Como extrair dados de um site com o Google Sheets
A recolha de dados da Web é uma técnica poderosa para extrair informações de sítios Web e analisá-las automaticamente. Embora seja possível fazê-lo manualmente, pode ser uma tarefa aborrecida e morosa. As ferramentas de Web scraping tornam o processo mais rápido e mais eficiente, ao mesmo tempo que custam menos.
De facto, o Google Sheets tem a capacidade de servir como uma solução completa para fins de Web scraping, graças à sua função IMPORTXML incorporada. Esta funcionalidade permite aos utilizadores extrair facilmente informações de vários sítios Web, que podem depois ser utilizadas para uma série de aplicações, tais como análise de dados, relatórios e qualquer tarefa que exija informações baseadas em dados.
A função IMPORTXML no Google Sheets
Utilizando a funcionalidade incorporada no Google Sheets, conhecida como “IMPORTXML”, é possível extrair informações de várias fontes da Web, incluindo os formatos XML, HTML, RSS e CSV. A implementação desta funcionalidade tem o potencial de simplificar o processo de recolha de dados de sítios Web sem necessitar de grandes conhecimentos de programação.
Eis a sintaxe básica do IMPORTXML:
=IMPORTXML(url, xpath_query)
O Localizador Uniforme de Recursos (URL) especifica o endereço de uma determinada página Web da qual se pretende extrair informações através de técnicas de raspagem da Web.
A consulta XPath representa a linguagem precisa utilizada para selecionar informações específicas de um documento XML, que descreve os dados desejados que se pretendem extrair.
O XPath, ou XML Path Language, serve como ferramenta de navegação para explorar e extrair informações de documentos XML, incluindo HTML. A utilização desta linguagem permite aos utilizadores identificar as localizações específicas dos elementos de dados pretendidos numa estrutura HTML. A compreensão dos fundamentos das consultas XPath é crucial para a utilização efectiva da função IMPORTXML.
Compreender o XPath
O XPath oferece uma gama de funções e operadores que permitem a manipulação e filtragem de dados num documento HTML. Embora esteja fora do âmbito deste artigo fornecer uma visão geral exaustiva de XML e XPath, apresentarei aqui vários princípios fundamentais de XPath:
A seleção de elementos através da utilização de delimitadores como barras ("/") e barras duplas (//) permite a identificação de caminhos específicos num documento HTML. Por exemplo, “/html/body/div” identificará todas as instâncias de elementos “div” localizados na secção “body” de um documento HTML contido no diretório “html”.
Para identificar e extrair atributos específicos de uma determinada página Web, é possível utilizar vários critérios de seleção baseados em convenções de nomeação de atributos ou outros padrões identificáveis. Utilizando um seletor apropriado, como “@href” neste caso, é possível selecionar e recuperar todas as instâncias de atributos “href” presentes no documento. Esta abordagem permite a recuperação eficiente de informações relevantes, filtrando dados irrelevantes.
Filtrar elementos utilizando predicados entre parênteses rectos é um mecanismo que permite selecionar elementos específicos com base em determinados critérios especificados entre parênteses rectos. Isto pode ser feito através da utilização de atributos ou classes de etiquetas HTML. Um exemplo seria selecionar todos os elementos com o atributo class igual a “contentor” utilizando a sintaxe /div[@class="contentor"] .
O XPath oferece uma gama de funções, incluindo a capacidade de determinar se um dado elemento está contido noutro elemento utilizando a função “contains()”, verificar se o nome da etiqueta de um elemento começa com uma cadeia especificada utilizando a função “starts-with()” e extrair o valor de texto de um elemento utilizando a função “text()”. Estas funções permitem aos utilizadores efetuar operações específicas em documentos XML com base em critérios específicos.
Como extrair XPath de um sítio Web
Extrair o XPath de um elemento utilizando IMPORTXML pode ser uma tarefa difícil para aqueles que estão familiarizados com a sintaxe da função, possuem conhecimento do URL do sítio Web de destino e identificaram o elemento específico que pretendem recuperar. O processo envolve a identificação do identificador único ou dos atributos associados ao elemento pretendido e, em seguida, a utilização desta informação em conjunto com a fórmula XPath para gerar o caminho adequado para o elemento dentro da estrutura XML da página Web.
Não é necessário memorizar a arquitetura de um sítio Web na sua totalidade para obter informações a partir dele utilizando IMPORTXML. De facto, cada plataforma de navegação na Web fornece uma ferramenta eficiente que permite reproduzir sem esforço o XPath de um determinado elemento.
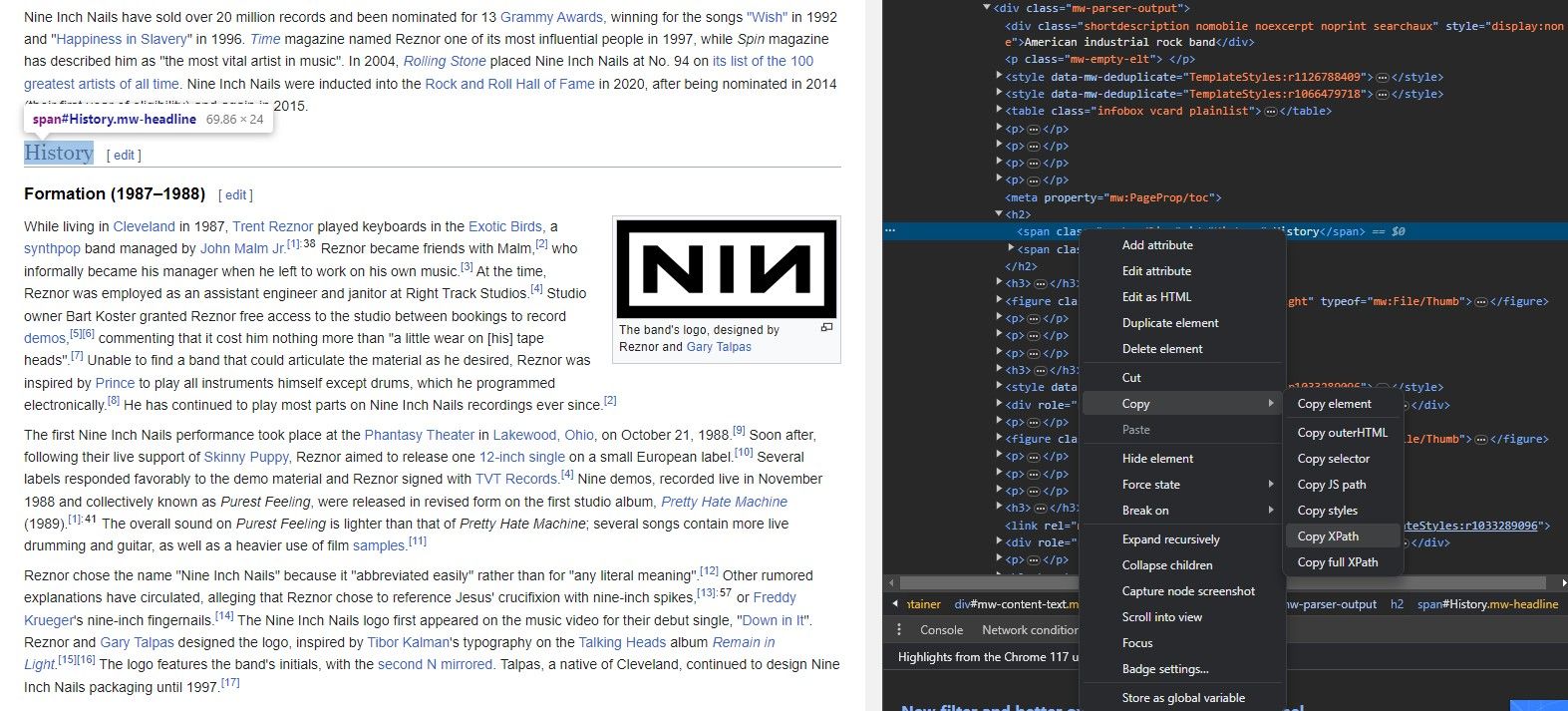
A ferramenta “Inspecionar Elemento” permite a extração de uma XML Path Language (XPath) de vários componentes da página web através de um processo simplificado, como se detalha a seguir:
Aceder à página Web pretendida utilizando uma aplicação de navegação na Internet preferida, como o Google Chrome ou o Mozilla Firefox.
Recuperar o elemento de dados pretendido, identificando a sua localização no código-fonte da página Web, utilizando uma ferramenta de recolha de dados da Web, como o Beautiful Soup ou o Scrapy.
⭐Clique com o botão direito do rato sobre o elemento.
Para aceder à funcionalidade “Inspecionar elemento”, pode seleccioná-la no menu contextual obtido ao clicar com o botão direito do rato na página Web, mantendo-o premido. Esta ação fará com que o browser mostre um painel interativo que apresenta a marcação HTML subjacente da página, sendo o elemento específico em questão visualmente distinguido dentro deste código.
Em primeiro lugar, clique no elemento que pretende modificar na sua página Web. Depois, localize a opção “Inspecionar” no menu de contexto que aparece ao clicar com o botão direito do rato. Uma vez feito isso, seleccione o elemento desejado na lista de elementos que aparecem no código HTML para posterior edição ou manipulação.
Clique no botão abaixo para gerar uma expressão XPath para o elemento selecionado, que pode depois ser copiada para a sua área de transferência com facilidade.
Agora que obtivemos as informações necessárias, passemos a demonstrar a aplicação prática do IMPORTXML, extraindo URLs de uma determinada página Web.
Como extrair ligações de um sítio Web com IMPORTXML
Utilizando as poderosas capacidades do IMPORTXML, é possível extrair uma vasta gama de informações de vários sítios Web. Isto engloba não só o conteúdo textual, mas também recursos multimédia, como imagens e vídeos, bem como praticamente todos os componentes concebíveis presentes no site. Entre estes componentes, as hiperligações têm especial destaque devido à sua importância para a compreensão da estrutura e hierarquia de uma página Web. Ao examinar os destinos para os quais uma determinada página está ligada, é possível obter informações valiosas sobre a natureza e o objetivo desse sítio Web.
A utilização do IMPORTXML no Google Sheets permite uma extração rápida de URLs de páginas Web, facilitando a análise subsequente através do conjunto de funções disponíveis na plataforma.
Extrair todas as hiperligações
Para extrair todos os URLs presentes numa determinada página Web, pode utilizar-se a seguinte metodologia:
=IMPORTXML(url, "//a/@href")
A expressão XPath apresentada recupera todos os atributos “href” associados a cada instância de um elemento “a”, isolando e recolhendo assim todas as hiperligações presentes na página Web.
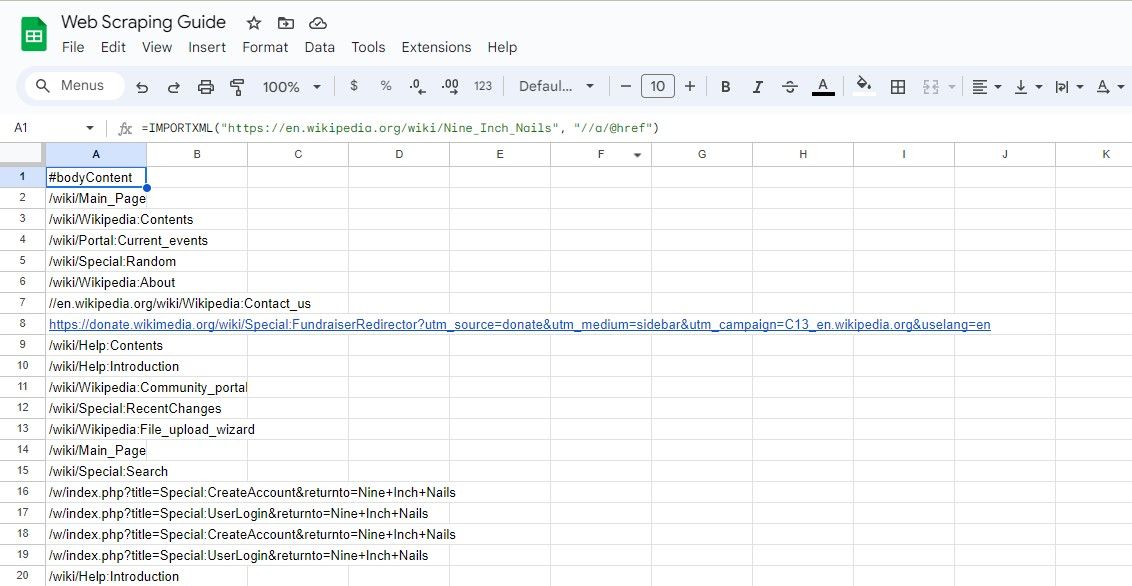
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
O algoritmo acima mencionado extrai todas as hiperligações contidas numa entrada da Wikipédia.
A incorporação da prática de introduzir o URL de uma página Web numa célula distinta e referenciá-lo na mesma é uma abordagem astuta, uma vez que esta medida ajuda a manter fórmulas concisas, evitando a confusão ou a complexidade.Uma tática semelhante pode ser aplicada na formulação de consultas XPath para uma navegação sem falhas no contexto da análise de dados.
Extrair todos os textos das hiperligações
Para recuperar o conteúdo das hiperligações, para além dos respectivos localizadores uniformes de recursos, pode utilizar-se a seguinte abordagem:
=IMPORTXML(url, "//a")
A presente consulta abrange a recuperação de todos os elementos, pelo que o texto da hiperligação extraído e os URL associados podem ser obtidos a partir do resultado.
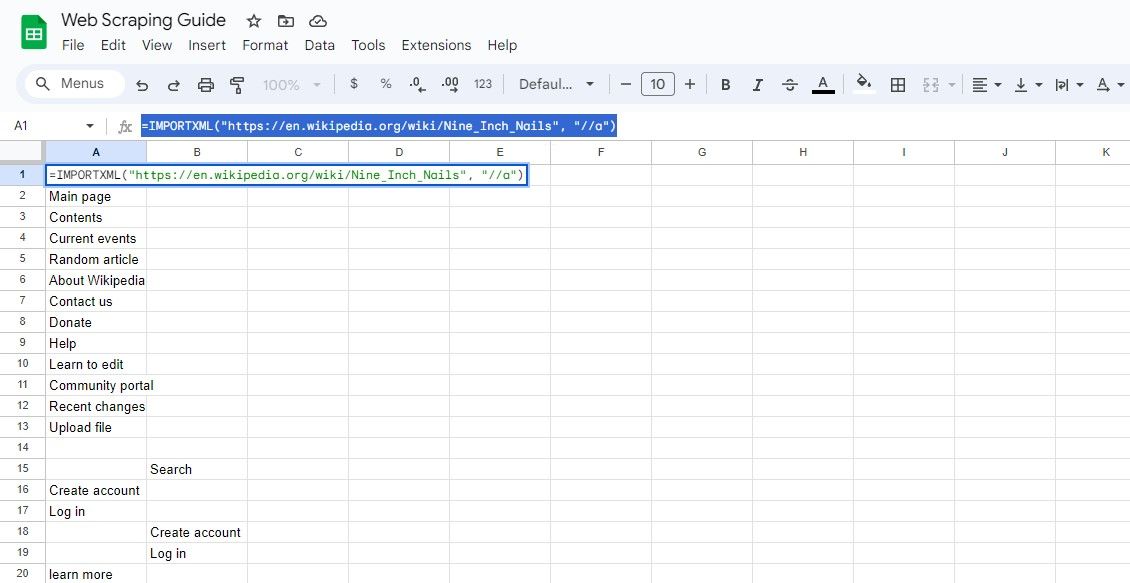
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
A formulação acima mencionada recupera o texto âncora na entrada idêntica da Wikipédia.
Como extrair ligações específicas de um sítio Web com IMPORTXML
Por vezes, é necessário extrair páginas Web de determinados sítios Web que contenham determinadas palavras-chave ou que estejam situadas em áreas específicas da página Web.
A utilização de conhecimentos proficientes de XPath permite identificar e localizar com precisão o elemento pretendido.
Extrair hiperligações que contenham uma palavra-chave
Para extrair URLs que contenham uma determinada palavra-chave utilizando XPath, pode empregar-se a função “contains()”:
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
A consulta dada recupera os valores href de elementos HTML cujo atributo href inclui um termo de pesquisa específico, de acordo com os critérios fornecidos.
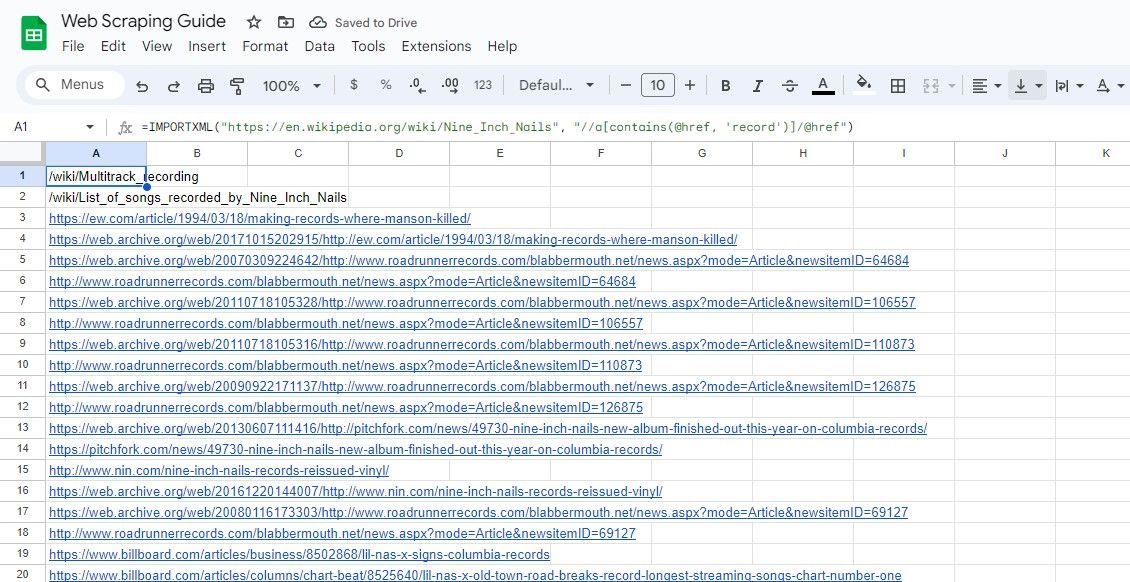
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
O algoritmo anterior extrai todas as hiperligações incorporadas numa instância específica de conteúdo escrito encontrado na enciclopédia online, em que o termo “record” está presente no corpo da referida ligação.
Extrair hiperligações de uma secção
Para extrair hiperligações de uma parte específica de uma página Web, pode utilizar-se uma expressão XPath para identificar a secção pretendida. Como ilustração, considere o seguinte trecho de código:
=IMPORTXML(url, "//div[@class='section']//a/@href")
A questão em causa diz respeito à seleção de atributos de hiperligação associados a elementos HTML categorizados como “div” e com a designação “section”, em que o referido atributo é comummente utilizado para identificar hiperligações ou navegar entre páginas web, facilitando assim a interação do utilizador em plataformas digitais.
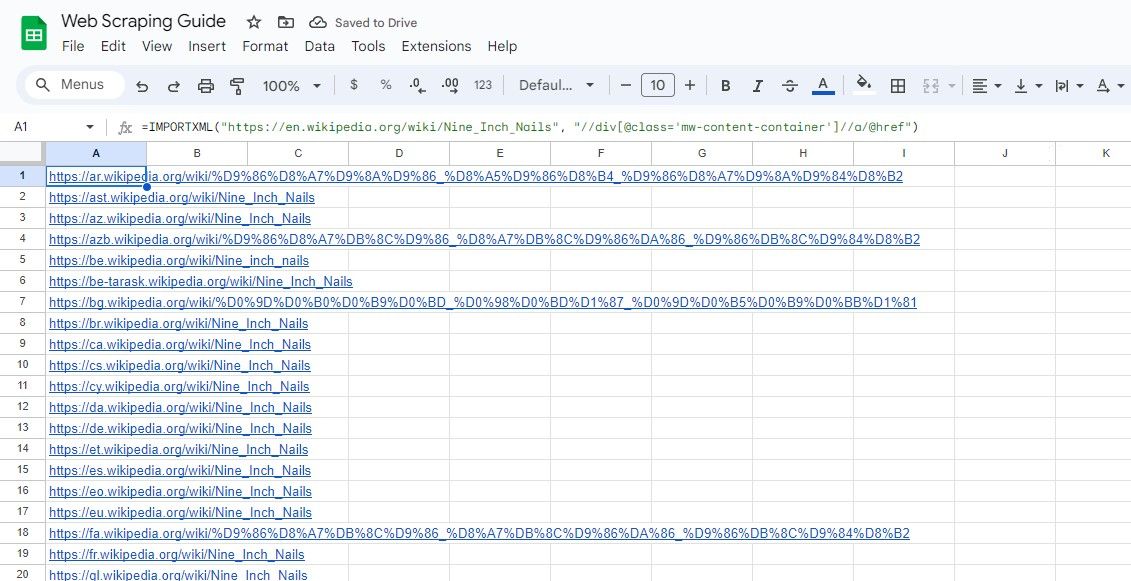
A fórmula acima referida destina-se a todas as hiperligações incorporadas num elemento HTML com o atributo de classe “mw-content-container” e aninhadas num elemento contentor com o atributo id definido como “mainpage”.
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class='mw-content-container']//a/@href")
De facto, é importante reconhecer que a funcionalidade do IMPORTXML vai para além das simples operações de raspagem da Web.A família de funções IMPORT permite aos utilizadores importar facilmente tabelas de dados estruturados diretamente para o Google Sheets a partir de várias fontes na Internet. Esta funcionalidade permite aos utilizadores recolher e organizar informações de forma eficiente sem terem de introduzir manualmente cada dado individualmente.
Embora o Google Sheets e o Microsoft Excel possuam uma série de funcionalidades semelhantes, é importante notar que a família de funções IMPORT é exclusiva do Google Sheets. Consequentemente, devem ser exploradas estratégias alternativas quando se tenta extrair dados de fontes da Web para o Microsoft Excel.
Simplifique a recolha de dados da Web com o Google Sheets
A utilização do Google Sheets em conjunto com a função IMPORTXML permite um método adaptável e acessível de extração de informações de páginas Web, tornando-o uma escolha popular entre aqueles que procuram recolher dados online.
Ao utilizar proficientemente o XPath e formular consultas eficientes com o IMPORTXML, é possível aproveitar todas as suas capacidades e extrair informações valiosas de fontes da Internet. Assim, iniciar a extração de dados através da raspagem da Web elevará as suas capacidades analíticas da Web a uma fase avançada.