A IA está a chegar para os seus dados das redes sociais: Pode fazer alguma coisa em relação a isso?
Key Takeaways
Embora haja uma preocupação crescente com a privacidade das informações dos utilizadores nas plataformas de redes sociais, foi noticiado que algumas destas plataformas venderam o acesso aos dados dos utilizadores a empresas de inteligência artificial (IA) para treinar os seus modelos de IA generativa. Isto levanta questões sobre as implicações éticas e as potenciais consequências de tais acções.
Sabe-se que as plataformas acima mencionadas, como Meta, Reddit, Tumblr e WordPress.com, participam em acordos que envolvem o licenciamento de dados para efeitos de treino de inteligência artificial.
Os utilizadores podem tomar algumas medidas modestas para salvaguardar as suas informações, modificando as preferências de privacidade, recusando a partilha e exercendo prudência ao publicar conteúdos na Internet.
Nos últimos tempos, as empresas de redes sociais têm vindo a explorar novos métodos para capitalizar a informação dos utilizadores, celebrando acordos com empresas de inteligência artificial. No entanto, levanta-se a questão de saber que medidas podem os indivíduos comuns adotar para salvaguardar os seus dados pessoais e criações digitais de serem explorados em tais transacções.
Plataformas de redes sociais chegam a acordo com empresas de IA
A utilização de informações das redes sociais para treinar modelos de inteligência artificial tem suscitado um debate considerável, mas parece que as empresas de redes sociais não estão dispostas a ceder os dados dos utilizadores.
A Meta integrou os dados das redes sociais nas suas funcionalidades de IA generativa, que foram apresentadas durante o evento Meta Connect. Estas funcionalidades incluem a Meta AI e capacidades como a geração de emojis baseados em IA para plataformas como o WhatsApp.
Tal como Mike Clark, Diretor de Gestão de Produtos da Meta, afirmou num post da Meta Newsroom :
Os modelos de inteligência artificial utilizados nas funcionalidades apresentadas durante o nosso recente evento, conhecido como Connect, foram treinados utilizando conteúdos publicamente disponíveis no Instagram e no Facebook, incluindo imagens e respectivas legendas.
Esta tendência não parece estar a abrandar em De acordo com a Reuters , o Reddit chegou a um acordo com a Google para disponibilizar o conteúdo da plataforma de redes sociais para o treino de modelos de IA.
O registo S-1 do Reddit para a sua IPO, apresentado em 22 de fevereiro de 2024, confirma que a empresa está a explorar acordos de licenciamento. O registo indica:
A utilização de dados do Reddit provou ser essencial para o desenvolvimento de tecnologias contemporâneas de inteligência artificial, incluindo modelos de linguagem de grande porte (LLMs).Consequentemente, prevemos que o extenso repositório de informações e conhecimentos de conversação do Reddit continuará a ser fundamental para aperfeiçoar e melhorar as capacidades destes sistemas linguísticos avançados.
O Reddit iniciou um programa que permite a entidades externas obter autorização para aceder, examinar e apresentar dados passados e actuais da sua plataforma, com o objetivo de utilizar esta informação para melhorar os modelos de linguagem de grande dimensão (LLM).
E embora o Meta e o Reddit sejam alguns dos maiores nomes das redes sociais, não são as únicas plataformas envolvidas na utilização de dados das redes sociais para treinar a IA. De acordo com um relatório da 404 Media , o Tumblr e o WordPress.com estão a preparar-se para vender dados de utilizadores à Midjourney e à OpenAI.
Pode impedir que as plataformas vendam os seus dados das redes sociais para treino de IA?
A utilização de plataformas como o Facebook, Instagram, Reddit, Tumblr e WordPress.com pode fazer com que o conteúdo acessível ao público seja incorporado no processo de desenvolvimento de Language Model Learners (LLMs).
Por exemplo, se utilizar a ferramenta de pesquisa do Washington Post para ver que sítios foram incluídos no conjunto de dados C4 do Google, que foi utilizado como parte do treino do Bard, verá que o Reddit.com representa 7,9 milhões de tokens.
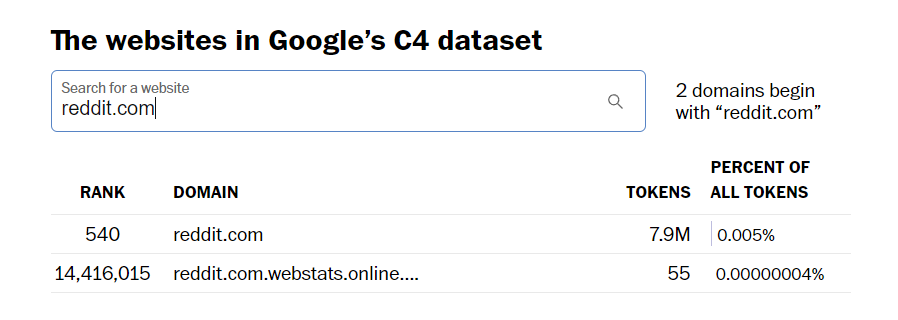
O conjunto de dados engloba uma gama considerável de fontes de conteúdo, incluindo o Tumblr.com com a sua representação substancial de aproximadamente 1,6 milhões de tokens, bem como sites mais pequenos, como o meu, que utiliza o WordPress.com, que contribui minimamente com apenas cerca de 14.000 tokens. Vale a pena notar que mesmo estes modestos blogues pessoais estão incluídos no âmbito do conjunto de dados.
Os acordos emergentes entre empresas de inteligência artificial e entidades de redes sociais implicam a comercialização ativa desses dados, por oposição à extração passiva de fontes online.
Mas quando se trata de processamento futuro, o que é que se pode fazer? A Meta introduziu um formulário para os direitos do titular dos dados de IA generativa que lhe permite opor-se ou restringir o tratamento dos seus dados pessoais por terceiros para treinar os modelos de IA generativa da Meta.
É importante notar que esta opção não permite que sejam levantadas objecções contra o tratamento dos dados do utilizador pela Meta para efeitos de treino de sistemas de inteligência artificial. Além disso, ao tentar apresentar uma objeção através do formulário fornecido, descobriu-se que era necessário apresentar provas de que as informações pessoais de um utilizador estavam a ser utilizadas nos resultados de IA da Meta, como parte do processo de pedido de apoio.
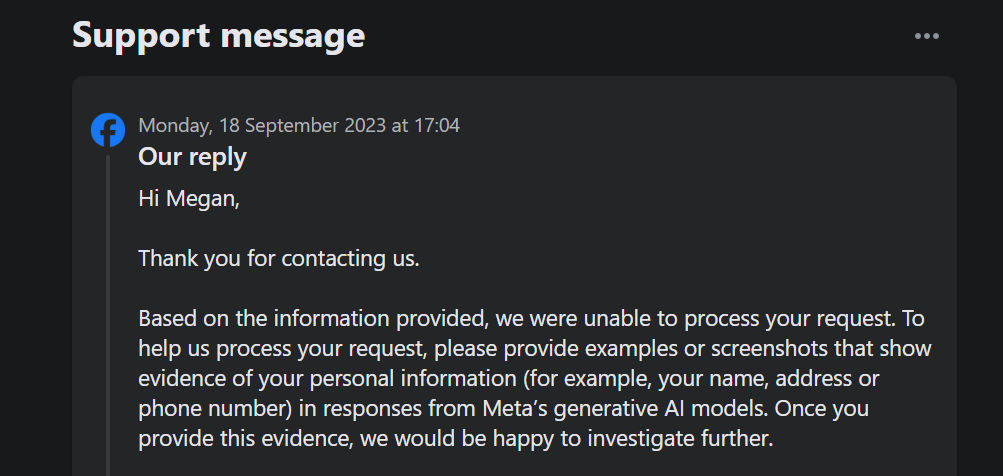
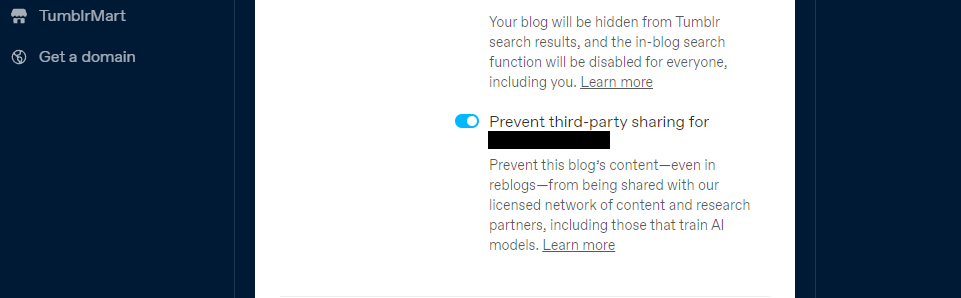
O Tumblr oferece uma solução que permite aos utilizadores recusar a divulgação dos seus blogues públicos a entidades externas através da configuração da sua conta. Para aceder a esta funcionalidade, navegue até à sua página de perfil e desloque-se para baixo até localizar as opções de “Visibilidade”. A partir daí, seleccione a alternativa que impede a partilha não autorizada do seu blogue com terceiros.
Ao utilizar plataformas como o Instagram, uma estratégia possível é alterar as configurações de privacidade da sua conta para restringir a acessibilidade. Embora esta medida não forneça uma garantia absoluta de que as suas informações não serão exploradas, dada a prevalência de práticas de recolha de dados direccionadas para conteúdos publicamente disponíveis, a mudança para uma conta privada pode servir como um formidável dissuasor.
Em alternativa, tem a opção de configurar a sua conta do Twitter para ser privada. No entanto, é importante notar que esta medida não oferece uma garantia absoluta de proteção da privacidade dos seus dados.
Uma declaração conjunta de vários comissários nacionais de informação e especialistas de todo o mundo também sugeriu algumas acções para os indivíduos que procuram minimizar o risco de privacidade da recolha de dados por empresas de IA. Os conselhos incluem:
Reveja os termos e condições, bem como a política de privacidade deste sítio Web, para compreender as suas práticas relativamente à partilha de dados pessoais.
Quando se partilham informações pessoais na Internet, é importante ter cautela e contenção, especialmente quando se divulgam dados sensíveis.
⭐ Gerir as suas definições de privacidade.
Ao considerar o conteúdo que se escolhe partilhar na Internet, é importante manter uma perspetiva de longo prazo e considerar cuidadosamente as potenciais implicações de tais divulgações, tanto no futuro imediato como no futuro distante.
Se suspeitar que as suas informações pessoais foram extraídas sem a devida autorização de uma plataforma ou sítio de rede social, é aconselhável contactar o respetivo fornecedor de serviços para obter esclarecimentos. Caso não fique satisfeito com a resposta, considere a possibilidade de apresentar uma queixa junto da agência de proteção de dados competente.
Tem a opção de remover dados específicos que possam ser acedidos por entidades terceiras, embora as informações publicadas publicamente no seu perfil possam já ter sido extraídas por terceiros.
Lamentavelmente, a medida em que os utilizadores comuns podem proteger os seus dados das empresas de IA é limitada.O controlo e a autoridade máximos nesta matéria podem exigir a intervenção de organismos reguladores.