Como analisar documentos com LangChain e a API OpenAI
A extração de informações de documentos e dados é crucial para tomar decisões informadas. No entanto, surgem preocupações com a privacidade quando se lida com informações sensíveis. A LangChain, em combinação com a API OpenAI, permite-lhe analisar os seus documentos locais sem a necessidade de os carregar online.
Através do armazenamento local de dados, utilizando embeddings e vectorizações para análise, bem como realizando operações dentro do próprio sistema, o OpenAI mantém efetivamente a privacidade. É importante salientar que as informações enviadas pelos clientes através da sua API não são utilizadas no treino de modelos ou na melhoria dos serviços.
Configurando seu ambiente
Para criar um novo ambiente virtual Python e instalar as bibliotecas necessárias, siga estes passos:Primeiramente, estabeleça um novo ambiente Python utilizando o módulo venv que vem com o Python 3.x. Isto evitará qualquer problema de compatibilidade entre diferentes versões dos pacotes instalados. Para fazer isso, abra o seu terminal ou prompt de comando e navegue até o diretório desejado onde você quer criar o ambiente virtual. Uma vez lá, introduza o seguinte comando:bashpython -m venv myenvSubstitua “myenv” pelo nome que preferir para o seu ambiente virtual. Em seguida, ative o ambiente recém-criado usando o comando ./bin/activate (no Windows) ou source bin/activate (no macOS ou Linux). Após a ativação, proceda à instalação das bibliotecas necessárias executando o comando
pip install langchain openai tiktoken faiss-cpu pypdf
A utilização de cada biblioteca pode ser resumida da seguinte forma
O LangChain é uma ferramenta versátil concebida para facilitar a criação e gestão de cadeias linguísticas para várias tarefas de processamento e análise de texto. A plataforma oferece uma série de funcionalidades, como o carregamento de documentos, a segmentação de textos, a geração de incorporações e o armazenamento de vectores, tudo com o objetivo de simplificar as suas operações relacionadas com a linguagem com facilidade e eficiência.
A estimada plataforma da OpenAI dá aos utilizadores a oportunidade de executar inquéritos e obter respostas de modelos linguísticos avançados, proporcionando um recurso valioso para quem procura uma análise ou assistência perspicaz.
O TikTokoken serve para quantificar o número de caracteres num determinado corpo de texto, permitindo uma contabilização exacta da utilização do token durante as interacções com a API da Open AI, em que as taxas são determinadas pela quantidade de texto utilizada.
FAISS é uma ferramenta eficiente que permite estabelecer e manter um repositório de representações vectoriais, facilitando o acesso rápido a vectores codificados de forma semelhante através das suas incorporações.
PyPDF2 é um pacote Python que facilita a extração de texto de ficheiros Portable Document Format (PDF). O software simplifica o processo de carregamento de documentos PDF e permite a recuperação do seu conteúdo para posterior manipulação ou análise.
Uma vez concluída a instalação de todas as bibliotecas, o seu espaço de trabalho está agora preparado e equipado com as ferramentas necessárias para iniciar as operações.
Obter uma chave de API OpenAI
Para utilizar os serviços fornecidos pela API OpenAI, é obrigatório incorporar uma chave de API na sua consulta. Essa inclusão permite que o fornecedor da API confirme a autenticidade da parte requerente, verificando também se o remetente possui a autorização necessária para obter acesso às funcionalidades disponíveis.
Para obter uma chave de API OpenAI, aceda à plataforma OpenAI .
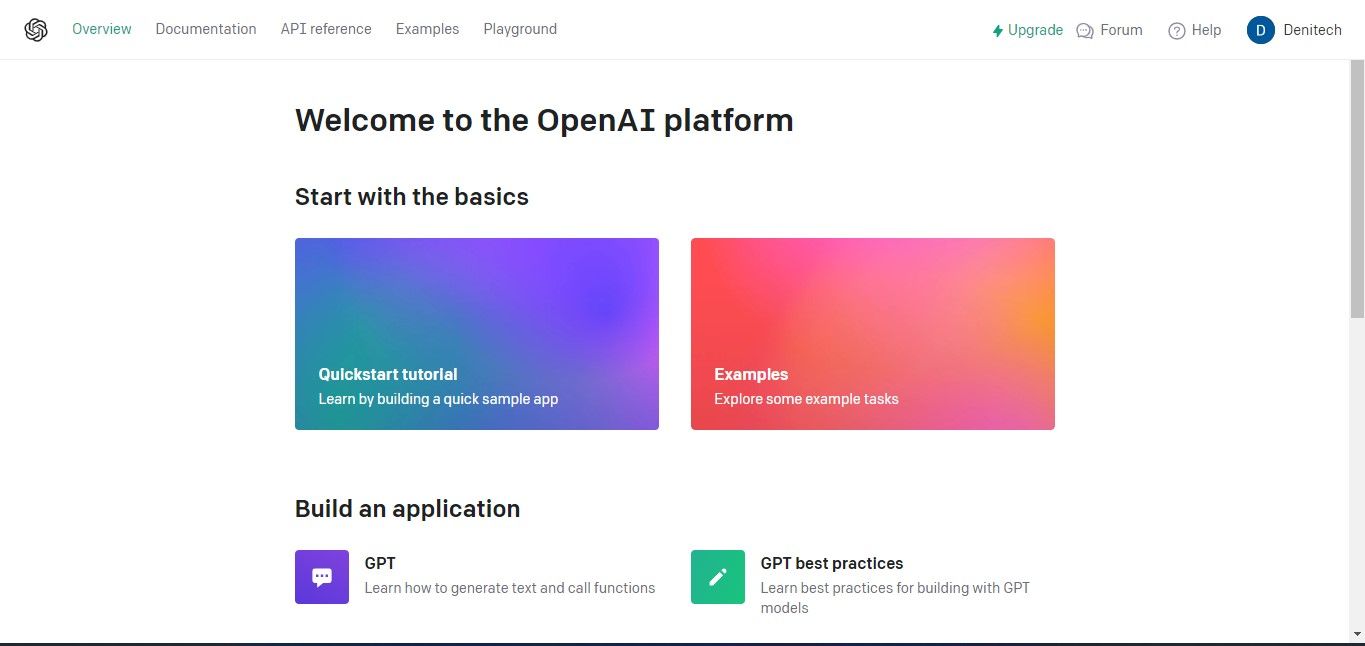
De facto, para aceder às chaves API, navegue até à secção Perfil situada no canto superior direito do painel de controlo da sua conta e seleccione “Ver chaves API”. Esta ação mostrará imediatamente a página das chaves API para uma gestão mais aprofundada.
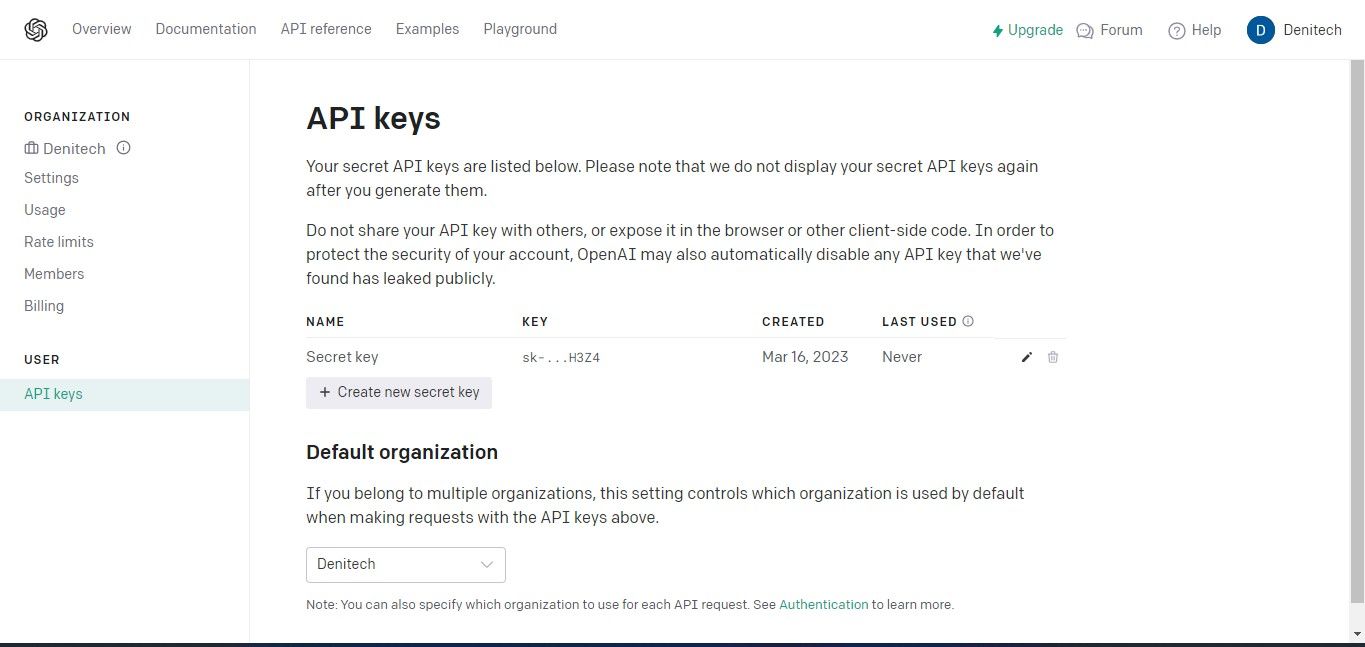
Clique no botão “Create New Secret Key” (Criar nova chave secreta) para iniciar o processo de geração de uma chave de API para utilização com o OpenAI. Uma vez gerada, forneça um nome para a sua chave e, em seguida, clique na opção “Create New Secret Key” (Criar nova chave secreta) para concluir a criação da sua chave. É importante que guarde com segurança a chave de API gerada, uma vez que o acesso à mesma pode não estar disponível através da sua conta OpenAI devido a considerações de segurança. No caso de perder a chave secreta, terá de criar outra no seu lugar.
O código fonte completo pode ser acedido através de um repositório GitHub, que oferece aos utilizadores a oportunidade de explorar e utilizar o conteúdo do projeto.
Importar as bibliotecas necessárias
Para que um utilizador possa utilizar os pacotes que foram instalados no seu ambiente virtual, é necessário incorporá-los através de um ato de importação.
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
Ao examinar o código, torna-se evidente que o processo envolve a importação das dependências necessárias no âmbito da estrutura LangChain, garantindo assim o acesso a uma vasta gama de funcionalidades oferecidas pela referida estrutura.
Carregar o documento para análise
Para começar, estabeleça uma variável que sirva de repositório da sua chave API. Esta entidade será utilizada posteriormente no script para efeitos de validação.
# Hardcoded API key
openai_api_key = "Your API key"
Ao distribuir código de nível de produção que pode ser compartilhado com entidades externas, é aconselhável evitar a incorporação de informações confidenciais, como chaves de API, diretamente no código-fonte. Em vez de implementar esta abordagem, a utilização de uma variável ambiental oferece uma solução mais segura e prática para gerir essas credenciais num contexto partilhado.
Claro! Aqui está um exemplo de como poderia implementar isto em Python usando a biblioteca PyPDF2 para trabalhar com ficheiros PDF e a função open() integrada para ler ficheiros de texto simples:pythonimport PyPDF2from io import BytesIOdef load_document(file_path):“““Carrega um documento a partir do caminho de ficheiro especificado.”””# Verifica se o ficheiro existe antes de o tentar abrirtry:if not file_path.endswith(’.pdf’):# O documento não é um ficheiro PDF, por isso tenta abrir como um ficheiro de textowith open(file_path, ‘r’) as f:return f.read()elif file_path.endswith(’.pdf’):
def load_document(filename):
if filename.endswith(".pdf"):
loader = PyPDFLoader(filename)
documents = loader.load()
elif filename.endswith(".txt"):
loader = TextLoader(filename)
documents = loader.load()
else:
raise ValueError("Invalid file type")
Depois de os documentos terem sido carregados, o processo envolve a criação de uma instância de CharacterTextSplitter . O referido separador é responsável por dividir a documentação carregada em partes mais fáceis de gerir, sendo cada divisão determinada por caracteres individuais.
text_splitter = CharacterTextSplitter(chunk_size=1000,
chunk_overlap=30, separator="\n")
return text_splitter.split_documents(documents=documents)
O processamento do conteúdo em segmentos mais pequenos e coesos facilita o manuseamento eficiente e mantém um grau de sobreposição contextual relevante, o que se revela benéfico em actividades como a análise textual e as operações de recuperação de dados.
Consultar o documento
Para extrair informações do documento apresentado, desenvolver uma função que aceite um termo de pesquisa e um componente de recuperação de dados como entradas. Esta função utilizará o recuperador fornecido em conjunto com uma instanciação do modelo de linguagem natural Open AI para estabelecer um objeto RetrievalQA.
def query_pdf(query, retriever):
qa = RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),
chain_type="stuff", retriever=retriever)
result = qa.run(query)
print(result)
A presente função utiliza o modelo de resposta a perguntas instanciado para executar o inquérito e apresentar o resultado.
Criar a função principal
A função principal governa a progressão geral do programa, aceitando a entrada fornecida pelo utilizador para o nome de ficheiro de um documento, carregando subsequentemente o documento especificado. Em seguida, estabelece uma instância do OpenAIEmbeddings concebida para a incorporação de palavras e constrói um repositório de vectores com base no documento previamente processado e nas suas correspondentes incorporações de palavras. Por fim, a base de dados vetorial construída é guardada num suporte de armazenamento local sob a forma de um ficheiro.
Uma vez inicializada a camada de persistência e carregados os dados necessários, o sistema passa a uma fase iterativa em que os utilizadores são convidados a submeter consultas através de uma interface de texto. Durante este processo, a funcionalidade principal é delegada no método query_pdf , que é chamado juntamente com o recuperador do repositório de vectores responsável obtido durante a inicialização. Este ciclo continua indefinidamente até que o utilizador decida terminar a sessão introduzindo a palavra “exit”.
def main():
filename = input("Enter the name of the document (.pdf or .txt):\n")
docs = load_document(filename)
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectorstore = FAISS.from_documents(docs, embeddings)
vectorstore.save_local("faiss_index_constitution")
persisted_vectorstore = FAISS.load_local("faiss_index_constitution", embeddings)
query = input("Type in your query (type 'exit' to quit):\n")
while query != "exit":
query_pdf(query, persisted_vectorstore.as_retriever())
query = input("Type in your query (type 'exit' to quit):\n")
Os embeddings encapsulam as intrincadas interligações que existem entre itens lexicais, servindo como uma representação abstrata da linguagem escrita ou falada num formato numérico. Por outras palavras, os vectores oferecem um método para representar passagens de texto através de uma série de valores numéricos, permitindo assim o processamento computacional e a análise de dados linguísticos.
O presente código transforma o conteúdo textual do documento em representações vectoriais utilizando os embeddings produzidos pelo OpenAIEmbeddings, indexando posteriormente estas representações vectoriais com o FAISS (Facebook AI Similarity Search) para facilitar a rápida recuperação e comparação de padrões vectoriais semelhantes. Tal permite a análise do documento apresentado.
A incorporação do atributo __name__ com o valor correspondente de "__main__" é um passo essencial na execução da função principal quando o script é executado como um programa autónomo. Ao empregar esta construção, permite a execução sem problemas da funcionalidade principal após a interação do utilizador, sem necessitar de quaisquer avisos ou intervenções externas.
if __name__ == "__main__":
main()
Este programa de software funciona como uma ferramenta baseada num terminal. Como melhoria, é possível utilizar o Streamlit para incorporar uma interface gráfica do utilizador para a aplicação através da Internet.
Execução da análise documental
Para executar uma análise documental, coloque o documento que pretende examinar no diretório do seu projeto e, em seguida, inicie a aplicação informática. O sistema solicitará a identificação do documento específico a analisar, pedindo-lhe que introduza a sua designação completa. Em seguida, forneça uma série de termos de pesquisa que a ferramenta deverá processar durante o processo de análise.
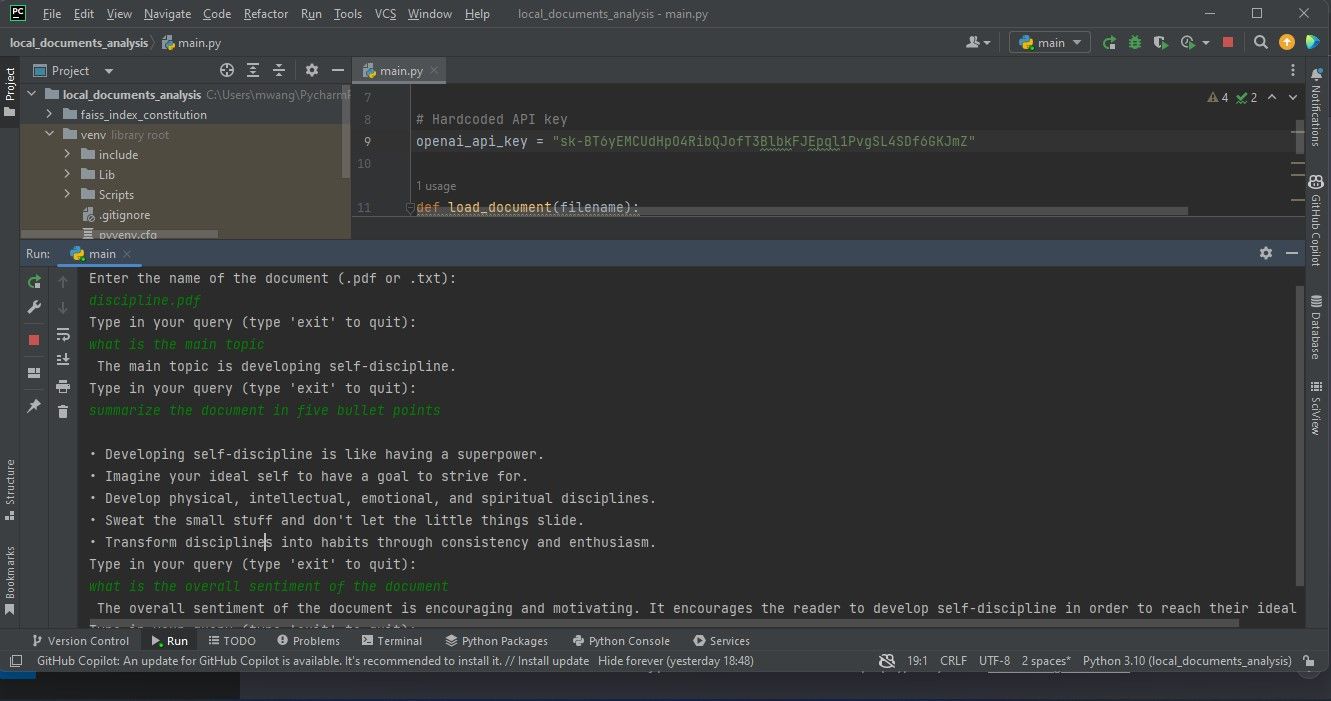
A representação gráfica aqui fornecida mostra os resultados obtidos com o processamento de um ficheiro Portable Document Format (PDF), tal como ilustrado na imagem de ecrã situada abaixo desta declaração.
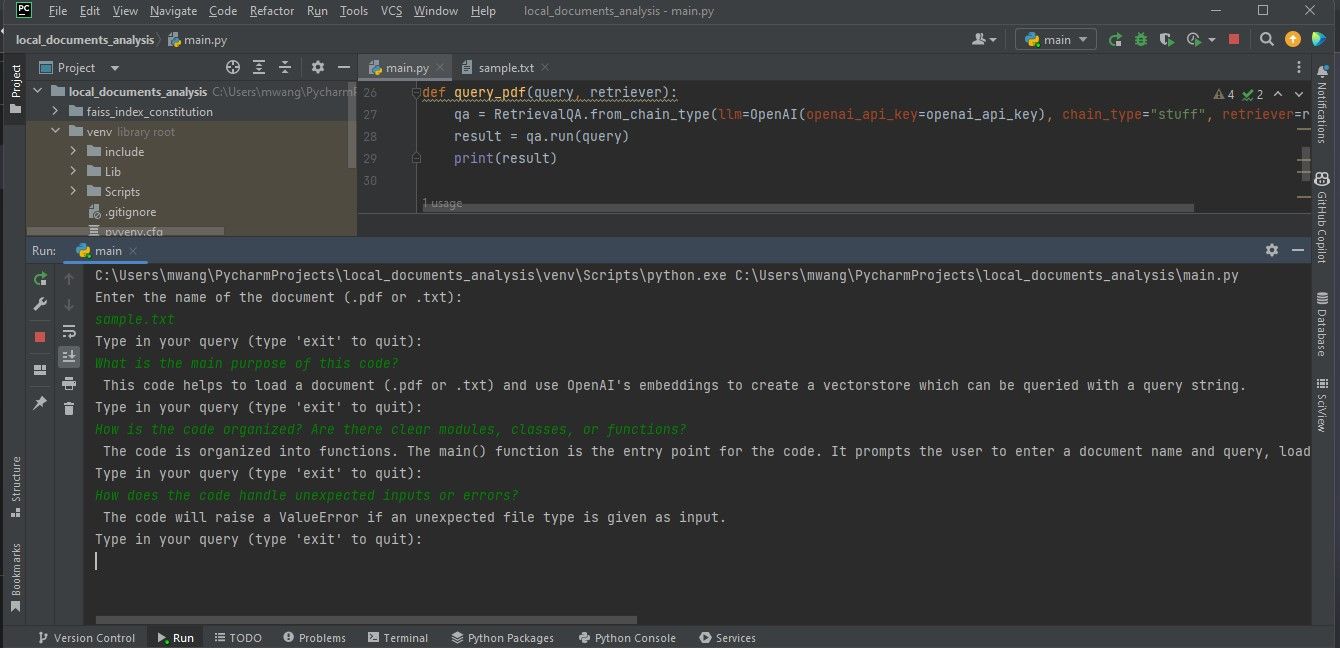
O ecrã seguinte exemplifica os resultados de uma análise de um documento que contém código de programação.
Para garantir uma análise precisa dos ficheiros pretendidos, é essencial que estes estejam em formato PDF ou de texto. Se os documentos estiverem em tipos de ficheiros alternativos, existem vários recursos online disponíveis para converter esses ficheiros num formato PDF adequado para uma análise e interpretação minuciosas.
Compreender a tecnologia por detrás dos modelos de linguagem de grande dimensão
O LangChain simplifica o processo de desenvolvimento de aplicações que utilizam capacidades avançadas de linguagem natural, abstraindo os aspectos técnicos complexos, permitindo que os utilizadores se concentrem na funcionalidade pretendida sem se aprofundarem demasiado nos meandros da modelação de linguagem baseada em IA. É importante ter uma compreensão abrangente das tecnologias subjacentes que permitem estes modelos, de modo a compreender totalmente o funcionamento da aplicação específica que está a ser desenvolvida.