Como criar um chatbot usando Streamlit e Llama 2
O Llama 2 é um modelo de língua grande de código aberto que foi desenvolvido pela Meta. Este modelo em particular possui capacidades impressionantes, tornando-o um concorrente formidável em comparação com outros modelos fechados, como o GPT-3.5 e o PaLM. De facto, muitos especialistas defendem que o Llama 2 ultrapassa estas alternativas em termos de desempenho. A arquitetura deste modelo inclui três modelos de texto generativos distintos, pré-treinados e ajustados, cada um com diferentes níveis de complexidade. Estes modelos incluem versões com 7 mil milhões, 13 mil milhões e 70 mil milhões de parâmetros, respetivamente.
Aprofunde o potencial dialógico da Llama 2, construindo um chatbot que utiliza o Streamlit e as capacidades da Llama 2 para interagir com os utilizadores em tempo real.
Compreender a Llama 2: características e vantagens
Quão divergente é a Llama 2, a mais recente iteração do modelo de linguagem de grande dimensão, em comparação com a sua versão anterior, a Llama 1?
O modelo aumentado apresenta uma arquitetura significativamente expandida, abrangendo até 70 mil milhões de parâmetros. Um número tão alargado de parâmetros facilita a aquisição de relações cada vez mais complexas inerentes às sequências de palavras.
A Aprendizagem por Reforço a partir do Feedback Humano (RLHF) demonstrou a sua eficácia no aumento das capacidades das aplicações de conversação, resultando em respostas mais naturais e convincentes que podem ser geradas numa vasta gama de diálogos complexos. A incorporação de RLHF nestes modelos não só melhora a sua capacidade de compreender o contexto, como também lhes permite dar respostas mais coerentes e relevantes, proporcionando assim uma melhor experiência ao utilizador.
A introdução da técnica inovadora conhecida como “atenção a consultas agrupadas” acelerou significativamente o processo de inferência, permitindo assim o desenvolvimento de aplicações altamente funcionais, como os chatbots e os assistentes virtuais.
A versão atual apresenta um nível superior de eficiência no que diz respeito à utilização da memória e dos recursos computacionais, em comparação com a sua iteração anterior.
O Llama 2 está licenciado ao abrigo de um quadro de código aberto e não comercial, que permite aos investigadores e programadores utilizar e modificar livremente as suas funcionalidades, sem quaisquer restrições ou limitações impostas por interesses comerciais.
O Llama 2 apresenta um desempenho superior em vários aspectos, em comparação com a sua iteração anterior, o que o torna um instrumento excecionalmente robusto para inúmeras utilidades, incluindo interacções com chatbots, ajudantes virtuais e compreensão de linguagem natural.
Configurando um ambiente Streamlit para desenvolvimento de chatbot
Para começar a construir seu aplicativo, é necessário estabelecer um ambiente de desenvolvimento que sirva para separar seu projeto atual de quaisquer projetos preexistentes armazenados no seu dispositivo.
Para começar, estabeleça um ambiente virtual utilizando a biblioteca Pipenv da seguinte maneira:
pipenv shell
De seguida, vamos proceder à instalação dos componentes de software necessários para construir o agente de conversação.
pipenv install streamlit replicate
Streamlit é uma estrutura de desenvolvimento de aplicações Web versátil e de código aberto concebida para facilitar a rápida implementação de projectos de aprendizagem automática e de ciência de dados.
Na sua essência, “Replicate” refere-se a uma plataforma de computação em nuvem que oferece aos utilizadores acesso a uma vasta gama de modelos de aprendizagem automática de código aberto que podem ser facilmente implementados e utilizados em várias aplicações.
Obtenha o seu token da API Llama 2 a partir do Replicate
Para obter uma chave de token do Replicate, deve primeiro registar uma conta no Replicate utilizando a sua conta GitHub.
O Replicate só permite o login por meio de uma conta do GitHub .
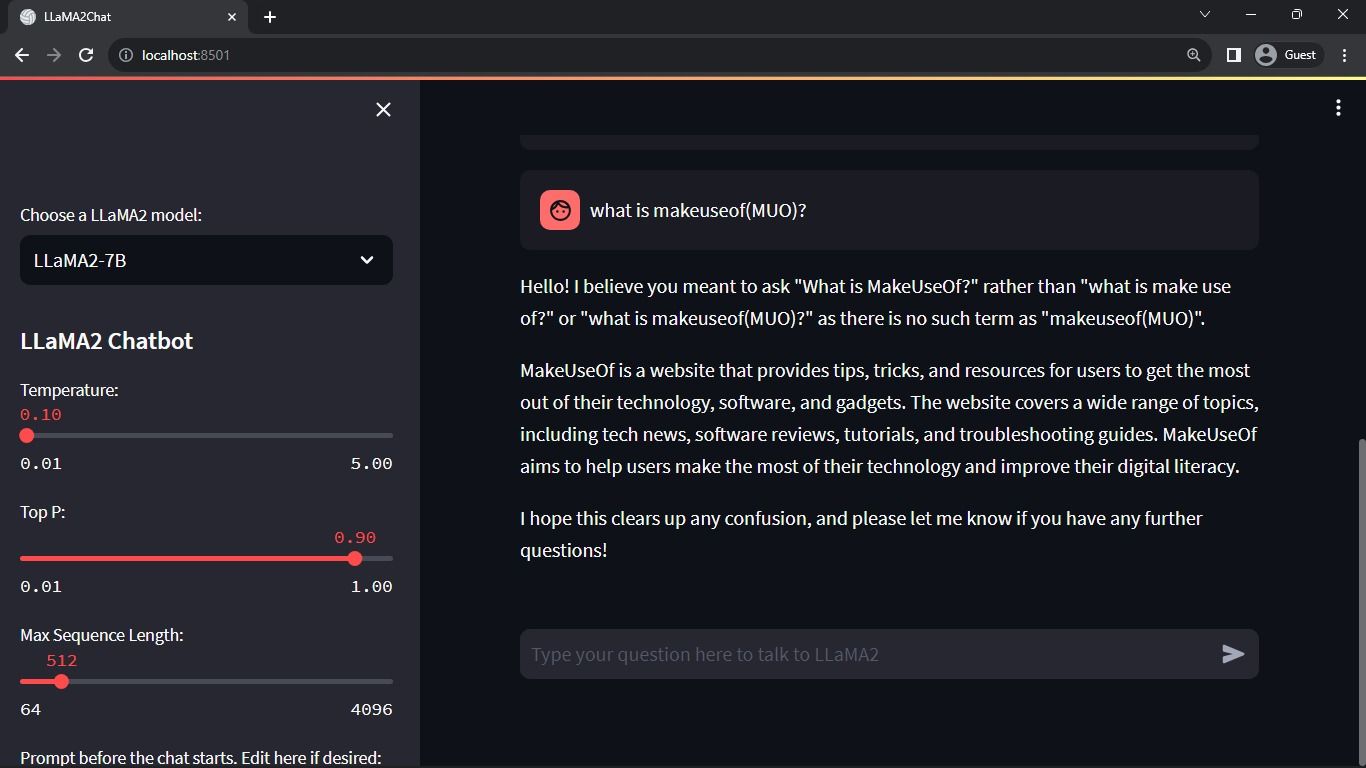
Ao aceder ao painel de controlo, vá para o separador “Explorar” e localize a barra de pesquisa. Introduza “Llama 2 chat” no campo de pesquisa para ver o modelo específico denominado “llama-2-70b-chat”.
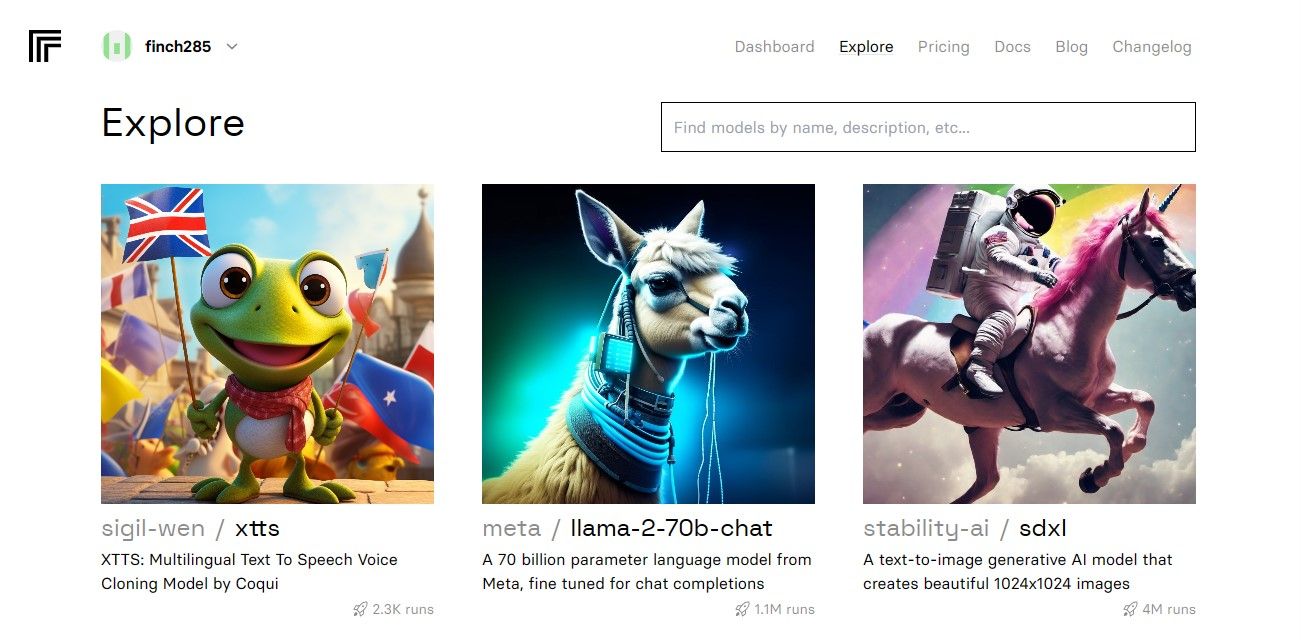
Seleccione a opção “Llama 2 API Endpoint” no menu pendente e clique nela. Depois de o ter feito, navegue até à secção “API Token”. Aqui, encontrará um botão designado por “Python Application” (Aplicação Python). Ao clicar neste botão, terá acesso às credenciais necessárias para utilizar a API Llama 2 nos seus projectos Python.
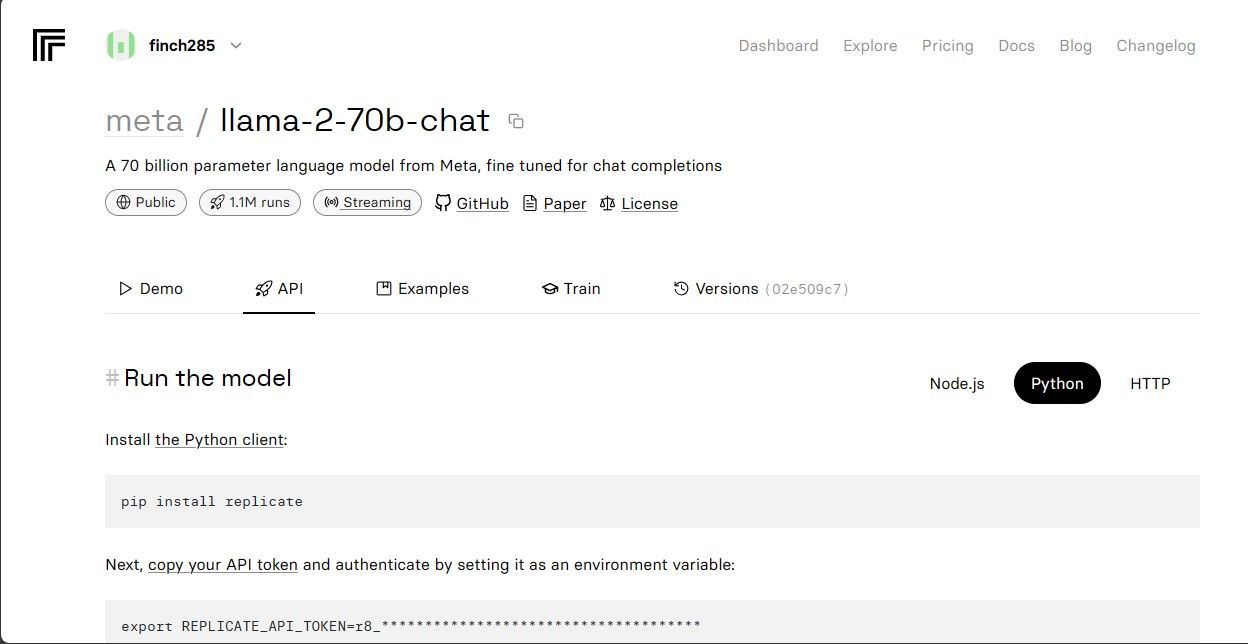
Copie o token da API para efeitos de replicação e assegure o seu armazenamento seguro para utilização futura.
O código-fonte completo pode ser acedido através do nosso repositórioGitHub, que fornece um recurso abrangente para os programadores utilizarem e contribuírem para o projeto.
Construir o Chatbot
Para começar a desenvolver o Llama Chatbot, gere inicialmente dois ficheiros separados - um chamado “llama\_chatbot.py”, que serve como script principal para implementar a funcionalidade do chatbot, e outro ficheiro intitulado “.env”, concebido especificamente para alojar informação sensível, como chaves secretas e tokens API necessários para o funcionamento adequado. Ao aderir a esta configuração inicial, pode isolar eficazmente os dados sensíveis do código-fonte principal, assegurando simultaneamente uma integração perfeita com serviços externos.
Para utilizar várias funcionalidades dentro do script llama_chatbot.py , é necessário importar várias bibliotecas. O processo de importação destas bibliotecas envolve a especificação dos respectivos nomes e a garantia de que estão devidamente integradas na base de código existente. Isto permite um funcionamento sem problemas e a execução da funcionalidade pretendida para o chatbot.
import streamlit as st
import os
import replicate
A seguir, vamos estabelecer os parâmetros globais do modelo de linguagem “llama-2-70b-chat”, inicializando as variáveis associadas.
# Global variables
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default='')
# Define model endpoints as independent variables
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default='')
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default='')
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default='')
Para incorporar os tokens da API Replicate e as informações do modelo nas variáveis de ambiente da sua aplicação, deve anexar os detalhes relevantes ao ficheiro “.env” utilizando uma estrutura de formatação específica. Isto permitirá uma integração perfeita destes componentes no seu projeto.
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Reproduza o token fornecido e certifique-se de que guardou o ficheiro .env correspondente.
Projetando o fluxo de conversação do Chatbot
O processo de iniciar o uso do modelo de linguagem do Llama 2 para tarefas específicas pode ser facilitado pela geração de um prompt preliminar que descreve o objetivo desejado. Por exemplo, se o objetivo é utilizar o modelo na qualidade de assistente, então a formulação de uma declaração de iniciação adequada implicaria especificar essa intenção e, potencialmente, delinear quaisquer áreas específicas de enfoque ou conhecimentos especializados necessários para desempenhar o papel de forma eficaz. Ao fornecer instruções claras desde o início, a interação subsequente com o assistente virtual alimentado por IA será mais eficiente e precisa.
# Set Pre-propmt
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."
A configuração da página de um chatbot pode ser organizada de várias formas, consoante o aspeto e a funcionalidade pretendidos. Algumas considerações importantes a ter em conta incluem elementos de design, tais como esquemas de cores, escolhas de tipos de letra e opções de disposição. Além disso, é importante determinar que informações ou funcionalidades serão apresentadas na página, incluindo quaisquer componentes interactivos, como botões ou formulários. Os detalhes específicos do arranjo podem variar com base nas preferências e requisitos individuais, mas a existência de um plano claro pode ajudar a garantir que o resultado final cumpre as metas e os objectivos pretendidos.
# Set initial page configuration
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Iniciar e estabelecer configurações de variáveis específicas da sessão através da implementação de um procedimento funcional.
# Constants
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
# Session State Variables
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPT
def setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
O processo acima mencionado configura os parâmetros cruciais, tais como chat_dialogue , pre_prompt , llm , top_p , max_seq_len , e temperature dentro do estado da sessão. Além disso, facilita a seleção do modelo Llama 2 preferido, de acordo com as preferências do utilizador.
Eis um exemplo de como pode criar uma função em Python que processa o conteúdo da barra lateral da sua aplicação Streamlit:pythondef render_sidebar():# O código para gerar o código HTML para a barra lateral vai para aquieturn “O conteúdo da sua barra lateral vai para aqui”
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt \\+ "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
O componente acima mencionado apresenta o cabeçalho e os parâmetros de configuração que podem ser modificados para otimizar o desempenho do chatbot Llama 2, facilitando os ajustes necessários para uma funcionalidade óptima.
Eis uma implementação possível para apresentar o histórico do chat na área de conteúdo principal da aplicação Streamlit utilizando HTML e CSS:pythonimport streamlit as stfrom transformers import GPT2LMHeadModel, GPT2Tokenizerfrom streamlit_chat import message# Carregar o modelo ajustado e o tokenizermodel = GPT2LMHeadModel.from_pretrained(‘meditations_model’)tokenizer = GPT2Tokenizer. from_pretrained(‘meditations_model’)# Definir a função chatbotdef chatbot(text):input_ids = tokenizer.encode(text, return_tensors=‘pt’)output = model. generate(input_ids=input_ids, max_length=
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
O método percorre o objeto chat_dialogue armazenado no estado da sessão, exibindo cada comunicação trocada entre o utilizador e o assistente, acompanhada do respetivo identificador de papel (ou “utilizador” ou “assistente”).
O fragmento de código fornecido parece ser um espaço reservado para uma função que processa a entrada do utilizador, mas não é fornecida qualquer implementação real. Para tratar a entrada do utilizador de uma forma mais sofisticada, seria necessário definir e implementar um algoritmo ou lógica adequados na função, com base nos requisitos específicos da sua aplicação.
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
A componente de apresentação fornece uma interface de introdução de texto para os utilizadores, permitindo-lhes submeter mensagens ou questões no contexto da conversação. Após a receção da entrada do utilizador, acrescenta a mensagem ao diálogo em curso armazenado como parte dos dados específicos da sessão, que inclui metadados que especificam o papel do participante como “utilizador” ou “bot”.
Eis um exemplo de como se pode implementar esta funcionalidade utilizando Python e a biblioteca Hugging Face Transformers:pythonfrom transformers import LlamaTokenizer, LlamaForCausalLMimport torchdef generate_responses(input_text):# Carrega o tokenizador e o modeltokenizer pré-treinados da Llama = LlamaTokenizer.from_pretrained(‘facebook/llama-base’)model = LlamaForCausalLM. from_pretrained(‘facebook/llama-base’)# Codificar o texto de entrada como IDs de entradainputs = tokenizer(input_text, return_tensors=‘pt’).input_ids# Gerar
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue \\+= f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue \\+ "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response \\+= item
message_placeholder.markdown(full_response \\+ "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
O sistema gera um arquivo de comunicações passadas, englobando tanto a entrada humana como a da IA, antes de invocar o processo de replicação diferida. Isto permite uma experiência de diálogo sem falhas, actualizando dinamicamente a interface com a resposta mais recente da IA.
A principal tarefa desta aplicação é renderizar todos os componentes da estrutura Streamlit, que serve como uma interface abrangente para os utilizadores.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
A aplicação emprega uma sequência organizada de operações para estabelecer o status quo da sessão, apresentar o painel lateral, registar as conversas, processar as entradas dos utilizadores e produzir respostas auxiliares utilizando todas as funções previamente definidas.
Eis um exemplo de como pode modificar a sua função main() em index.js para utilizar a função renderApp() e iniciar a aplicação quando o script é executado:javascriptasync function main() {const app = createContext(null); // Criar o contexto do Provider com valor inicial nulo// Envolver a função renderApp com um bloco try-catch para tratamento de errostry {renderApp(app, document.getElementById(‘root’));} catch (err) {console.error( Erro ao executar o componente raiz:\n${err. stack} );}}// Chame a função principal para executar a aplicaçãomain();Este código cria uma nova instância do contexto do fornecedor passando null
def main():
render_app()
if __name__ == "__main__":
main()
A sua aplicação está agora preparada e equipada para implantação, permitindo que seja executada com facilidade.
Tratamento de pedidos de API
Para implementar a funcionalidade solicitada, é necessário criar um novo módulo Python chamado “utils.py” no diretório principal do projeto. Este módulo irá conter uma única função que executa a tarefa especificada. Abaixo está um exemplo de como isto pode ser conseguido:pythondef some_function():# O código da função vai aqui…
import replicate
import time
# Initialize debounce variables
last_call_time = 0
debounce_interval = 2 # Set the debounce interval (in seconds)
def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)
current_time = time.time()
elapsed_time = current_time - last_call_time
if elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."
last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt \\+ "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
A funcionalidade incorpora um mecanismo de debouncing para mitigar o risco de pedidos de API demasiado frequentes e pródigos resultantes da interação de um utilizador, assegurando assim uma utilização prudente dos recursos.
Incorpore a função de resposta debouncing no script llama_chatbot.py implementando os seguintes passos:
from utils import debounce_replicate_run
Agora, execute o aplicativo:
streamlit run llama_chatbot.py
Saída esperada:
A interação apresentada neste resultado é um diálogo entre um modelo de linguagem de IA e um utilizador humano.
Aplicações do mundo real dos Chatbots Streamlit e Llama 2
Podem ser observados vários exemplos de utilização prática do software Llama 2 em vários sectores, tais como
Os chatbots são uma ferramenta versátil utilizada para desenvolver agentes interactivos capazes de conduzir discussões em tempo real sobre uma série de assuntos, aproveitando o processamento de linguagem natural e os algoritmos de inteligência artificial para fornecer respostas relevantes com base na entrada do utilizador.
Incorporando tecnologia de compreensão da linguagem natural, esta ferramenta foi concebida para desenvolver agentes de conversação capazes de compreender e responder à comunicação humana de uma forma que imita a interação humana.
A utilização da tecnologia de tradução de línguas limita-se à tradução de línguas em várias tarefas linguísticas.
A sumarização de um texto consiste em condensar um texto longo numa versão mais curta e concisa que retenha o seu significado essencial e os pontos-chave, eliminando os pormenores desnecessários. Este processo pode ser útil em vários contextos, como o jornalismo, trabalhos de investigação ou redes sociais, onde o acesso rápido à informação é crucial. Ao apresentar apenas os aspectos mais importantes de um determinado tópico, o resumo permite que os leitores apreendam eficazmente as ideias principais sem terem de ler um documento inteiro, palavra por palavra.
A aplicação da Llama 2 para fins de investigação implica responder a pedidos de informação sobre uma série de assuntos.
O futuro da IA
O desafio colocado pelo elevado custo associado à utilização de grandes modelos linguísticos, como os do GPT-3.5 e do GPT-4, limitou a capacidade das entidades mais pequenas de construírem aplicações dignas de nota, uma vez que a obtenção de acesso à API destes modelos tem muitas vezes um custo considerável.
A revelação de estruturas linguísticas poderosas, como a Llama 2, à comunidade de desenvolvimento marca o início de uma nova época na inteligência artificial. Esta eventualidade fomentará a utilização inventiva e imaginativa destes sistemas em cenários práticos, impulsionando assim o progresso no sentido da obtenção da superinteligência artificial a um ritmo acelerado.