Como descarregar e instalar o Llama 2 localmente
A Meta lançou o Llama 2 no verão de A nova versão do Llama foi aperfeiçoada com mais 40% de fichas do que o modelo Llama original, duplicando o seu comprimento de contexto e superando significativamente outros modelos de código aberto disponíveis. A forma mais rápida e fácil de aceder à Llama 2 é através de uma API numa plataforma online. No entanto, se quiser ter a melhor experiência, é melhor instalar e carregar o Llama 2 diretamente no seu computador.
Tendo em conta esta consideração, desenvolvemos um tutorial completo que descreve o processo de utilização do Text-Generation-WebUI para descarregar e executar um Modelo de Linguagem Grande (LLM) da Llama 2 quantizado no seu computador pessoal.
Porquê instalar a Llama 2 localmente
A execução direta da Llama 2 pode ser motivada por vários factores, tais como considerações de privacidade, desejo de personalização e necessidade de funcionalidade offline. No entanto, se alguém estiver a fazer investigação, a aperfeiçoar ou a incorporar a Llama 2 no seu trabalho, a utilização da sua API pode não ser adequada. O principal objetivo da utilização de um modelo local de IA como o Llama 2 é diminuir a dependência de recursos externos de IA, enquanto se desfruta da flexibilidade de empregar a inteligência artificial em qualquer altura e lugar, sem receio de fuga de informação potencialmente sensível para empresas e outras entidades.
Para começar a nossa discussão sobre o processo de instalação da Llama 2 num ambiente local, apresento-lhe um guia passo-a-passo eloquente e detalhado para realizar esta tarefa com êxito.
Passo 1: Instalar a ferramenta de compilação do Visual Studio 2019
Para simplificar o processo, implementámos um pacote de instalação com um único clique para o Text-Generation-WebUI, que é utilizado para interagir com a Llama 2 através de uma interface gráfica de utilizador. No entanto, é imperativo que obtenha as ferramentas de compilação do Visual Studio 2019 e instale os componentes necessários antes de prosseguir com a instalação do referido pacote.
Descarregar: Visual Studio 2019 (Gratuito)
Sinta-se à vontade para obter uma cópia do nosso software de versão comunitária descarregando-o agora.
⭐ Agora instale o Visual Studio 2019 e abra o software. Depois de aberto, marque a caixa no desenvolvimento da área de trabalho com C\\+\\+ e clique em instalar. 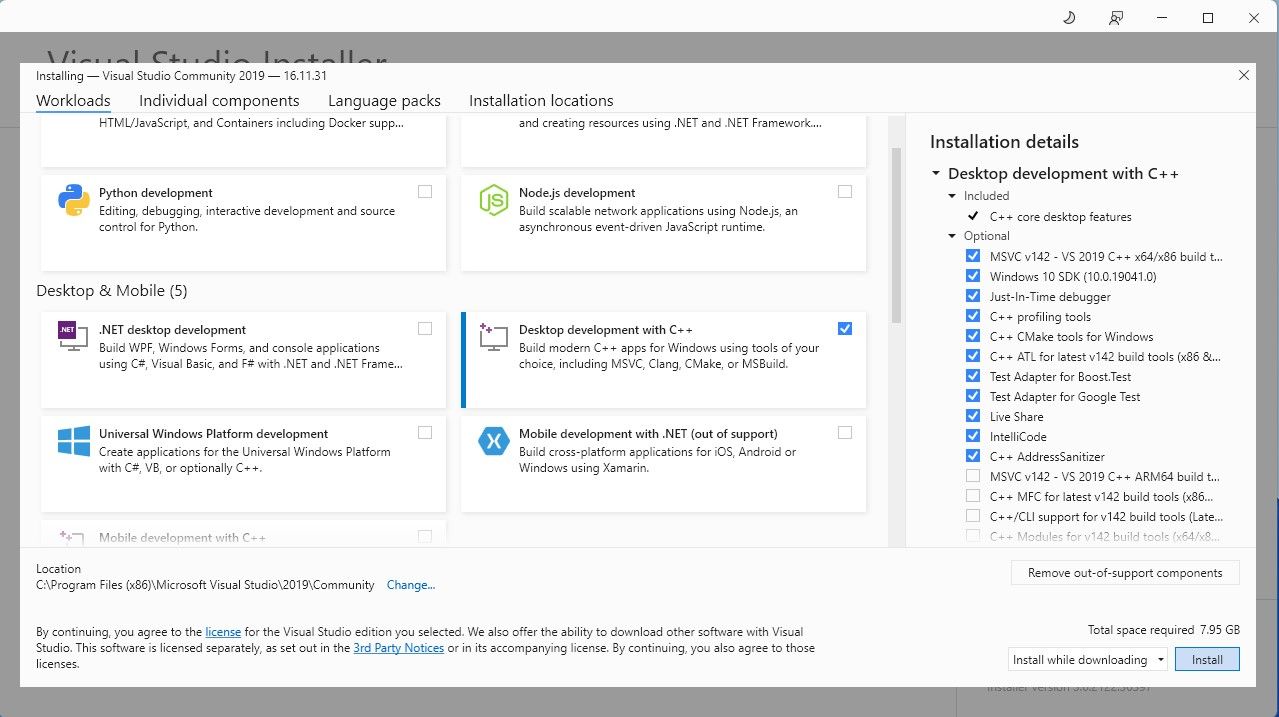
Com a instalação de Desktop development with C\+\+ concluída, prossiga para adquirir o instalador Text-Generation-WebUI de um clique para uma experiência perfeita.
Passo 2: Instalar o Text-Generation-WebUI
O instalador de um clique do Text-Generation-WebUI é um script que, através da automatização, estabelece os directórios necessários e configura o ambiente Conda juntamente com todos os pré-requisitos para a execução de um modelo de Inteligência Artificial.
Para obter o script, pode descarregar o prático instalador de um clique clicando em “Código” e depois seleccionando “Descarregar ZIP”.
Descarregar: Text-Generation-WebUI Installer (Free)
Ao descarregar um arquivo ZIP, pode optar por descompactá-lo e guardar o seu conteúdo num diretório à sua escolha. Para o fazer, basta extrair o ficheiro comprimido acedendo à pasta que o contém, após o que pode explorar a pasta recém-criada à sua vontade.
⭐ Dentro da pasta, desloque-se para baixo e procure o programa de arranque adequado ao seu sistema operativo. Execute os programas fazendo duplo clique no script apropriado.
Escolha um sistema operativo e uma plataforma adequados para a sua aplicação de software. Se estiver a utilizar o Windows como sistema operativo, siga estes passos para configurar o seu software utilizando um ficheiro batch:1. Abra o Explorador de Ficheiros e navegue até ao diretório onde se encontra o seu projeto.2. Clique com o botão direito do rato numa área vazia da pasta e seleccione “Novo” no menu de contexto.3. Escolha “Todas as tarefas” > “Ficheiro batch” para criar um novo ficheiro batch. Em alternativa, pode premir Ctrl \+ Shift \+ B ou clicar com o botão direito do rato e selecionar “New batch file” (Novo ficheiro de lote) no menu de contexto.4. O editor de texto predefinido será aberto com um documento em branco. Copie e cole o trecho de código fornecido no documento.5. Salve o arquivo pressionando Ctrl \+ S ou selecionando “Arquivo
⭐ para MacOS, selecione start_macos shell scrip
⭐ para Linux, start_linux shell script. 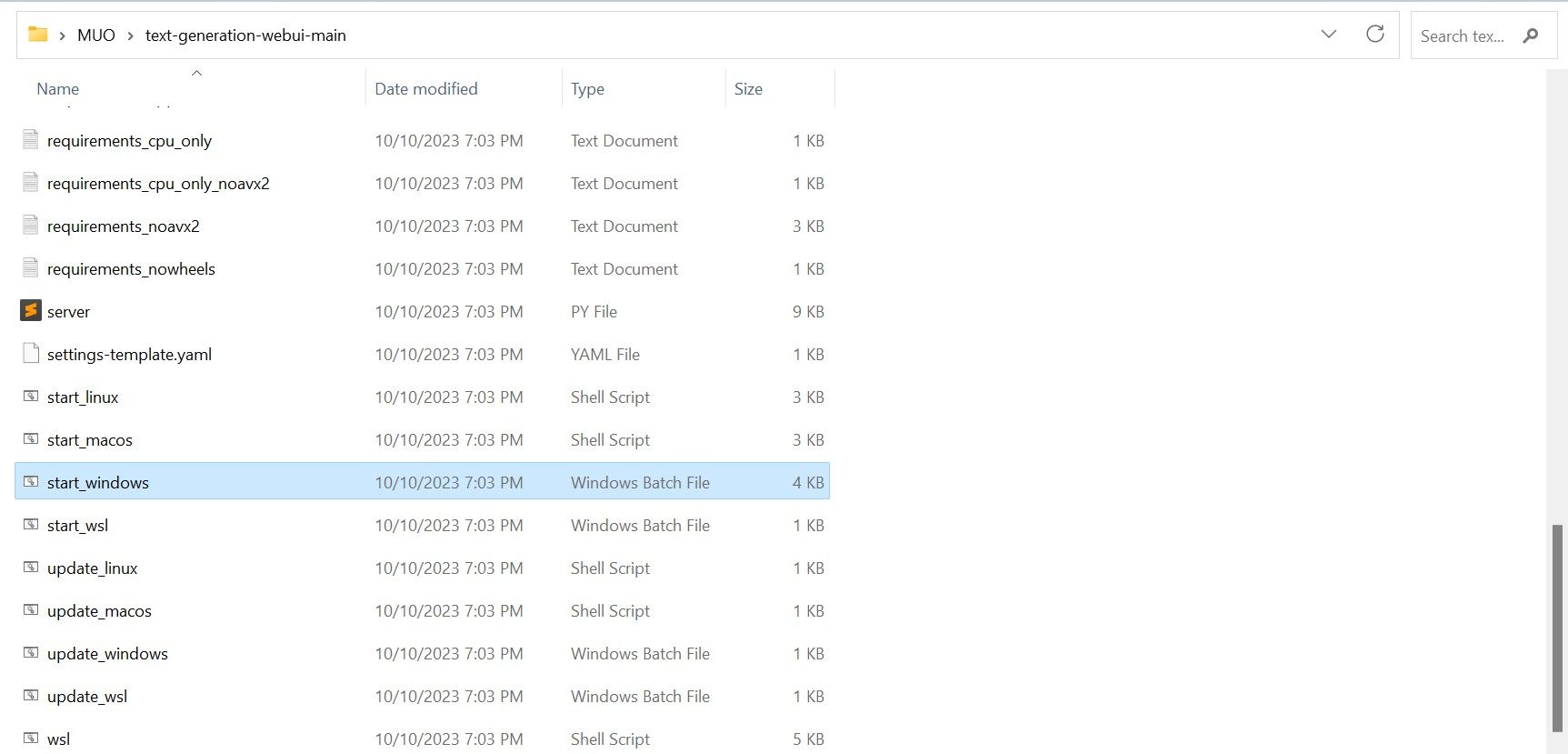
Poderá ser apresentada uma indicação de que o seu software antivírus detectou uma potencial atividade maliciosa, mas não deve ser motivo de preocupação, uma vez que se trata apenas de um falso positivo resultante da execução de um ficheiro batch ou script. Para prosseguir com a operação, clique em “Executar mesmo assim” para contornar quaisquer potenciais preocupações de segurança e continuar com o processo.
⭐ Um terminal será aberto e iniciará a instalação. No início, a instalação fará uma pausa e perguntará qual GPU você está usando. Seleccione o tipo apropriado de GPU instalado no seu computador e prima enter. Para quem não tem uma placa gráfica dedicada, seleccione Nenhum (quero executar modelos no modo CPU) . Lembre-se de que a execução no modo CPU é muito mais lenta quando comparada à execução do modelo com uma GPU dedicada. 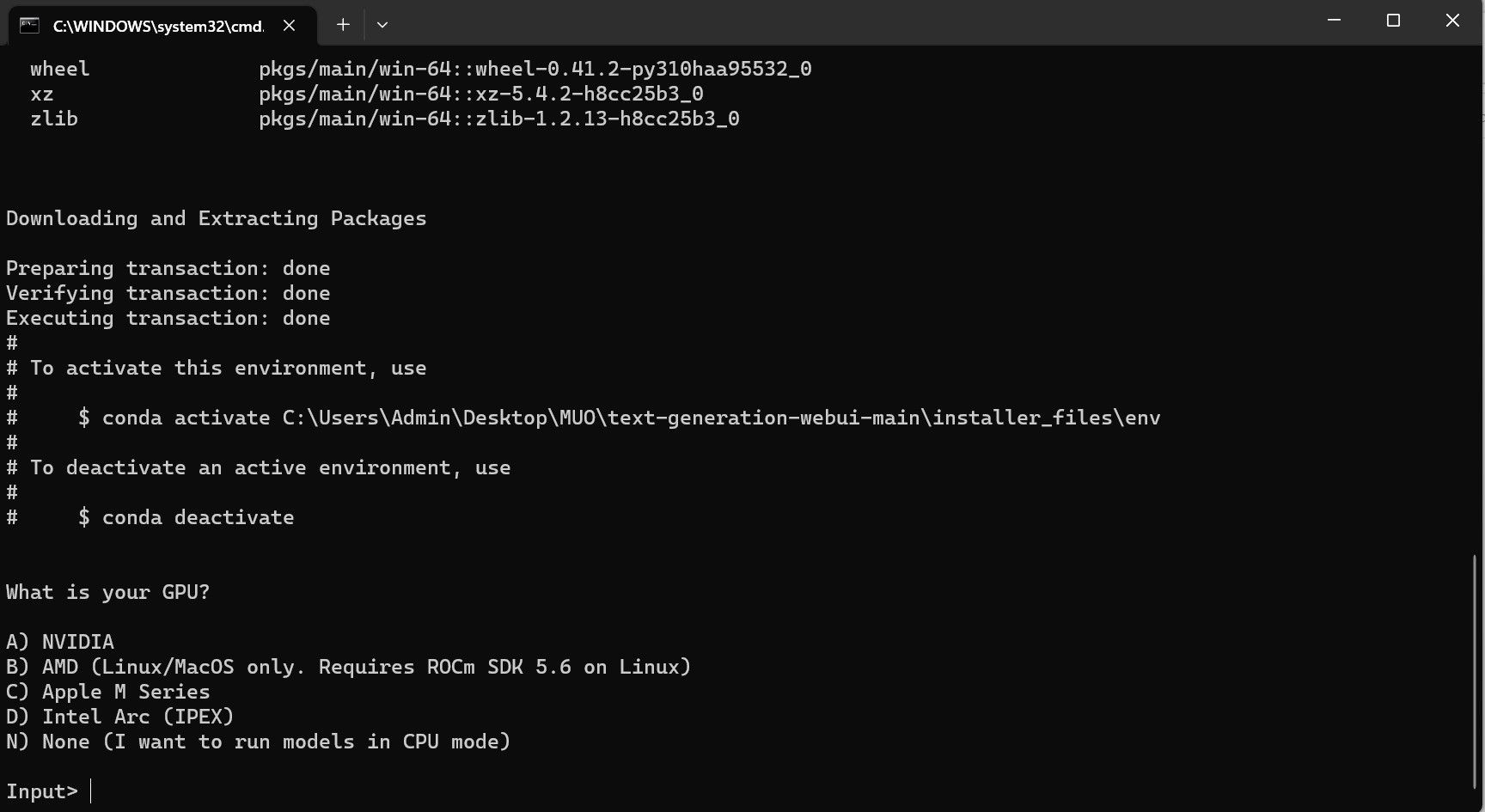
⭐ Quando a configuração estiver concluída, pode agora iniciar o Text-Generation-WebUI localmente. Pode fazê-lo abrindo o seu navegador de Internet preferido e introduzindo o endereço IP fornecido no URL. 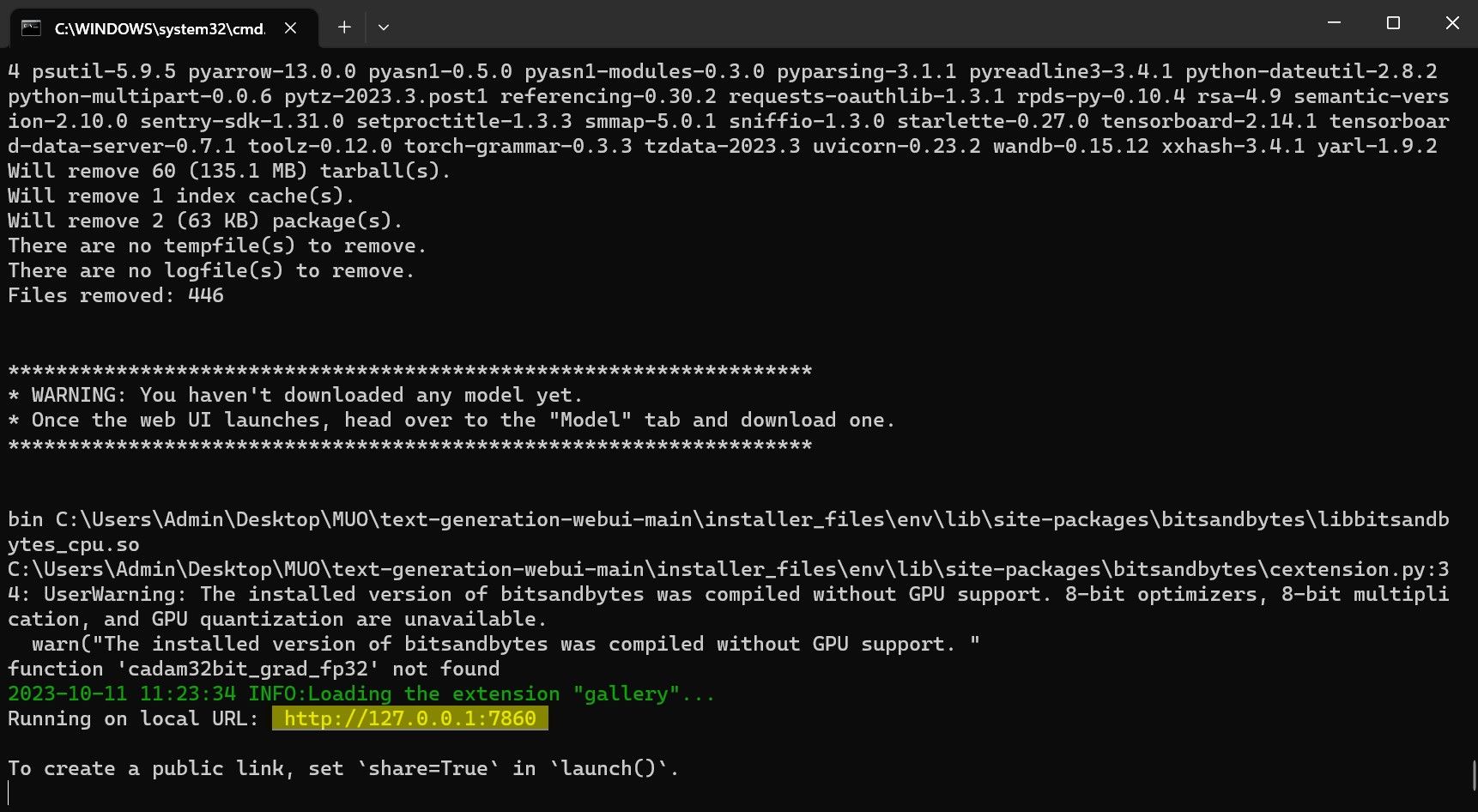
⭐ A WebUI está agora pronta a ser utilizada. 
Embora o software sirva como carregador de modelos, é necessário obter o Llama 2 para iniciar a sua funcionalidade.
Etapa 3: Descarregar o modelo Llama 2
Ao selecionar uma iteração do Llama 2, é importante ter em conta vários factores. Estes podem incluir parâmetros, quantização, otimização de hardware, dimensões e utilização pretendida, todos os quais podem ser discernidos a partir da designação do modelo.
A magnitude dos parâmetros utilizados para efeitos de formação pode ser considerada como um parâmetro. Geralmente, valores mais elevados deste parâmetro resultam em modelos mais competentes, embora esse aumento possa ser efectuado à custa da eficiência.
standard e chat. A variante chat foi especificamente ajustada para ser utilizada com agentes de conversação, como os chatbots, enquanto a versão standard é a opção predefinida.
O processo de otimização do hardware para a execução eficiente de modelos de aprendizagem automática pode ser classificado como otimização de hardware. Ele envolve a determinação do tipo específico de plataforma de hardware que forneceria o desempenho ideal para um modelo específico. Por exemplo, o GPT-Q foi concebido e optimizado para funcionar eficazmente em unidades de processamento gráfico dedicadas (GPUs), enquanto o GGML funciona eficazmente em unidades de processamento central (CPUs). Esta distinção realça a importância de selecionar as configurações de hardware adequadas com base nos requisitos exclusivos de cada modelo de aprendizagem automática respetivo, de modo a atingir os níveis desejados de desempenho e eficiência.
A quantização refere-se ao processo de redução do intervalo ou nível de valores atribuídos a pesos e activações num modelo de aprendizagem automática durante a inferência. A otimização da quantização para uma computação eficiente envolve a definição de um limiar de precisão específico, como q4, que denota um determinado nível de detalhe ou granularidade nos valores de peso e ativação.
O termo “Tamanho”, neste contexto, refere-se às dimensões ou escala de um determinado modelo, que pode ser expresso em termos das suas medidas físicas ou de outras unidades de medida relevantes.
Note-se que certos modelos podem ser estruturados de forma diferente e podem não apresentar formatos de apresentação de dados idênticos. No entanto, essa nomenclatura é predominante no mercado

O presente exemplo pode ser caracterizado como uma arquitetura Llama 2 de proporções moderadas, que foi treinada utilizando 13 mil milhões de parâmetros e adaptada especificamente para a inferência conversacional através do emprego de uma unidade central de processamento (CPU) dedicada.
Para os indivíduos que utilizam uma GPU dedicada, recomendamos a seleção de um modelo GPT-3 (GPT-3 Q). Por outro lado, os utilizadores que dependem de uma CPU devem optar pelo GGML. Se preferir interagir com a IA de uma forma conversacional semelhante ao ChatGPT, considere escolher a opção “chat”. No entanto, se pretender explorar toda a gama de capacidades da IA, utilize o modelo padrão. Em termos de definições, tenha em atenção que os modelos mais extensos produzem geralmente resultados superiores, mas podem resultar numa diminuição da eficiência. Pessoalmente, sugiro começar com uma configuração de modelo 7B. Relativamente à quantização, é importante notar que a definição ‘q4’ se destina apenas a fins de inferência e não a treino ou otimização.
Descarregar: GGML (Gratuito)
Descarregar: GPTQ (Gratuito)
No contexto da utilização de uma versão específica do Llama 2, por favor, proceda à aquisição do modelo desejado para as suas necessidades.
Tendo em conta a minha configuração atual como utilizador de um ultrabook, tenciono utilizar um Modelo de Jogo Generalizado (GG
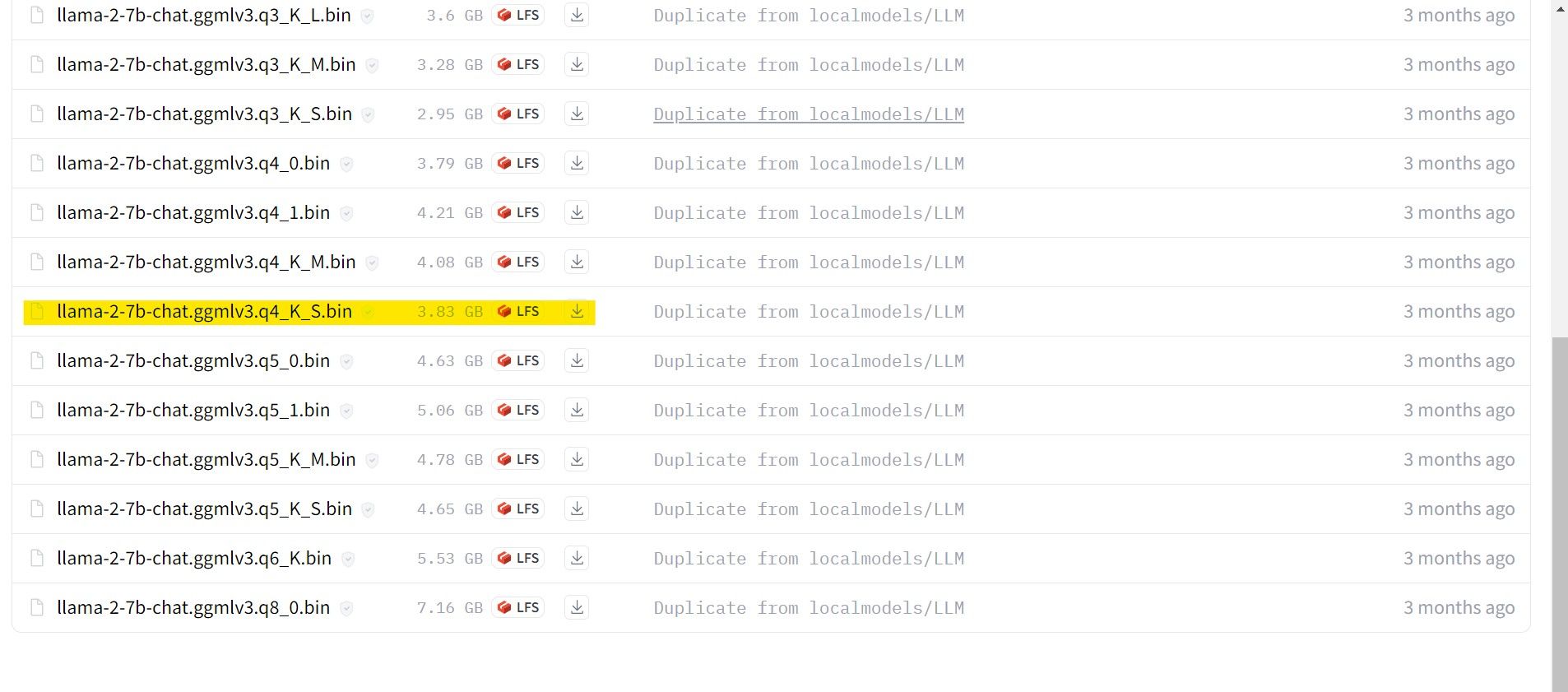
Uma vez concluído o processo de transferência, certifique-se de que transfere o modelo supracitado para o diretório “text-generation-webui-main”, que se encontra na pasta “models”.
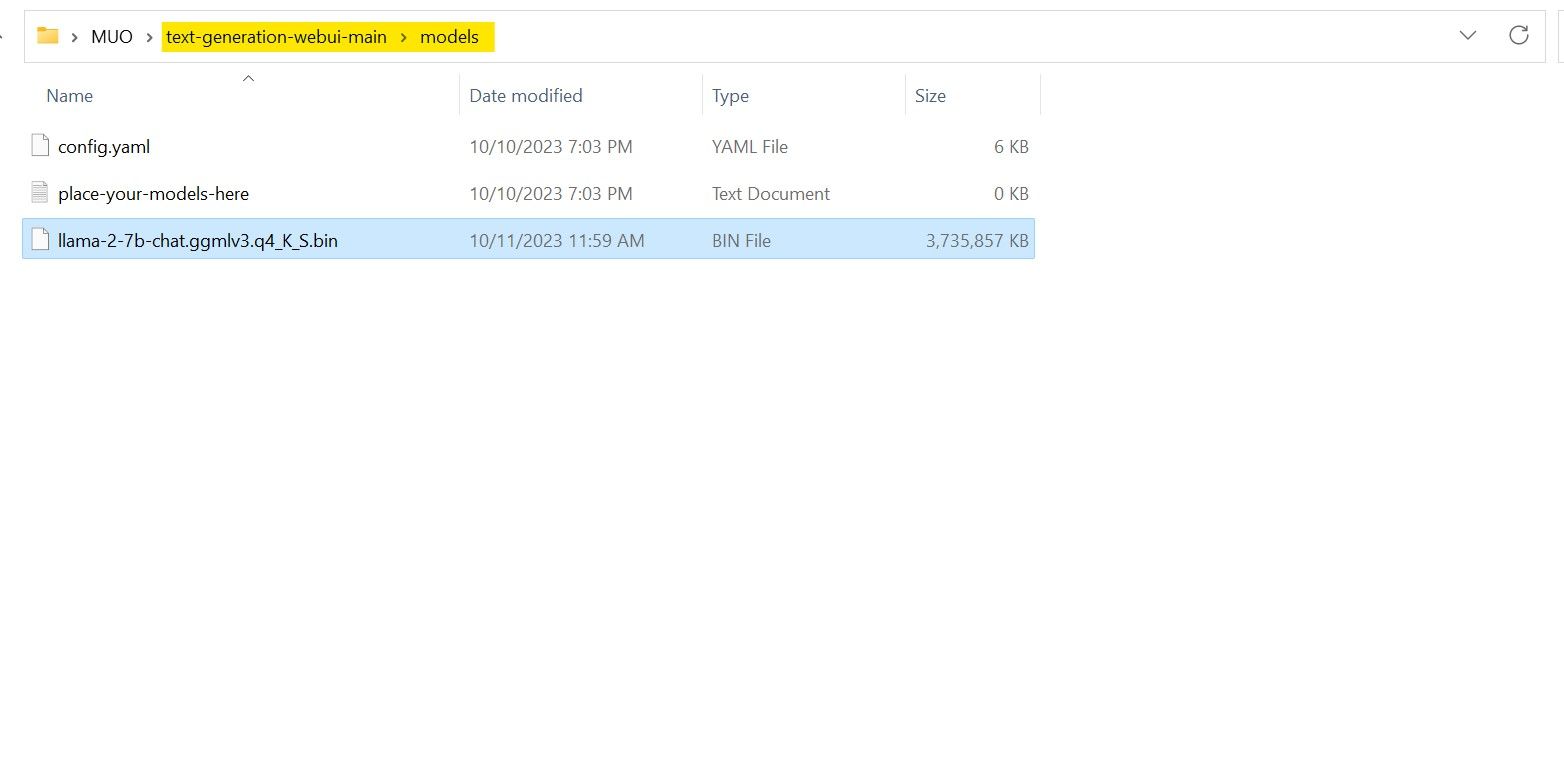
Com o modelo descarregado e armazenado no diretório “models” designado, é imperativo proceder à configuração dos componentes necessários para carregar o referido modelo.
Passo 4: Configurar o Text-Generation-WebUI
Agora, vamos começar a fase de configuração.
Para iniciar o funcionamento do Text-Generation-WebUI no seu sistema operativo, execute o comando de arranque adequado, tal como descrito nos passos anteriores.
Por favor, abstenha-se de usar palavrões ou linguagem vulgar nesta plataforma. Vamos manter um tom profissional na nossa comunicação.
⭐ Agora, clique no menu pendente do carregador de modelos e seleccione AutoGPTQ para os que utilizam um modelo GTPQ e ctransformers para os que utilizam um modelo GGML. Finalmente, clique em Carregar para carregar o seu modelo. 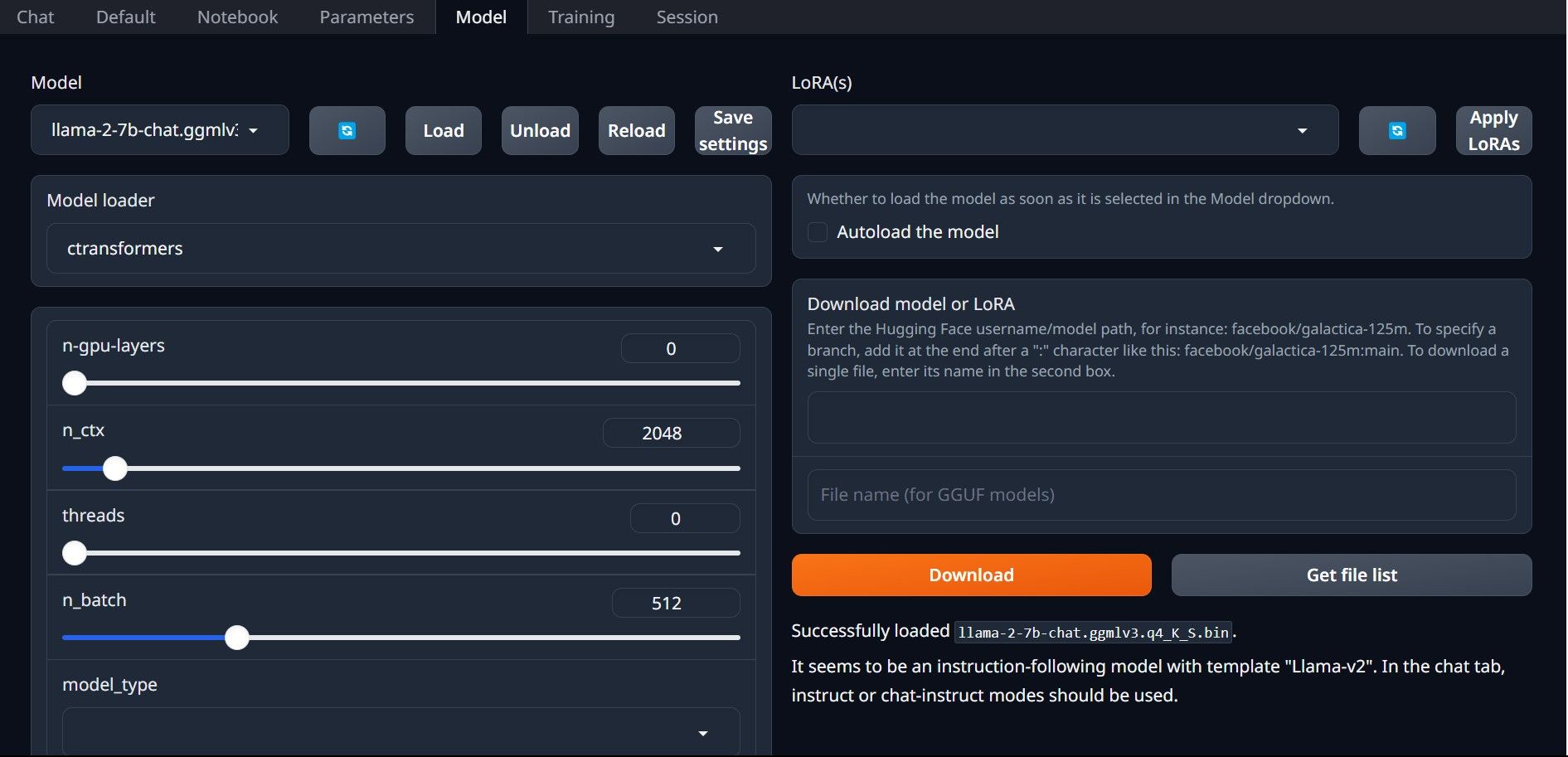
⭐ Para utilizar o modelo, abra o separador Chat e comece a testar o modelo. 
Parabéns, instalou com sucesso o Llama2 na sua máquina local!
Experimente outros LLMs
Agora que adquiriu a capacidade de executar a Llama 2 através da utilização da Text-Generation-WebUI no seu computador pessoal, julgo que pode utilizar outros Avatares de Modelos de Língua para além da Llama. Para o fazer, tenha em conta a nomenclatura utilizada para identificar estes avatares e note que apenas os que têm uma precisão numérica reduzida (normalmente designados por “q4”) podem ser utilizados em dispositivos informáticos normais. Uma grande quantidade de modelos que passaram por este processo de quantificação pode ser encontrada no vasto repositório do HuggingFace. Se quiseres ir mais longe no reino dos avatares alternativos, uma pesquisa por TheBloke na biblioteca acima mencionada produzirá uma abundância de opções das quais