Como usar o pipeline de agregação no MongoDB
O pipeline de agregação é a maneira recomendada de executar consultas complexas no MongoDB. Se tem estado a utilizar o MapReduce do MongoDB, é melhor mudar para o pipeline de agregação para obter cálculos mais eficientes.
O que é agregação no MongoDB e como ela funciona?
O pipeline de agregação, também conhecido como pipeline “Agg”, é um mecanismo de consulta abrangente no MongoDB que facilita a análise e a manipulação de dados complexos. Utilizando uma série de estágios interconectados, esse pipeline permite que os usuários executem várias operações em seus conjuntos de dados, aproveitando a saída de um estágio como entrada para os estágios subsequentes. Esta ferramenta versátil permite aos utilizadores simplificar as suas tarefas de processamento de dados, melhorando simultaneamente a eficiência e a precisão globais.
Por exemplo, pode transmitir-se o resultado de um processo de correspondência a fases subsequentes para reorganização de acordo com a referida disposição até se obter o resultado preferido.
Ao longo de um pipeline de agregação, cada fase é constituída por um componente MongoDB e produz um ou mais documentos modificados como resultado. A frequência com que um determinado nível aparece no pipeline depende da natureza específica do inquérito que está a ser feito. Em alguns casos, pode ser necessário incorporar operadores como o
As etapas do pipeline de agregação
O pipeline de agregação passa os dados por várias etapas em uma única consulta. Existem várias etapas e pode encontrar os respectivos detalhes na documentação do MongoDB .
Vamos delinear alguns dos termos mais comuns nesse contexto.
A fase $match
A fase inicial deste processo permite estabelecer critérios precisos de seleção, que podem ser utilizados antes de iniciar quaisquer fases agregadoras subsequentes. Ao utilizar esta etapa preliminar, é possível identificar e isolar os elementos específicos do conjunto de dados que são considerados relevantes para inclusão no processo de agregação mais alargado.
A fase de agrupamento
A fase de agrupamento organiza a informação em categorias distintas utilizando emparelhamentos de valores-chave, com cada categoria a corresponder a um elemento no relatório final.
Considere os seguintes dados ilustrativos de amostra de vendas como um exemplo:
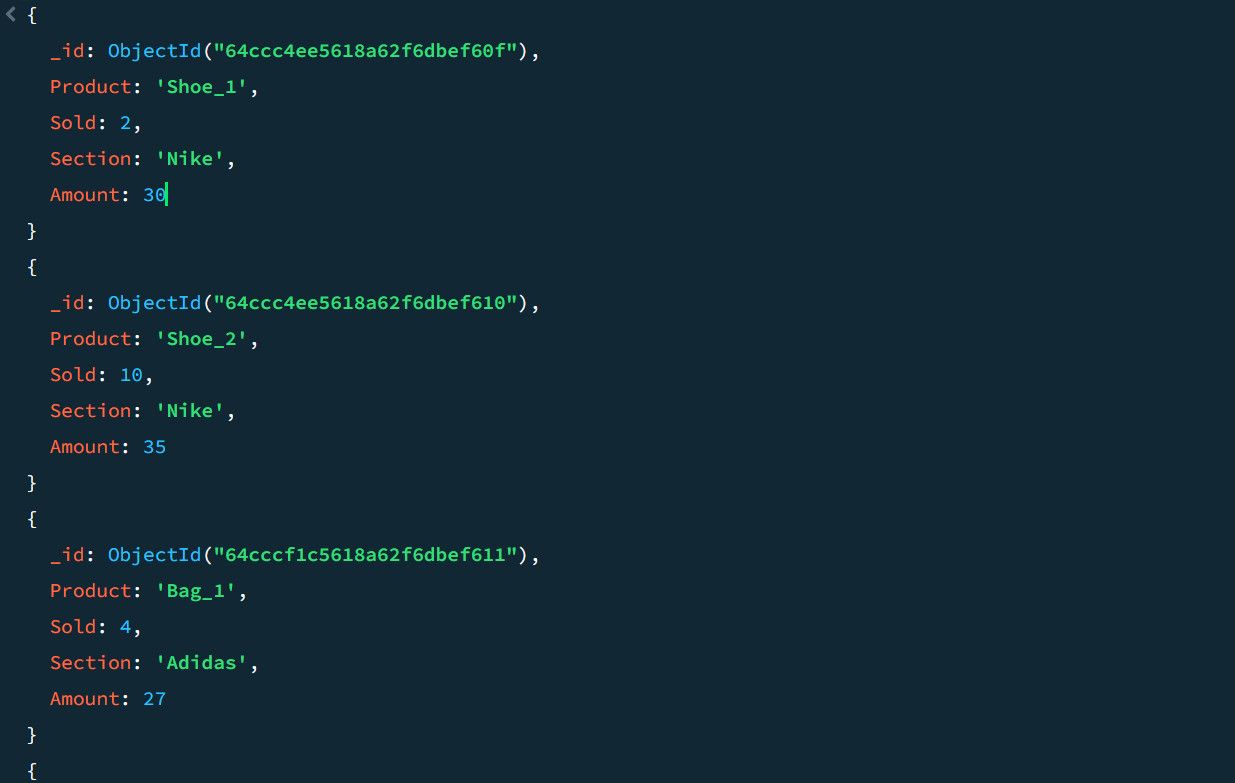
A utilização de um pipeline de agregação permite o cálculo da quantidade total de vendas e dos produtos que geram maior receita dentro de cada categoria respectiva.
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
A funcionalidade de agrupamento do MongoDB permite que os documentos sejam organizados de acordo com suas divisões seccionais. Isto é conseguido através da utilização do campo \_\ id em conjunto com uma chave especificada. Ao empregar operadores de agregação específicos, como \ \ sum, \ \ min, \ \ max ou \ \_avg, o MongoDB gera novos identificadores para cada grupo com base nas operações delineadas no agregador.
O estágio $skip
A utilização do estágio “$skip” em um pipeline de agregação permite a omissão de um número predeterminado de documentos do conjunto de resultados finais. Normalmente, esta fase é utilizada após a fase de agrupamento e serve para otimizar o resultado, excluindo os documentos que não são desejados. A título de exemplo, caso se preveja a produção de dois documentos, mas um deles tenha de ser eliminado, o processo de agregação produziria apenas o documento restante.
Para incorporar um passo de bypass no pipeline de agregação, pode introduzir a operação “$skip” no mesmo.
...,
{
$skip: 1
},
A etapa $sort
O processo de ordenação permite a organização da informação de forma descendente ou ascendente. Como ilustração, pode optar-se por reordenar o conjunto de dados do cenário de inquérito anterior com uma ordem de grandeza decrescente para discernir qual o departamento que apresenta o maior nível de vendas.
Modifique a consulta anterior incorporando o operador “$sort”, como segue:
...,
{
$sort: {top_sales: -1}
},
A etapa $limit
A utilização da operação “limit” facilita a redução dos documentos de saída desejados exibidos por um pipeline de agregação. Para ilustrar este conceito, considere a aplicação do operador “$limit” para recuperar a secção específica que foi identificada como tendo atingido o nível mais elevado de vendas numa fase anterior do processamento:
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}
O resultado acima mencionado produz apenas o documento inicial; este segmento em particular constitui a parte que apresenta a maior receita, uma vez que ocupa a posição mais alta dentro da lista de resultados organizada.
A diretiva $project Stage
A diretiva $project oferece um certo grau de flexibilidade no que diz respeito à formação do resultado final, permitindo a especificação dos campos desejados e dos nomes das chaves correspondentes.
De facto, considere-se um exemplo ilustrativo da saída, excluindo a fase “$project”, que pode ter o seguinte aspeto:

Para incorporar o projeto no nosso pipeline, vamos analisar o seu aspeto quando associado à etiqueta “$project”. Para conseguir esta integração, siga estes passos:
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
Tendo em conta a nossa organização anterior dos dados por categorias de produtos, a abordagem acima mencionada incorpora todas as secções de produtos relevantes no relatório gerado. Além disso, garante que tanto o valor global de vendas como o item mais vendido em destaque são integrados como parte do resultado final, representados respetivamente através das métricas “Total vendido” e “Top de vendas”.
O resultado revisto apresenta um maior grau de refinamento quando comparado com o seu antecessor, mostrando uma melhor organização e clareza na apresentação.

A etapa $unwind
A etapa unwind do MongoDB é responsável por desconstruir uma matriz contida num único documento e transformá-la em vários documentos. A título de ilustração, consideremos o seguinte conjunto de dados de pedidos de amostra:
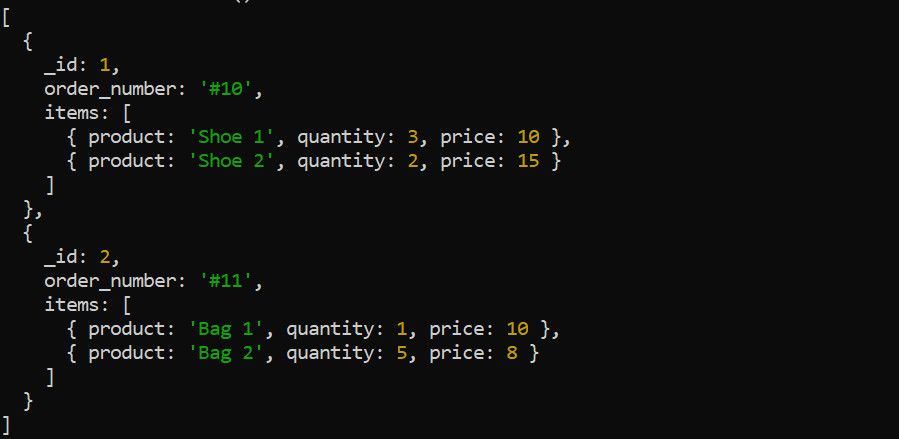
A utilização da etapa $unwind é um método eficaz de desmontar a matriz de itens antes de implementar operações de agregação adicionais. Esta etapa revela-se particularmente útil quando se tenta calcular uma estatística resumida para cada elemento da matriz. Como exemplo ilustrativo, considere o cálculo da receita agregada gerada por produtos individuais.
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
])
Certamente, aqui está uma versão mais refinada do resultado gerado pela consulta agregada mencionada anteriormente:

Como criar um pipeline de agregação no MongoDB
As etapas mencionadas acima fornecem uma compreensão abrangente do processo de aplicação de várias operações dentro do pipeline de agregação, abrangendo consultas fundamentais associadas a cada etapa.
Permita-me fornecer uma versão mais refinada do texto dado: À luz de nossa análise do conjunto de dados de vendas anterior, é prudente apresentar uma visão geral de vários estágios principais do pipeline de agregação como um todo. Ao fazê-lo, podemos obter uma perspetiva abrangente do processo envolvido na transformação de dados brutos em informações significativas.
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])
O produto final tem uma semelhança impressionante com algo que já foi encontrado antes, evocando sentimentos de familiaridade e talvez até deja vu.
Pipeline de agregação vs. MapReduce
Antes de ser removido a partir da versão 5.0 do MongoDB, o método tradicional para realizar agregações de dados dentro do banco de dados era através da utilização do MapReduce. Embora o MapReduce possua uma gama de usos potenciais fora do MongoDB, ele é geralmente considerado menos eficiente em comparação com o pipeline de agregação, necessitando do uso de scripts externos para definir individualmente os processos de mapeamento e redução.
Por outro lado, o pipeline de agregação no MongoDB oferece um método exclusivo para executar consultas complexas, mantendo maior eficiência e organização em comparação com outras abordagens. Além disso, esse pipeline incorpora recursos adicionais que permitem maior personalização da saída resultante.
A transição do MapReduce para o pipeline de agregação apresenta uma infinidade de distinções que podem ser encontradas durante esse processo.
Tornar as consultas de Big Data eficientes no MongoDB
Para processar com eficácia as informações complexas armazenadas no MongoDB, é crucial otimizar as consultas para obter a máxima eficiência. Felizmente, o pipeline de agregação oferece uma excelente solução para a execução de cálculos abrangentes em conjuntos de dados complexos. Ao contrário das operações individualizadas que frequentemente comprometem o desempenho, a estrutura de agregação permite que os usuários otimizem várias etapas de processamento em um pipeline único e altamente eficiente. Ao fazê-lo, estas tarefas complicadas podem ser executadas com maior velocidade e precisão de uma forma unificada.
A utilização da indexação pode melhorar significativamente o desempenho das operações de agregação no MongoDB, pois reduz o volume de dados que devem ser verificados em cada etapa do processo.