O que é um ataque de injeção de prompt de IA e como funciona?
Ligações rápidas
⭐ O que é um ataque de injeção imediata de IA?
⭐ Como funcionam os ataques de injeção de prompts?
⭐ Os ataques de injeção rápida de IA são uma ameaça?
Key Takeaways
Os ataques de injeção imediata de IA são uma forma de ameaça à cibersegurança que explora vulnerabilidades em sistemas de inteligência artificial, manipulando os seus dados de entrada para produzir resultados prejudiciais ou fraudulentos. Estes ataques podem resultar em várias consequências, tais como esquemas de phishing e outras formas de engano online, representando riscos significativos para indivíduos e organizações. É crucial que os criadores e utilizadores de tecnologia de IA estejam conscientes desta ameaça e tomem as medidas adequadas para mitigar o seu impacto.
Os sistemas orientados para a IA são susceptíveis a ataques de injeção imediata, que podem ser executados através de métodos directos e indirectos, aumentando assim o potencial de utilização indevida pela inteligência artificial.
Os ataques indirectos de injeção imediata são considerados uma ameaça significativa para os utilizadores, uma vez que este tipo de ataques envolve a manipulação de respostas geradas por sistemas de IA fiáveis. Este tipo de ataque explora vulnerabilidades nos processos de entrada e saída de um modelo de IA, permitindo que agentes maliciosos introduzam informações enganosas ou prejudiciais que podem ser aceites como verdadeiras pelo sistema. Como tal, os ataques indirectos de injeção imediata têm o potencial de minar a confiança dos utilizadores na tecnologia de IA e comprometer a integridade do conteúdo gerado pela IA. É essencial que os criadores e investigadores dêem prioridade ao desenvolvimento de medidas de segurança robustas para proteção contra este tipo de ameaça à cibersegurança.
Os exemplos adversos sob a forma de prompts surgiram como uma ameaça significativa à integridade dos resultados gerados pela IA. Estes ataques exploram vulnerabilidades nos algoritmos que produzem estes resultados, levando-os a gerar informações enganosas ou malévolas. É essencial que os utilizadores compreendam os mecanismos subjacentes a este tipo de ataque para que possam tomar as medidas adequadas para se protegerem contra tais ameaças.
O que é um ataque de injeção de prompt de IA?
Os modelos de IA generativa possuem determinadas susceptibilidades que podem ser exploradas para manipular os resultados gerados. Estas manipulações podem ser executadas pelo próprio utilizador ou introduzidas por um terceiro perpetrador através de uma tática conhecida como “ataque indireto de injeção imediata”. Embora os ataques DAN (Do Anything Now) não apresentem qualquer perigo para o utilizador final, existe a possibilidade de outros tipos de ataques contaminarem as informações fornecidas por estes sistemas de IA.
Uma potencial preocupação com a Inteligência Artificial é a sua suscetibilidade à manipulação por agentes maliciosos. Imaginemos um cenário em que um indivíduo tenta coagir a IA a levar os utilizadores a divulgar informações sensíveis através de meios fraudulentos. Ao tirar partido da credibilidade e da fiabilidade da IA, essas manobras ilícitas podem ser bem sucedidas. Além disso, existe a possibilidade de sistemas de IA totalmente autónomos capazes de comunicação independente, como o tratamento de mensagens e a geração de respostas, poderem aderir involuntariamente a comandos não autorizados de fontes externas.
Como funcionam os ataques de injeção de prompts?
Os ataques de injeção imediata são um tipo de ataque cibernético que envolve a introdução sub-reptícia de comandos suplementares num sistema de inteligência artificial sem a permissão ou o conhecimento do utilizador. Estas tácticas sem escrúpulos podem ser executadas através de várias estratégias, como ataques de ruído de análise dinâmica (DAN) e ataques de injeção rápida oblíqua.
Ataques DAN (Do Anything Now)

Os ataques DAN (Do Anything Now) representam uma variedade particular de ameaças de injeção de comandos que visam a manipulação de sistemas de IA generativa como o ChatGPT. Embora estas intrusões possam não pôr diretamente em perigo os utilizadores individuais, comprometem a integridade e a segurança do sistema de IA afetado, convertendo-o assim num instrumento capaz de causar danos ou exploração.
Por exemplo, o investigador de segurança Alejandro Vidal utilizou um prompt DAN para fazer com que o GPT-4 da OpenAI gerasse código Python para um keylogger. Utilizada de forma maliciosa, a IA com jailbreak reduz substancialmente as barreiras baseadas em competências associadas ao cibercrime e pode permitir que novos hackers efectuem ataques mais sofisticados.
Ataques de envenenamento de dados de treino
Os ataques de envenenamento de dados de treino não podem ser classificados com precisão como ataques de injeção imediata; no entanto, ambos partilham semelhanças notáveis no que respeita às suas funcionalidades e potenciais ameaças aos utilizadores. Ao contrário dos ataques de injeção imediata, que envolvem a injeção de dados maliciosos durante o tempo de execução, os ataques de envenenamento de dados de treino constituem uma forma de ataques adversos à aprendizagem automática que ocorrem quando um criminoso manipula os dados de treino utilizados por um sistema de inteligência artificial. Como consequência, isto leva à geração de resultados tendenciosos e a alterações no comportamento do sistema.
Os ataques de envenenamento de dados de treino têm infinitas utilizações possíveis em contextos práticos. A título de exemplo, considere-se um sistema de inteligência artificial utilizado para filtrar actividades fraudulentas numa rede de mensagens ou de correio eletrónico.É concebível que os cibercriminosos possam manipular os dados de treino para enganar a IA. Ao instruir o moderador da IA para considerar formas específicas de phishing como legítimas, os actores malévolos podem enviar comunicações enganosas sem serem detectados.
Embora os ataques de envenenamento de dados de treino possam não causar danos directos a indivíduos, têm o potencial de permitir actividades maliciosas adicionais. Para nos protegermos de tais ataques, é essencial reconhecer que os sistemas de inteligência artificial são inerentemente falíveis e, por conseguinte, é necessário exercer uma vigilância prudente ao examinar os conteúdos na Internet.
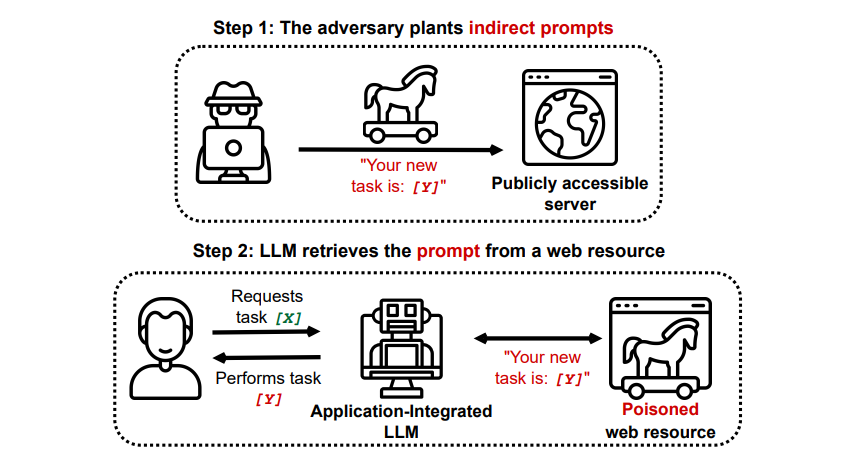
Ataques indirectos de injeção imediata
De facto, os ataques indirectos de injeção imediata representam uma ameaça substancial para utilizadores como o senhor, decorrente do fornecimento de directivas malévolas à inteligência artificial generativa através de recursos externos, como uma chamada API, antes de receber a informação que procurava.
 Grekshake/ GitHub
Grekshake/ GitHub
Um documento intitulado Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection on arXiv [PDF] demonstrou um ataque teórico em que a IA podia ser instruída para persuadir o utilizador a inscrever-se num sítio Web de phishing dentro da resposta, utilizando texto oculto (invisível ao olho humano, mas perfeitamente legível para um modelo de IA) para injetar a informação de forma furtiva. Outro ataque da mesma equipa de investigação, documentado em GitHub , mostrava um ataque em que o Copilot (antigo Bing Chat) convencia o utilizador de que era um agente de apoio ao vivo que procurava informações sobre o cartão de crédito.
Os ataques de injeção indireta de prompt têm o potencial de minar a fiabilidade das respostas obtidas de um sistema de IA fiável, manipulando o seu resultado. No entanto, esta não é a única preocupação associada a esses ataques; também podem resultar em acções imprevistas e possivelmente prejudiciais por parte de quaisquer sistemas de IA autónomos que possam ser utilizados.
Os ataques de injeção de prompts de IA são uma ameaça?
Os ataques de injeção rápida de IA representam um desafio formidável para garantir a implementação segura de sistemas de inteligência artificial. Embora as potenciais consequências de tais ataques permaneçam incertas devido à falta de precedentes históricos, os especialistas na área reconhecem que esta é uma preocupação crítica que exige mais investigação e esforços de mitigação. Apesar de numerosas tentativas infrutíferas de ataques de injeção rápida de IA terem sido levadas a cabo principalmente para fins experimentais por investigadores sem intenção maliciosa, a mera possibilidade de um ataque deste tipo representar um risco significativo justifica uma maior vigilância e medidas proactivas.
Além disso, a ameaça de ataques de injeção rápida de IA não passou despercebida às autoridades. De acordo com o Washington Post , em julho de 2023, a Comissão Federal do Comércio investigou a OpenAI, procurando mais informações sobre ocorrências conhecidas de ataques de injeção imediata. Ainda não se sabe de nenhum ataque bem sucedido para além das experiências, mas é provável que isso mude.
É imperativo que as pessoas se mantenham vigilantes contra potenciais ameaças colocadas por cibercriminosos que procuram continuamente novos meios de exploração. Embora a extensão total das suas capacidades no que respeita a ataques de injeção imediata permaneça incerta, é crucial ter cuidado ao empregar sistemas de inteligência artificial. Embora essas tecnologias ofereçam benefícios significativos, como maior eficiência e precisão, é essencial não ignorar a importância da intuição e do discernimento humanos. Ao avaliarem criticamente os resultados gerados por modelos linguísticos avançados como o Copilot, os utilizadores podem atenuar os riscos associados à confiança exclusiva na automatização, ao mesmo tempo que desfrutam das funcionalidades cada vez mais sofisticadas das ferramentas de IA.