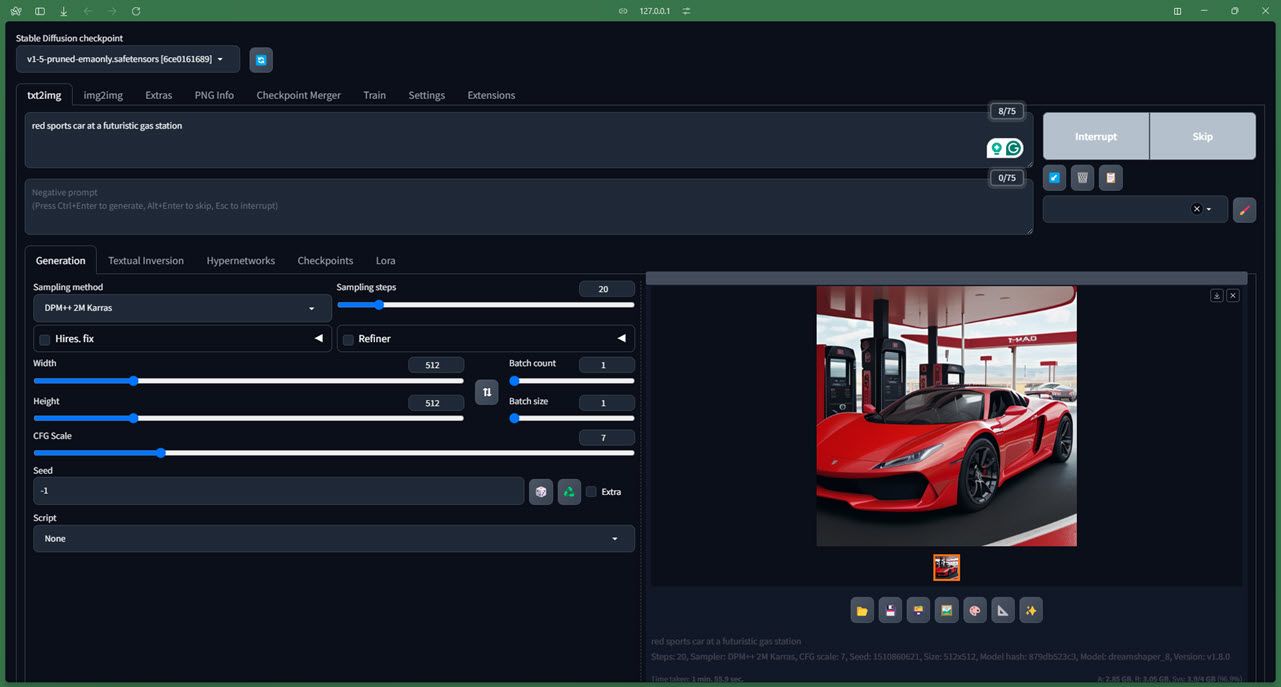
Vou poupar-vos aos detalhes demasiado técnicos de como o modelo funciona (para os quais podem consultar o repositório oficial do Github ), mas o modelo é fácil de instalar mesmo para principiantes e funciona bem desde que tenham uma GPU dedicada com pelo menos 4 GB de memória. Você também pode acessar Stable Diffusion online, e nós o ajudamos se você quiser executar o Stable Diffusion em um Mac .
Existem vários pontos de controlo (considere-os versões) disponíveis para usar no Stable Diffusion. Embora tenhamos testado a versão 1.5, a versão 2.1 também está em desenvolvimento ativo e é mais precisa.
 Yadullah Abidi/All Things N/DreamShaper
Yadullah Abidi/All Things N/DreamShaper
A execução do modelo também é bastante fácil. Testámo-lo com a interface de utilizador Web AUTOMATIC1111 Stable Diffusion , e todos os controlos e parâmetros funcionam bem. Também é bastante à prova de NSFW, cortesia da base de dados LAION-5B em que o modelo foi treinado (embora não seja perfeita, note-se). Embora o tempo de geração varie consoante o seu hardware, pode esperar que as suas imagens sejam detalhadas e realistas, mesmo com instruções básicas.
3 DreamShaper
O DreamShaper é um novo modelo de geração de imagens que utiliza os princípios da difusão estável como base.Concebida como uma alternativa versátil e acessível à MidJourney, esta ferramenta inovadora apresenta uma proficiência excecional na produção de fotografias altamente realistas, ao mesmo tempo que demonstra uma adaptabilidade notável na criação de estilos de anime e de pintura artística através de pequenos ajustes.
O modelo é mais capaz do que o Stable Diffusion, permitindo aos utilizadores uma maior liberdade sobre o resultado final, desde melhorias de iluminação a restrições NSFW mais flexíveis. A execução do modelo também é fácil, com uma versão pré-treinada descarregável disponível online para acesso local e uma série de sítios Web, incluindo Sinkin.ai , RandomSeed e Mage.space (requer uma subscrição básica) que permitem executar o modelo com aceleração GPU.
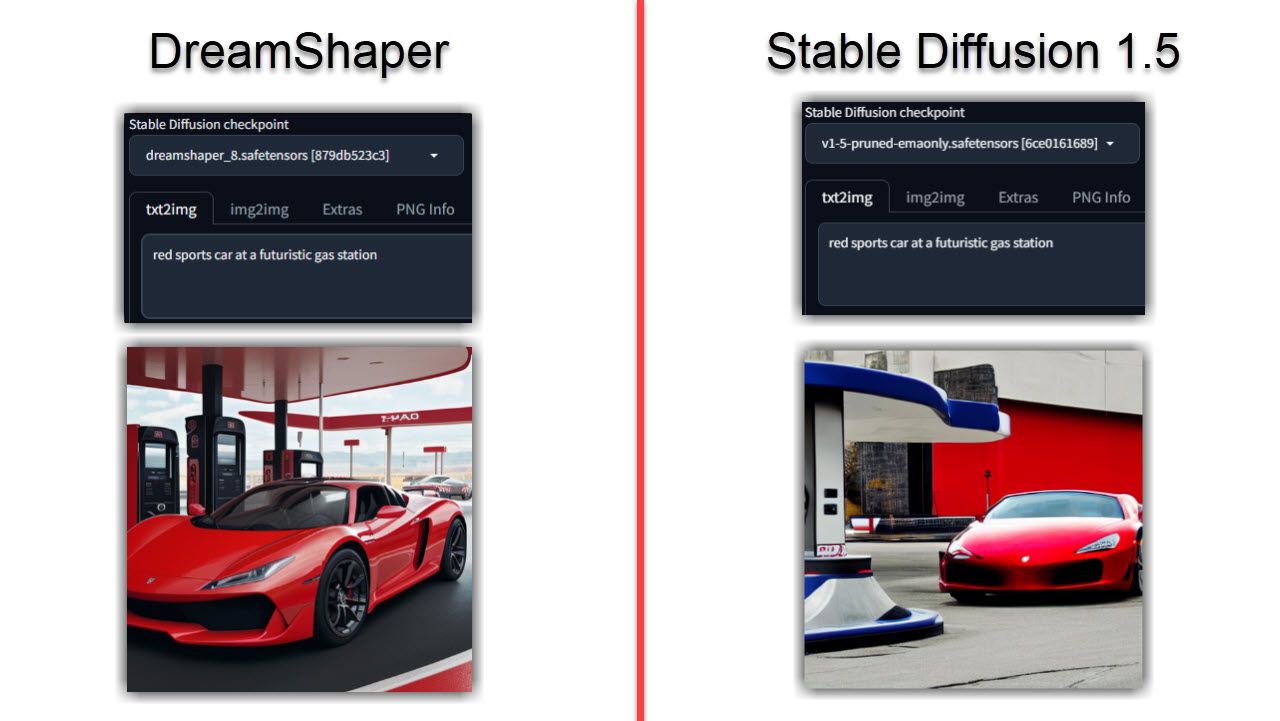
Em comparação com o Stable Diffusion, é evidente que as imagens produzidas pelo DreamShaper apresentam um maior grau de realismo, complexidade e iluminação. Apesar de empregar parâmetros de entrada idênticos, o DreamShaper supera consistentemente o seu homólogo em termos de fidelidade visual e qualidade geral.
Uma das diferenças significativas entre a difusão estável e outros modelos generativos reside na sua capacidade de criar representações realistas de objectos humanos, como retratos ou personagens. Embora seja inegavelmente impressionante que estes modelos consigam produzir representações altamente detalhadas e precisas, podem ainda assim ficar aquém quando comparados com formas de arte tradicionais que se baseiam em interpretações mais subjectivas e na criatividade. De facto, poder-se-ia argumentar que a própria essência do que torna uma obra de arte única e valiosa são precisamente as suas imperfeições e individualidade. Por conseguinte, embora as imagens geradas por IA possam ser tecnicamente competentes, podem, em última análise, carecer da profundidade emocional e do toque pessoal que distingue as verdadeiras grandes obras de arte das meras imitações.
Não é necessário um sistema de computação extenso para executar este modelo específico. De facto, a minha NVIDIA GeForce GTX 1650Ti com os seus 4 GB de memória de vídeo teve um desempenho admirável na execução do modelo. Embora o processo de geração tenha demorado um pouco mais, não parece ter havido nenhum impacto percetível na saída resultante. No entanto, é de notar que poderá ser necessária uma maior quantidade de memória de vídeo para gerir eficazmente os requisitos exigentes do DreamShaper XL, que se baseia no modelo Stable Diffusion XL.
4 InvokeAI
O Invoke AI é um modelo sofisticado de geração de imagens que utiliza o algoritmo avançado Stable Diffusion para criar imagens visualmente atraentes.O modelo possui duas versões - uma standard e uma XL - ambas concebidas para fornecer resultados de alta qualidade de forma eficiente. Além disso, o Invoke AI possui uma interface web e de linha de comando de fácil utilização, eliminando a necessidade de os utilizadores navegarem através de interfaces complexas, como as encontradas noutros modelos de AI.
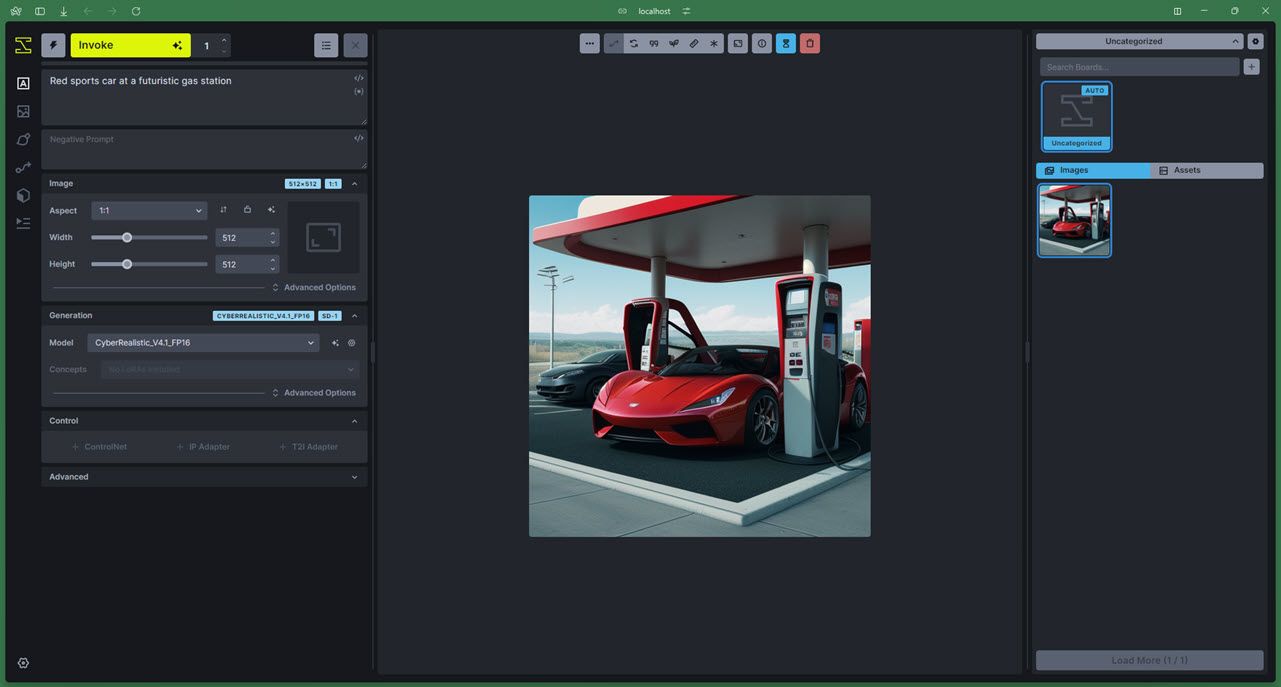
A peça central da nossa oferta consiste em dar aos utilizadores a capacidade de gerar conteúdos visualmente cativantes a partir dos seus conhecimentos próprios, adaptando o processo de acordo com as preferências individuais. Neste sentido, tiramos partido das potentes capacidades do InvokeAI, um modelo de IA de código aberto de topo especificamente concebido para cultivar imagens personalizadas através da sua integração perfeita com activos proprietários.
O seu repositório oficial do Github lista dois métodos de instalação: instalar através do instalador do InvokeAI ou utilizar o PyPI se estiver confortável com um terminal e Python e precisar de mais controlo sobre os pacotes instalados com o modelo.
Para utilizar a funcionalidade adicional fornecida pelo InvokeAI, alguns pré-requisitos devem ser atendidos em termos de especificações do sistema. Especificamente, é necessária uma GPU dedicada com um mínimo de 4 GB de memória, sendo sugeridos 6-8 GB para a variante maior. Tanto as placas gráficas AMD como Nvidia estão sujeitas a estas mesmas restrições de VRAM. Além disso, será necessário um mínimo de 12 GB de RAM e 12 GB de espaço disponível no disco rígido para acomodar o modelo de rede neural, bem como quaisquer dependências associadas e ficheiros de instalação Python.
 Yadullah Abidi/All Things N/InvokeAI
Yadullah Abidi/All Things N/InvokeAI
Embora não seja recomendado na documentação devido à memória de vídeo insuficiente, o nosso processo de instalação testado com as unidades de processamento gráfico (GPUs) GTX Série 10 e Série 16 da Nvidia foi bem sucedido. No entanto, tenha em atenção que o desempenho pode variar consoante as especificações individuais do sistema. Além disso, gostaríamos de informar os utilizadores com GPUs de gama inferior que poderão ter tempos de espera ligeiramente mais longos antes de verem os resultados visuais. Por último, para os utilizadores de sistemas operativos Windows, tenha em atenção que, de momento, apenas as GPUs Nvidia são suportadas, enquanto as GPUs AMD continuam a não ser suportadas.
A implementação atual da plataforma InvokeAI tende a produzir imagens artísticas em vez de fotorealistas. No entanto, isto pode ser ajustado treinando o modelo com um conjunto de dados personalizado. Esta abordagem produzirá melhores resultados ao gerar imagens realistas, particularmente em áreas como o design de produtos, a arquitetura e os ambientes de retalho.É de notar que, embora o InvokeAI funcione como um motor de geração de imagens eficaz, para obter os melhores resultados pode ser necessário utilizar modelos externos acedidos através do Gestor de modelos integrado na interface do utilizador.
5 Openjourney
O Openjourney é um modelo de geração de imagens de IA que utiliza a tecnologia Stable Diffusion e funciona como uma plataforma de código aberto. O nome “Openjourney” reflecte o facto de o modelo ter sido treinado utilizando imagens Midjourney para replicar o seu estilo visual distinto nas imagens geradas.
PromptHero , a empresa por detrás do Openjourney, permite-lhe testar o modelo juntamente com outros modelos, incluindo o Stable Diffusion (versões 1.5 e 2), o DreamShaper e o Realistic Vision. Quando se inscreve, recebe 25 créditos gratuitos (um crédito por cada imagem gerada), após o que tem de subscrever o nível de subscrição Pro, que custa 9 dólares por mês e lhe dá acesso a 300 créditos por mês e a outras funcionalidades exclusivas.

No entanto, se quiser executá-lo localmente e gratuitamente, pode descarregar o ficheiro do modelo de HuggingFace e executá-lo utilizando a interface Web do Stable Diffusion. O Openjourney também é o segundo modelo de geração de imagens de IA mais baixado no HuggingFace, logo atrás do Stable Diffusion.
Não é explicitamente declarado no site do Openjourney quais pré-requisitos de hardware são necessários para baixar e implementar seu modelo de IA offline. No entanto, é provável que essas necessidades sejam comparáveis às exigidas pelo Stable Diffusion. Para executar o modelo com êxito, é necessário ter acesso a uma unidade de processamento gráfico (GPU) dedicada, equipada com pelo menos 4 gigabytes de memória de vídeo (VRAM), 16 GB de RAM e cerca de 12 a 15 gigabytes de capacidade de armazenamento disponível no dispositivo para acomodar o modelo e os componentes associados.
 Yadullah Abidi/All Things N/OpenJourney
Yadullah Abidi/All Things N/OpenJourney
A Openjourney cria imagens que estabelecem um equilíbrio entre realismo e arte, com exceção de quaisquer pedidos específicos. Para quem procura um modelo versátil que reúna as características do fotorrealismo e da arte, evitando o pagamento de uma subscrição, o Openjourney apresenta-se como uma opção muito adequada.