Uma introdução ao uso de fluxos no Node.js
Principais lições
Os fluxos desempenham um papel essencial no Node.js, pois facilitam o processamento e a transmissão eficientes de dados, fornecendo assim suporte ideal para aplicativos em tempo real e acionados por eventos.
Utilizando as ofertas do módulo de sistema de arquivos do Node.js, é possível empregar a função createWriteStream() para estabelecer um fluxo gravável que direciona os dados para uma área específica.
O ambiente Node.js engloba uma variedade de tipos de fluxo que atendem a diferentes propósitos e requisitos. Essas quatro categorias primárias incluem fluxos legíveis, graváveis, duplex e transformáveis. Cada tipo tem uma função distinta e fornece recursos específicos, permitindo que os desenvolvedores selecionem a opção mais apropriada para suas necessidades específicas de aplicação.
Em essência, um fluxo serve como uma construção de programação crucial para facilitar a transmissão contínua de informações de um local para outro. O conceito de um fluxo gira essencialmente em torno do transporte sistemático de bytes ao longo de um caminho pré-determinado. De acordo com os recursos oficiais do Node.js, um fluxo constitui um quadro hipotético que permite aos utilizadores interagir com os dados e manipulá-los.
A transmissão eficiente de informações através de um fluxo é um excelente exemplo da sua aplicação em sistemas informáticos e na comunicação em rede.
Fluxos no Node.js
Os fluxos têm sido um fator crucial na prosperidade do Node.js devido à sua adequação ao processamento de dados em tempo real e às aplicações orientadas para eventos, que são aspectos fundamentais do ambiente de tempo de execução do Node.js.
Para estabelecer um novo fluxo no Node.js, é preciso empregar a API de fluxo, que é estritamente dedicada a manipular objetos String e armazenar dados em buffer dentro do sistema. Há quatro categorias principais de fluxos reconhecidas pelo Node.js, nomeadamente as variedades graváveis, legíveis, duplex e transformativas.
Como criar e usar um fluxo gravável
O módulo File System (fs) fornece uma classe WriteStream que permite a criação de um fluxo gravável para transmitir dados para um destino designado. Ao utilizar o método fs.createWriteStream(), é possível estabelecer um novo fluxo e especificar o caminho de destino pretendido utilizando o parâmetro fornecido. Além disso, pode ser incluída uma matriz opcional de opções de configuração, se necessário.
const {createWriteStream} = require("fs");
(() => {
const file = "myFile.txt";
const myWriteStream = createWriteStream(file);
let x = 0;
const writeNumber = 10000;
const writeData = () => {
while (x < writeNumber) {
const chunk = Buffer.from(`${x}, `, "utf-8");
if (x === writeNumber - 1) return myWriteStream.end(chunk);
if (!myWriteStream.write(chunk)) break;
x\\+\\+
}
};
writeData();
})();
O código fornecido importa a função createWriteStream() , que é utilizada numa função de seta anónima para gerar um fluxo de ficheiro que acrescenta dados a um ficheiro especificado, neste caso, “myFile.txt”.Dentro da função anónima, existe uma função incorporada chamada writeData() , responsável por escrever informação no ficheiro designado.
A função createWriteStream() utiliza um buffer para inscrever uma série de números (de 0 a 9,999) no ficheiro de saída especificado. Quando executado, este script gera um ficheiro localizado no diretório atual e preenche-o com a informação seguinte:
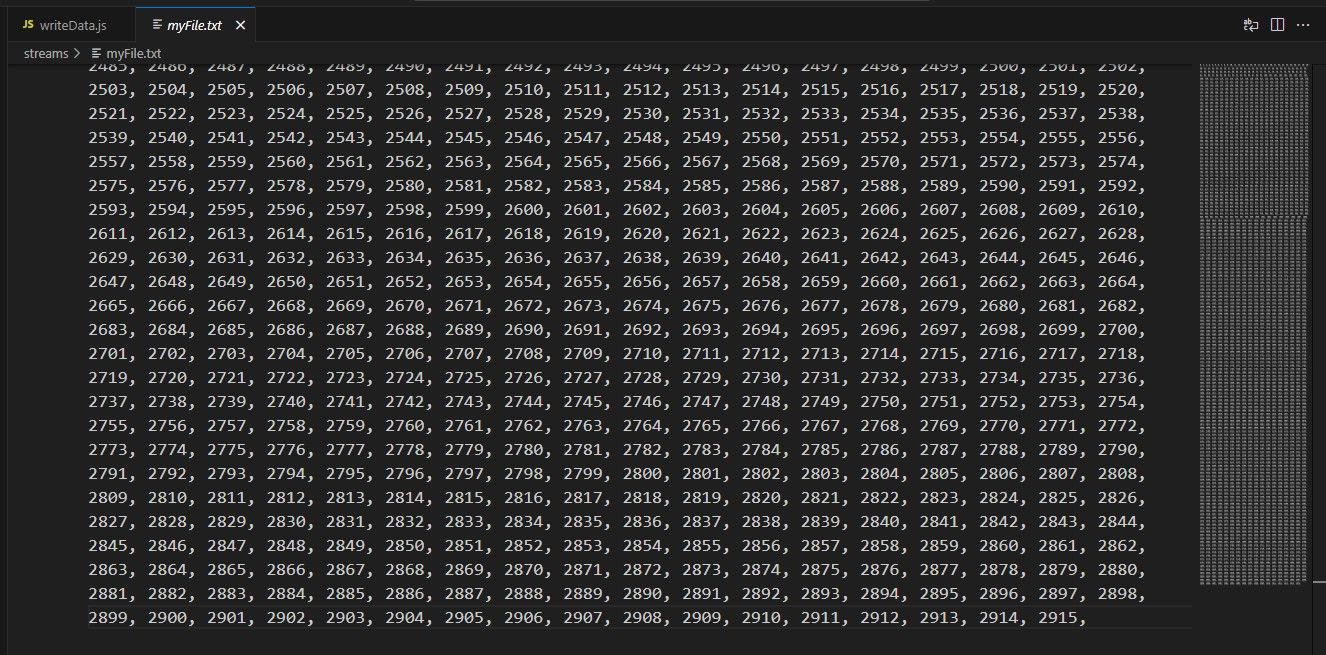
O presente conjunto de números termina em 2.915; no entanto, deveria englobar números até 9. Esta disparidade resulta do facto de cada WriteStream empregar uma cache que retém uma quantidade pré-determinada de informação num dado momento. Para saber qual é o valor padrão dessa configuração, é preciso consultar a opção highWaterMark.
console.log("The highWaterMark value is: " \\+
myWriteStream.writableHighWaterMark \\+ " bytes.");
A incorporação da instrução acima mencionada na função sem nome resultará na geração da mensagem subsequente no prompt de comando, como segue:
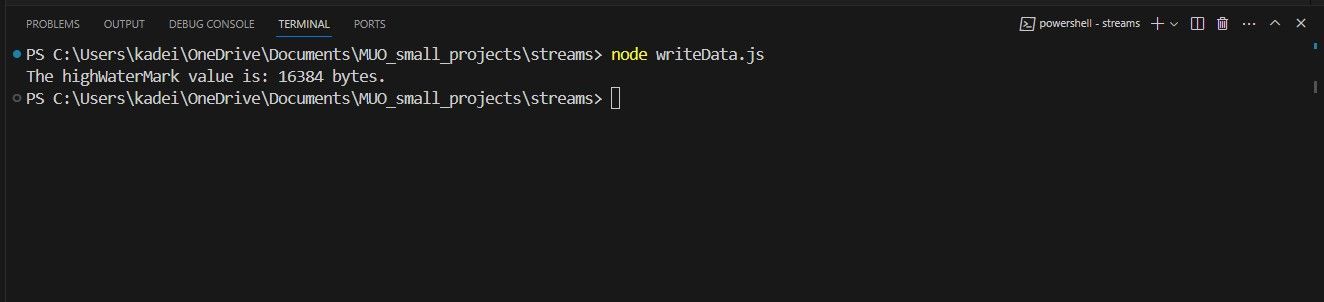
A saída exibida do terminal indica que o limite pré-configurado de highWaterMark está definido para 16.384 bytes por padrão. Consequentemente, ele restringe a capacidade desse buffer para acomodar não mais que 16.384 bytes de informação simultaneamente. Assim, os primeiros 2.915 caracteres (incluindo quaisquer vírgulas ou espaços), englobam o limite de dados que podem ser armazenados dentro do buffer de uma só vez.
Para resolver o problema dos erros de buffer, recomenda-se a utilização de um evento de fluxo. Os fluxos passam por vários eventos durante o processo de transmissão de dados que ocorrem em diferentes momentos. Entre esses eventos, o evento de drenagem é particularmente adequado para lidar com situações em que surgem erros de buffer.
Na implementação da função writeData() , a invocação do método write() do objeto WriteStream devolve um booleano que indica se o pedaço de dados atribuído ou a memória intermédia interna atingiu ou não o seu limiar pré-determinado, conhecido como “high water mark”. Se esta condição for satisfeita, significa que a aplicação é capaz de transmitir dados adicionais para o fluxo de saída associado. Inversamente, quando o método write() devolve um valor falso, o fluxo de controlo procede à drenagem de quaisquer dados remanescentes na memória intermédia, uma vez que não é possível continuar a escrever até que a memória intermédia seja esvaziada.
myWriteStream.on('drain', () => {
console.log("a drain has occurred...");
writeData();
});
A incorporação do código do evento de drenagem supramencionado numa função anónima permite o esvaziamento da memória intermédia do WriteStream quando esta atinge a sua capacidade máxima.Consequentemente, isto desencadeia a chamada do método writeData() para permitir a continuação da transmissão de dados. Ao executar o programa modificado, obtêm-se os seguintes resultados:
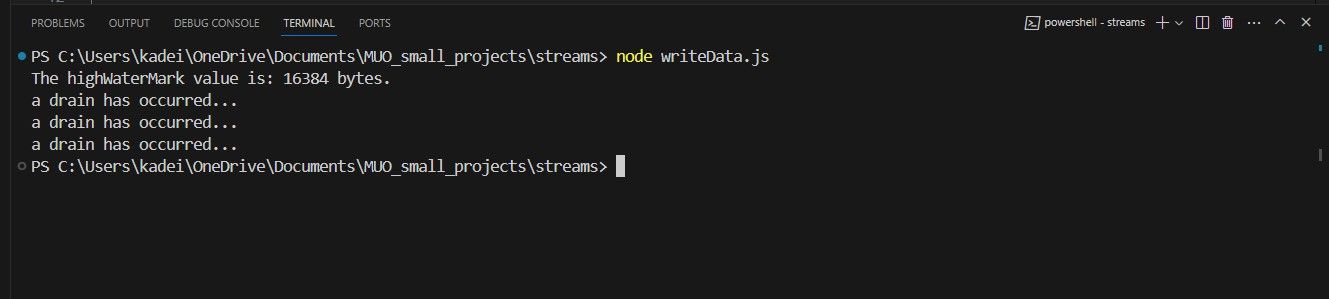
É importante ter em conta que a aplicação foi obrigada a limpar o buffer WriteStream em três ocasiões diferentes ao longo do seu funcionamento. Além disso, parece que o ficheiro de texto também sofreu algumas alterações.
Como criar e utilizar um fluxo legível
Para iniciar o processo de leitura de dados, comece por estabelecer um fluxo compreensível através da utilização da função fs.createReadStream() .
const {createReadStream} = require("fs");
(() => {
const file = "myFile.txt";
const myReadStream = createReadStream(file);
myReadStream.on("open", () => {
console.log(`The read stream has successfully opened ${file}.`);
});
myReadStream.on("data", chunk => {
console.log("The file contains the following data: " \\+ chunk.toString());
});
myReadStream.on("close", () => {
console.log("The file has been successfully closed.");
});
})();
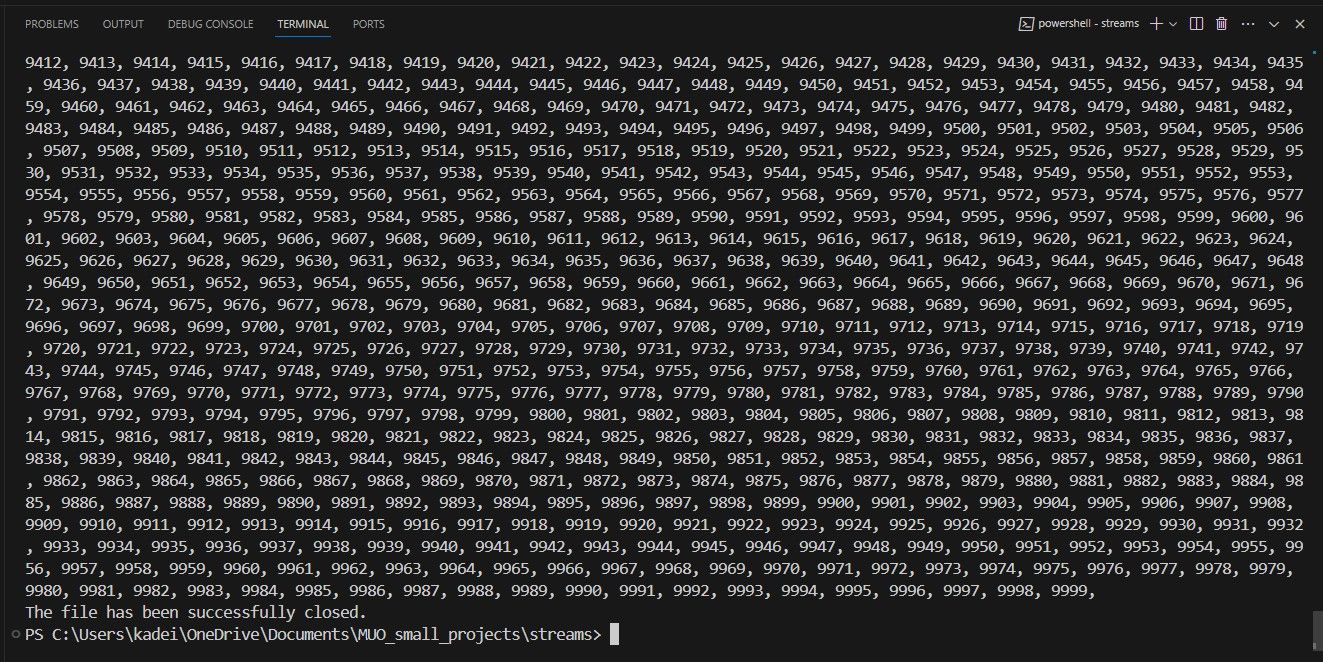
O script emprega a utilização do método createReadStream() para obter acesso ao ficheiro intitulado “myFile.txt” que foi previamente gerado por uma iteração de código anterior. Este método em particular recebe um caminho de ficheiro, que pode ser apresentado em formato de cadeia, buffer ou URL, juntamente com vários parâmetros opcionais como argumentos para processamento.
No contexto de uma função anónima relativa a fluxos, é de notar que existem várias ocorrências significativas relacionadas com fluxos. No entanto, é possível observar a ausência de qualquer indicação relativamente à ocorrência do evento “escoamento”. Este fenómeno pode ser atribuído ao facto de um fluxo legível tipicamente não armazenar dados em buffer até que a função “stream.push(chunk)” seja invocada ou o evento “readable” seja utilizado.
O disparo do evento open ocorre sempre que um ficheiro é aberto para leitura pelo utilizador. Ao associar o evento de dados a um fluxo inerentemente contínuo, o fluxo transita para um estado em que os dados podem ser transmitidos imediatamente após a sua disponibilidade. A execução do código fornecido gerará a seguinte saída:
Como criar e usar um fluxo duplex
Um fluxo duplex abrange os recursos de gravação e leitura, permitindo assim operações simultâneas de leitura e gravação na mesma instância. Um caso ilustrativo envolve a utilização do módulo net em conjunto com o estabelecimento de um socket TCP.
Um método simples para ilustrar as características de um canal de comunicação duplex envolve o desenvolvimento de um sistema de servidor e cliente do Protocolo de Controlo de Transmissão (TCP) capaz de trocar informações.
O ficheiro server.js
const net = require('net');
const port = 5000;
const host = '127.0.0.1';
const server = net.createServer();
server.on('connection', (socket)=> {
console.log('Connection established from client.');
socket.on('data', (data) => {
console.log(data.toString());
});
socket.write("Hi client, I am server " \\+ server.address().address);
socket.on('close', ()=> {
console.log('the socket is closed')
});
});
server.listen(port, host, () => {
console.log('TCP server is running on port: ' \\+ port);
});
O ficheiro client.js
const net = require('net');
const client = new net.Socket();
const port = 5000;
const host = '127.0.0.1';
client.connect(port, host, ()=> {
console.log("connected to server!");
client.write("Hi, I'm client " \\+ client.address().address);
});
client.on('data', (data) => {
console.log(data.toString());
client.write("Goodbye");
client.end();
});
client.on('end', () => {
console.log('disconnected from server.');
});
De facto, tanto o servidor como os scripts do cliente utilizam um fluxo legível e gravável para facilitar a comunicação, permitindo a troca de dados entre eles. Convenientemente, a aplicação do servidor é iniciada em primeiro lugar e começa a aguardar ativamente as ligações de entrada. Ao iniciar o cliente, este estabelece uma ligação com o servidor especificando
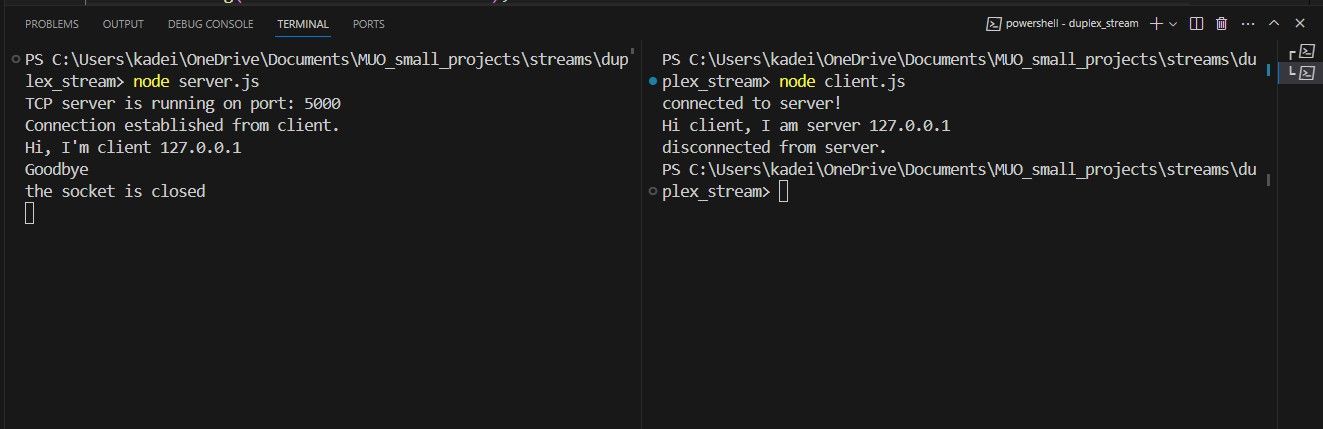
Ao estabelecer uma ligação, o cliente facilita a transmissão de dados utilizando o seu WriteStream para enviar informações para o servidor. Ao mesmo tempo, o servidor regista os dados recebidos no terminal antes de utilizar o seu próprio WriteStream para transmitir os dados de volta ao cliente. Posteriormente, o cliente regista os dados recebidos e continua a trocar mais informações, terminando depois a ligação. Neste ponto, o servidor mantém um estado aberto para acomodar quaisquer outras ligações de clientes.
Como criar e usar um fluxo de transformação
fluxos zlib e criptográficos. Os fluxos Zlib facilitam a compressão e a descompressão subsequente de ficheiros de texto durante as transferências de ficheiros, enquanto os fluxos criptográficos permitem uma comunicação segura através de operações de encriptação e desencriptação.
A aplicação compressFile.js
const zlib = require('zlib');
const { createReadStream, createWriteStream } = require('fs');
(() => {
const source = createReadStream('myFile.txt');
const destination = createWriteStream('myFile.txt.gz');
source.pipe(zlib.createGzip()).pipe(destination);
})();
Este script simples funciona pegando no documento de texto inicial, comprimindo-o e arquivando-o na pasta atual, devido à eficácia da funcionalidade pipe() do fluxo legível. A eliminação de buffers através da tecnologia de pipeline de fluxo facilita este procedimento.
Antes de os dados serem escritos no fluxo gravável do script, são submetidos a um pequeno desvio através do processo de compressão facilitado pelo método createGzip() da biblioteca zlib. O referido método gera uma versão comprimida do ficheiro e devolve uma nova instância de um objeto Gzip, que posteriormente se torna o destinatário do fluxo de escrita.
A aplicação decompressFile.js
const zlib = require('zlib');
const { createReadStream, createWriteStream } = require('fs');
(() => {
const source = createReadStream('myFile.txt.gz');
const destination = createWriteStream('myFile2.txt');
source.pipe(zlib.createUnzip()).pipe(destination);
})();
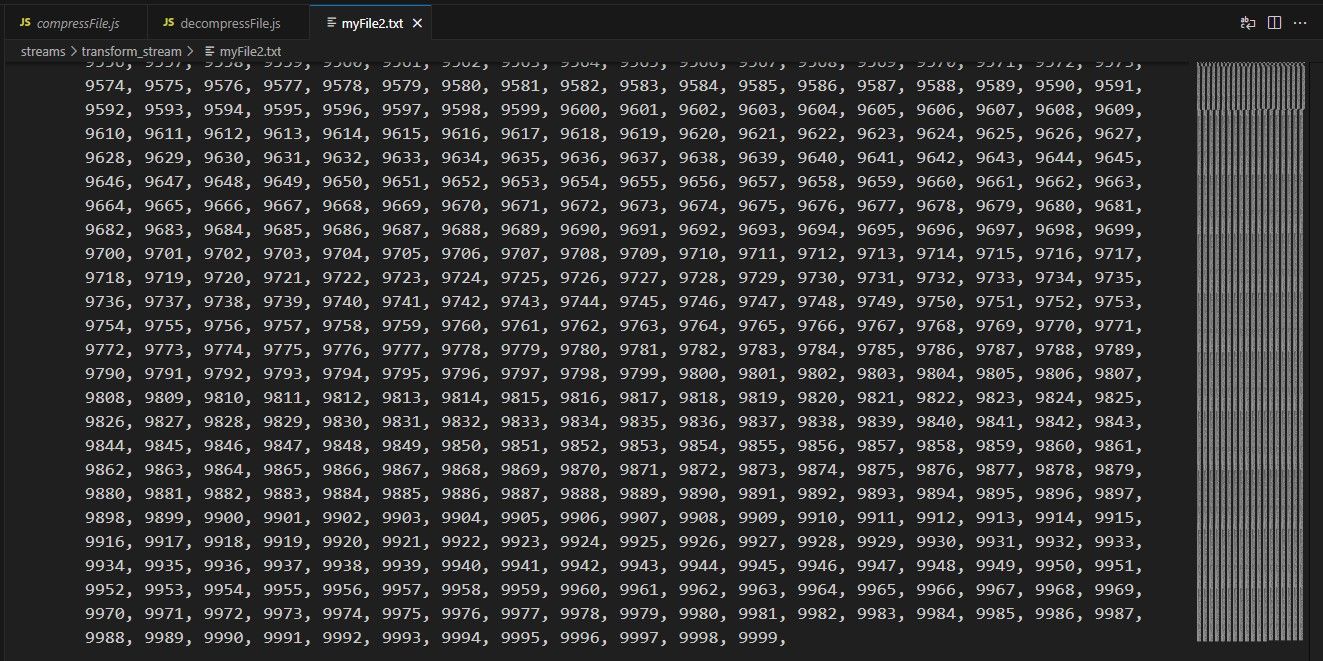
A aplicação atual expande o documento comprimido e, se alguém examinasse o novo ficheiro criado com o nome “myFile2.txt”, verificaria que o seu conteúdo corresponde exatamente ao do documento original.
Por que os fluxos são importantes?
Os fluxos desempenham um papel crucial na otimização da transmissão de dados, facilitando a comunicação entre os sistemas do cliente e do servidor, ao mesmo tempo que suportam a compressão e transferência eficientes de ficheiros de grandes dimensões.
Os fluxos melhoram significativamente a funcionalidade das linguagens de programação, simplificando o processo de transferência de dados. A ausência de uma caraterística de fluxo conduz a uma maior complexidade nas operações de transferência de dados, necessitando de um maior grau de intervenção manual por parte dos programadores, o que pode resultar num aumento de erros e numa diminuição do desempenho.