Como melhorar o seu código Python com simultaneidade e paralelismo
Conclusões principais
A simultaneidade e o paralelismo representam princípios essenciais do desempenho de tarefas computacionais, possuindo cada um deles atributos únicos que os diferenciam um do outro.
A simultaneidade permite a alocação eficaz de recursos e maior capacidade de resposta em aplicações, enquanto o paralelismo desempenha um papel vital na obtenção de desempenho máximo e capacidades de escalonamento.
Python oferece uma variedade de abordagens para gerir operações concorrentes, incluindo a utilização de threads através da sua biblioteca de threading integrada, bem como suporte para programação assíncrona utilizando a estrutura asyncio. Além disso, o módulo de multiprocessamento permite que os programadores aproveitem o poder do processamento paralelo nas suas aplicações.
A simultaneidade refere-se à capacidade de um sistema de executar vários processos ou threads ao mesmo tempo, enquanto o paralelismo é a capacidade de dividir uma tarefa em subtarefas menores e executá-las simultaneamente por diferentes partes do sistema. Em Python, existem várias abordagens disponíveis para gerir a concorrência e o paralelismo, como o multiprocessamento, o encadeamento, a programação assíncrona com async/await e a utilização de bibliotecas como Celery ou Dask para computação distribuída. No entanto, estas opções podem gerar confusão ao decidir qual a abordagem mais adequada para uma situação específica.
Aprofunde-se no conjunto de recursos e estruturas que podem efetivamente facilitar a implementação de técnicas de programação simultânea em Python, bem como suas distinções entre si.
Compreender a simultaneidade e o paralelismo
A simultaneidade e o paralelismo são dois conceitos importantes que descrevem a forma como as tarefas são executadas em sistemas informáticos, cada um com os seus atributos únicos.
⭐ A simultaneidade é a capacidade de um programa gerir várias tarefas ao mesmo tempo, sem necessariamente as executar ao mesmo tempo. A ideia gira em torno da ideia de intercalar tarefas, alternando entre elas de uma forma que pareça simultânea. 
⭐ O paralelismo, por outro lado, envolve a execução de várias tarefas genuinamente em paralelo. Normalmente, tira partido de múltiplos núcleos de CPU ou processadores. O paralelismo consegue uma verdadeira execução simultânea, permitindo-lhe executar tarefas mais rapidamente, e é adequado para operações computacionalmente intensivas. 
A importância da concorrência e do paralelismo
A importância do processamento concorrente e paralelo na computação é indiscutível, uma vez que permite a execução de várias tarefas em simultâneo, aumentando assim a eficiência e reduzindo o tempo de execução global.Esta abordagem tornou-se cada vez mais importante devido à procura crescente de capacidades de processamento mais rápidas e eficientes numa vasta gama de aplicações, desde simulações científicas à automatização do fluxo de trabalho empresarial. Ao tirar partido do poder dos processadores multi-core e dos sistemas distribuídos, o processamento concorrente e paralelo permite uma melhor utilização dos recursos e uma maior escalabilidade, conduzindo, em última análise, a um melhor desempenho e a uma maior produtividade.
A atribuição optimizada de recursos é possível através da concorrência, uma vez que permite a exploração eficaz dos activos do sistema, garantindo que os processos continuam a avançar de forma produtiva em vez de ficarem passivamente à espera de recursos externos.
A capacidade de melhorar a capacidade de resposta das aplicações, especialmente no que diz respeito à interface do utilizador e às interacções com o servidor Web, é uma vantagem notável associada à concorrência.
É possível obter um melhor desempenho através do paralelismo, especialmente em tarefas computacionais que dependem fortemente de unidades centrais de processamento (CPU), como cálculos complexos, manipulação de dados e simulações de modelos.
A escalabilidade é um aspeto crítico da conceção de sistemas, exigindo tanto a execução simultânea como o processamento paralelo para obter um desempenho ótimo à escala. A capacidade de lidar com cargas de trabalho crescentes, mantendo a eficiência, é fundamental no desenvolvimento de software moderno.
Tendo em conta as tendências emergentes na tecnologia de hardware que dão prioridade às capacidades de processamento multi-core, tornou-se imperativo que os sistemas de software aproveitem eficazmente o paralelismo para garantir a sua viabilidade e sustentabilidade a longo prazo.
Concurrency in Python
A execução simultânea pode ser obtida em Python através da utilização de técnicas de threading ou assíncronas, que são facilitadas pela biblioteca asyncio.
Threading em Python
Threading é uma caraterística intrínseca da programação Python que permite a criação e gestão de múltiplas tarefas concorrentes num processo unificado. Este mecanismo revela-se especialmente vantajoso para tarefas com operações pesadas de entrada/saída ou para aquelas que podem beneficiar da execução paralela.
O módulo de threading do Python fornece uma interface de alto nível para criar e gerir threads. Embora o GIL (Global Interpreter Lock) limite as threads em termos de paralelismo real, elas ainda podem alcançar a simultaneidade intercalando tarefas de forma eficiente.
O código fornecido demonstra uma instância de programação simultânea através da utilização de threads em Python.Especificamente, utiliza a biblioteca Python Request para iniciar um pedido HTTP, que é uma operação típica que envolve operações de entrada-saída (I/O) e pode resultar em tarefas de bloqueio. Além disso, o código utiliza o módulo de tempo para determinar a duração da execução do programa.
import requests
import time
import threading
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# function to request a URL
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
# Execute without threads and measure execution time
start_time = time.time()
for url in urls:
download_url(url)
end_time = time.time()
print(f"Sequential download took {end_time - start_time:.2f} seconds\n")
# Execute with threads, resetting the time to measure new execution time
start_time = time.time()
threads = []
for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
# Wait for all threads to complete
for thread in threads:
thread.join()
end_time = time.time()
print(f"Threaded download took {end_time - start_time:.2f} seconds")
De facto, a execução deste programa revela um aumento percetível da eficiência quando se utilizam threads concorrentes para realizar operações de E/S intensivas, apesar da disparidade de tempo marginal entre as execuções sequenciais e paralelas.
Programação assíncrona com Asyncio
asyncio fornece um loop de eventos que gerencia tarefas assíncronas chamadas coroutines. As corrotinas são funções que podem ser pausadas e retomadas, o que as torna ideais para tarefas vinculadas a E/S. A biblioteca é particularmente útil para cenários em que as tarefas envolvem a espera por recursos externos, como solicitações de rede.
Para adaptar o exemplo anterior de envio de pedidos síncronos para utilização com programação assíncrona em Python, teria de efetuar algumas alterações. Em primeiro lugar, em vez de utilizar requests.get() e time.sleep() , que são operações de bloqueio que pausam a execução até à conclusão ou ao tempo decorrido, respetivamente, deve utilizar alternativas não bloqueantes, como asyncio e aiohttp . Isto implica envolver o código existente numa função assíncrona utilizando async def , e substituir as operações de E/S tradicionais pelas suas contrapartes assíncronas. Por exemplo, async with aiohttp.ClientSession().post(url) poderia ser usado para enviar um pedido POST de forma assíncrona sem esperar por uma resposta. Além disso, o tratamento de erros e o registo podem também necessitar de ajustes para acomodar a nova estrutura assíncrona.
import asyncio
import aiohttp
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# asynchronous function to request URL
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"Downloaded {url} - Status Code: {response.status}")
# Main asynchronous function
async def main():
# Create a list of tasks to download each URL concurrently
tasks = [download_url(url) for url in urls]
# Gather and execute the tasks concurrently
await asyncio.gather(*tasks)
start_time = time.time()
# Run the main asynchronous function
asyncio.run(main())
end_time = time.time()
print(f"Asyncio download took {end_time - start_time:.2f} seconds")
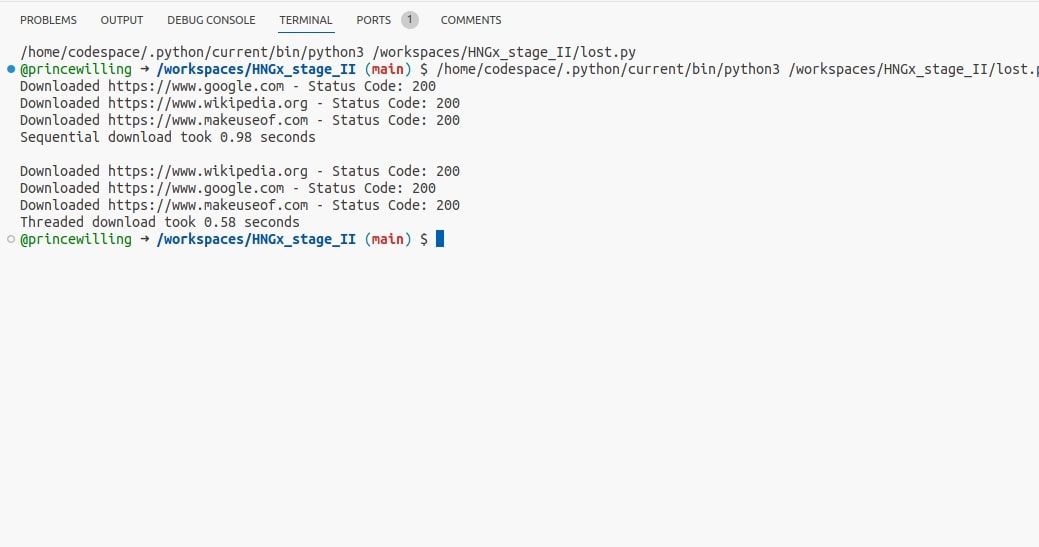
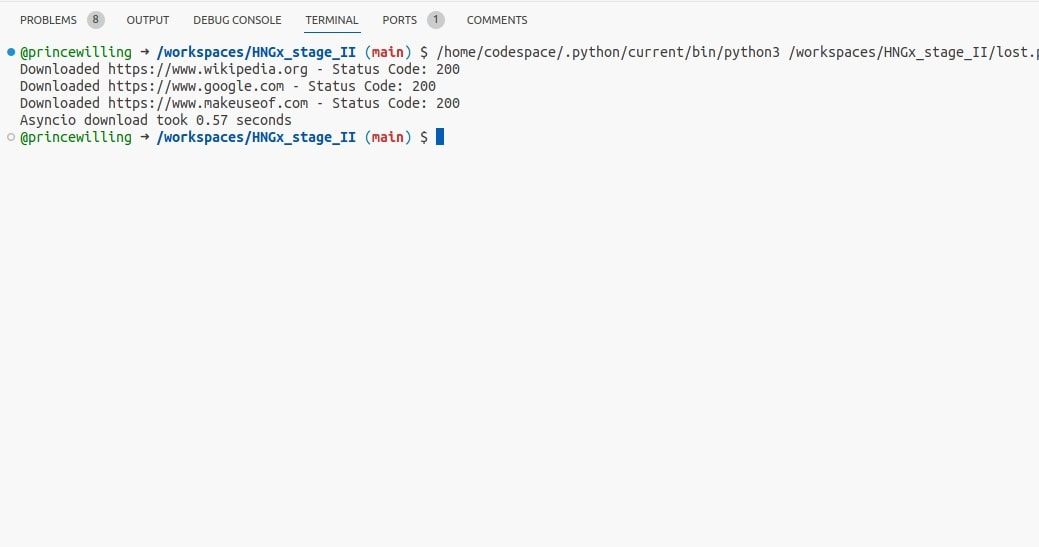
Utilizando o código fornecido, é possível executar com eficiência vários downloads simultâneos de páginas da Web, aproveitando os recursos do asyncio e aproveitando o poder das operações de E/S assíncronas. Ao contrário das técnicas tradicionais de threading, que são mais adequadas para tarefas intensivas de CPU, esta abordagem é particularmente eficaz na otimização de processos ligados a E/S.
Paralelismo em Python
Pode implementar o paralelismo utilizando o módulo de multiprocessamento do Python , que lhe permite tirar o máximo partido dos processadores multicore.
Multiprocessamento em Python
O módulo de multiprocessamento do Python oferece uma abordagem para aproveitar o paralelismo através da criação de processos individuais, cada um equipado com seu intérprete Python distinto e domínio de memória. Ao fazê-lo, este método contorna o Bloqueio do Interpretador Global (GIL) que é comummente encontrado em tarefas ligadas à CPU.
import requests
import multiprocessing
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# function to request a URL
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
def main():
# Create a multiprocessing pool with a specified number of processes
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)
start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
# Close the pool and wait for all processes to finish
pool.close()
pool.join()
print(f"Multiprocessing download took {end_time-start_time:.2f} seconds")
main()
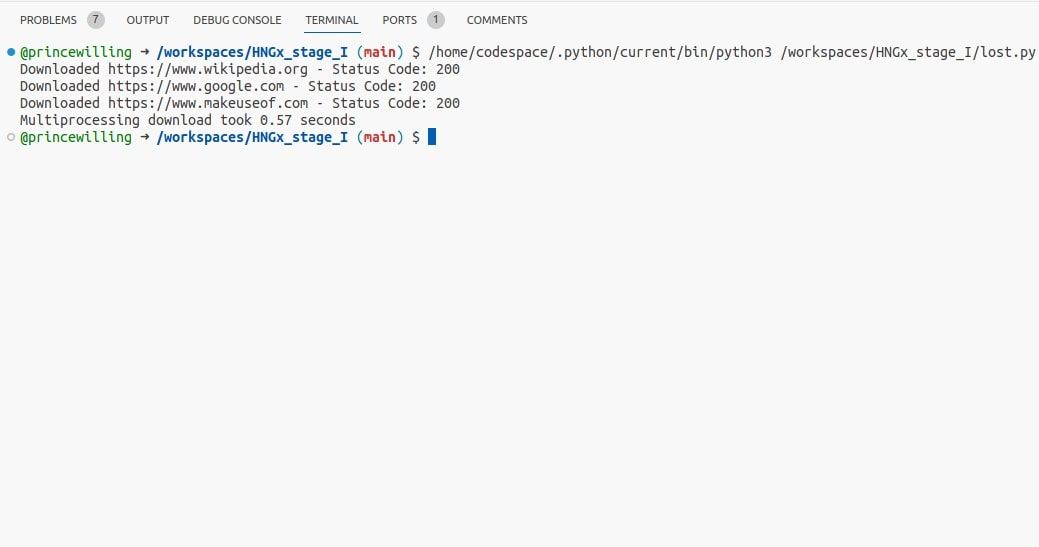
O multiprocessamento permite a execução simultânea da função download_url em vários processos, facilitando assim o processamento paralelo do URL fornecido.
Quando utilizar a simultaneidade ou o paralelismo
A decisão de optar pelo processamento simultâneo ou pelo processamento paralelo depende das características das operações que estão a ser executadas e da capacidade dos recursos de hardware do sistema subjacente.
Ao lidar com operações centradas na entrada/saída (E/S), como operações de leitura/escrita de ficheiros ou pedidos de ligação em rede, recomenda-se a utilização de concorrência devido à sua capacidade de lidar com várias tarefas em simultâneo. Além disso, pode ser utilizada em situações em que as limitações de memória representam um desafio.
Quando a utilização de multiprocessamento é apropriada para operações com uso intensivo de CPU que podem ser melhoradas pela execução simultânea e quando garantir uma separação robusta de processos é uma prioridade, uma vez que a falha de cada processo não deve afetar indevidamente os outros.
Tirar proveito da simultaneidade e do paralelismo
O paralelismo e a execução simultânea são métodos viáveis para aumentar a eficiência e o rendimento dos programas Python. No entanto, é crucial compreender as diferenças entre essas técnicas para tomar uma decisão informada sobre qual abordagem é mais adequada para uma situação específica.
O Python fornece um conjunto abrangente de ferramentas e módulos que permitem aos programadores melhorar a eficiência do seu código, tirando partido de técnicas de processamento paralelo ou concorrente, independentemente de as tarefas em causa serem principalmente de natureza computacional ou de entrada/saída intensiva.