Scikit-LLM gebruiken voor tekstanalyse met grote taalmodellen
Scikit-LLM is een Python-pakket dat helpt bij het integreren van grote taalmodellen (LLM’s) in het scikit-learn framework. Het helpt bij het uitvoeren van tekstanalysetaken. Als je bekend bent met scikit-learn, kun je gemakkelijker met Scikit-LLM werken.
Het moet duidelijk zijn dat Scikit-LLM en scikit-learn verschillende doelen dienen, waarbij de eerste is toegesneden op tekstanalysetaken terwijl de laatste dient als een meer uitgebreide machine-learningbibliotheek voor algemeen gebruik.
Aan de slag met Scikit-LLM
Om aan de slag te gaan met Scikit-LLM , moet u de bibliotheek installeren en uw API-sleutel configureren. Om de bibliotheek te installeren, opent u uw IDE en maakt u een nieuwe virtuele omgeving aan. Dit voorkomt mogelijke bibliotheekversieconflicten. Voer vervolgens het volgende commando uit in de terminal.
pip install scikit-llm
Het uitvoeren van deze instructie vergemakkelijkt de installatie van Scikit-LLM, samen met alle noodzakelijke vereisten.
Om uw API-sleutel voor uw Large Language Model (LLM) serviceprovider in te stellen, moet u er een van hen verkrijgen. Als u een OpenAI API-sleutel zoekt, volg dan het volgende proces:
Ga naar de OpenAI API-pagina . Klik vervolgens op je profiel in de rechterbovenhoek van het venster. Selecteer Bekijk API-sleutels . Zo kom je op de pagina met API-sleutels.
Om toegang te krijgen tot de pagina API-sleutels en een nieuwe geheime sleutel aan te maken, volgt u deze stappen op een geraffineerde manier:1. Navigeer naar de aangewezen webpagina waar de API-sleutels worden beheerd binnen het dashboard of controlepaneel van uw applicatie. Dit kan toegankelijk zijn via het hoofdmenu onder “Instellingen” of “Integraties”. Als je eenmaal op de juiste pagina bent, zoek dan het gedeelte op dat gewijd is aan het beheren van je API-sleutels. Deze bevindt zich waarschijnlijk bovenaan de pagina of wordt weergegeven als een optie in een vervolgkeuzemenu.3. Zoek in dit gedeelte naar een opvallende knop met de tekst “Nieuwe geheime sleutel aanmaken”, waarmee het proces voor het genereren van een nieuwe API-sleutel wordt gestart. Als een dergelijke knop niet aanwezig is, zoek dan naar andere aanwijzingen of instructies die je op weg kunnen helpen naar
Maak een API-sleutel aan door op de knop “Create Secret Key” te klikken om de benodigde gegevens te genereren. Het is belangrijk dat je deze informatie vervolgens veilig opslaat, aangezien Open AI niet de mogelijkheid biedt om deze later op te halen. In het geval dat je de sleutel kwijtraakt, moet je een nieuwe sleutel aanmaken.
De volledige broncode is toegankelijk via eenGitHub-repository, die ontwikkelaars eenvoudig toegang biedt en mogelijkheden biedt om samen te werken aan projecten en bij te dragen aan de ontwikkeling van open-source software.
Nadat u uw API-sleutel hebt verkregen, navigeert u naar de geïntegreerde ontwikkelomgeving van uw voorkeur (IDE) en integreert u de module SKLLMConfig in de Scikit-LLM-bibliotheek. Deze integratie maakt het mogelijk om configureerbare parameters met betrekking tot het gebruik van uitgebreide taalkundige modellen te manipuleren.
from skllm.config import SKLLMConfig
Zorg ervoor dat u uw Open AI API-sleutel en relevante organisatorische informatie voor deze cursus hebt opgegeven, aangezien dit een voorwaarde is voor een succesvolle afronding.
# Set your OpenAI API key
SKLLMConfig.set_openai_key("Your API key")
# Set your OpenAI organization
SKLLMConfig.set_openai_org("Your organization ID")
De organisatie-ID en de naam zijn niet hetzelfde. De organisatie-ID is een unieke identificatie van uw organisatie. Om uw organisatie-ID te verkrijgen, gaat u naar de OpenAI Organization instellingenpagina en kopieert u deze. U hebt nu een verbinding tot stand gebracht tussen Scikit-LLM en het grote taalmodel.
Voor Scikit-LLM is een abonnement op een pay-as-you-go service nodig, omdat het beperkte quotum van de gratis OpenAI account, met de beperking van drie verzoeken per minuut, niet voldoende is voor optimale prestaties met Scikit-LLM.
Als u een gratis proefaccount gebruikt, kan er een foutmelding zoals de volgende verschijnen wanneer u tekstanalyse probeert uit te voeren.

Voor meer informatie over snelheidslimieten. Ga naar de pagina OpenAI-snelheidslimieten .
Het gebruik van een LLM-platform gaat verder dan alleen vertrouwen op Open AI; er zijn alternatieve LLM-serviceproviders die in aanmerking komen voor uw behoeften.
De benodigde bibliotheken importeren en de dataset laden
Gebruik de pandas bibliotheek om de dataset te openen en te verwerken. Importeer daarnaast de benodigde klassen uit de bibliotheken Scikit-LLM en scikit-learn .
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
Om te beginnen importeer en laad je de gegevensset die je wilt analyseren op tekstuele inhoud. In dit voorbeeld gebruiken we de IMDB-filmdatabase als referentie, maar je kunt deze aanpassen aan de dataset van je voorkeur.
# Load your dataset
data = pd.read_csv("imdb_movies_dataset.csv")
# Extract the first 100 rows
data = data.head(100)
Je hebt de optie om alle gegevens in je dataset te gebruiken, in plaats van beperkt te zijn tot alleen de eerste 100 rijen.
Vervolgens extraheren we de kenmerk- en labelkolommen uit onze dataset, waarna we deze opsplitsen in een trainingsset en een testset voor verdere analyse.
# Extract relevant columns
X = data['Description']
# Assuming 'Genre' contains the labels for classification
y = data['Genre']
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
De classificatiecategorie omvat de aanduidingen die bedoeld zijn voor voorspelling, in deze context aangeduid met de term “Genre”.
Zero-Shot Tekstclassificatie met Scikit-LLM
Grote taalmodellen kunnen tekstclassificatie met zero-shot uitvoeren, wat inhoudt dat gegevens zonder label worden gecategoriseerd in vooraf gedefinieerde klassen zonder dat er eerst training met gelabelde informatie nodig is. Deze aanpak blijkt vooral voordelig te zijn in situaties waarin teksten moeten worden ingedeeld in ongedefinieerde categorieën die buiten de ontwikkelingsfase van het model vallen.
Om een zero-shot tekstclassificatietaak uit te voeren met Scikit-LLM, kunt u de klasse ZeroShotGPTClassifier gebruiken.
# Perform Zero-Shot Text Classification
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
# Print Zero-Shot Text Classification Report
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))
De uitvoer is als volgt:
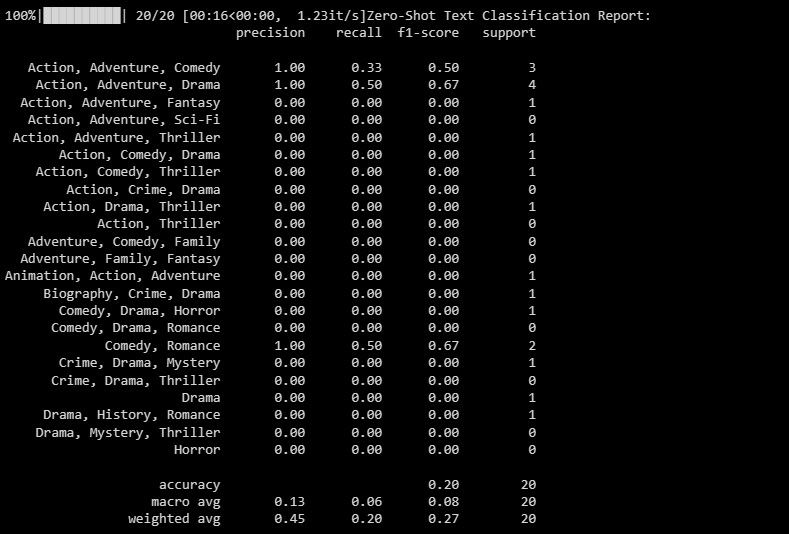
Het classificatierapport biedt kwantitatieve metingen met betrekking tot elk van de labels die het model probeert te classificeren.
Multi-Label Zero-Shot Tekstclassificatie met Scikit-LLM
In bepaalde situaties is het niet ongewoon dat een bepaald stuk tekst onder meer dan één categorie tegelijk valt. Conventionele classificatiemethoden zijn slecht uitgerust om zulke gevallen effectief te behandelen. Door zijn geavanceerde mogelijkheden heeft Scikit-LLM echter laten zien dat het uitzonderlijk goed in staat is om deze complexiteit aan te pakken door tekstclassificatie met meerdere labels en nul-op-de-meter mogelijk te maken. Deze aanpak houdt in dat er meerdere beschrijvende labels aan één tekstmonster worden gekoppeld, wat van groot belang is voor het nauwkeurig vastleggen en categoriseren van informatie in verschillende domeinen.
Gebruik de MultiLabelZeroShotGPTClassifier om vast te stellen welk label of welke labels van toepassing zijn op elk gegeven tekstfragment.
# Perform Multi-Label Zero-Shot Text Classification
# Make sure to provide a list of candidate labels
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
# Convert the labels to binary array format using MultiLabelBinarizer
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
# Print Multi-Label Zero-Shot Text Classification Report
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
Hierboven stellen we de mogelijke aanduidingen vast waaraan onze tekst als kanshebber kan worden toegewezen.
De uitvoer ziet er als volgt uit:
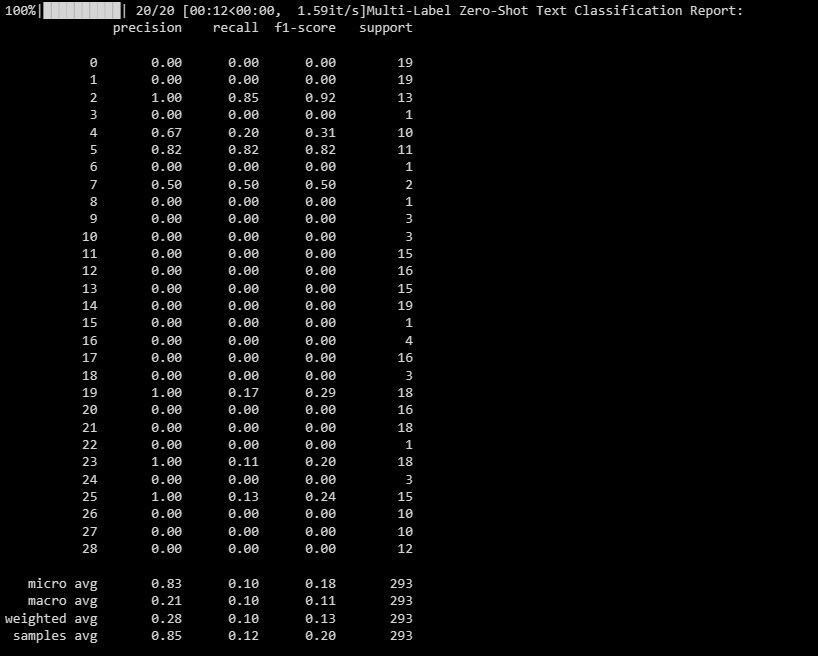
Dit document dient om de prestaties van uw model over verschillende labels in een multilabel classificatiescenario te belichten, en biedt waardevolle inzichten in de effectiviteit ervan met betrekking tot elke afzonderlijke aanwijzing.
Tekstvectorisatie met Scikit-LLM
Scikit-LLM biedt de GPTVectorizer, waarmee tekstgegevens kunnen worden omgezet in een numerieke vorm die begrijpelijk is voor machine-learningalgoritmen door middel van tekstvectorisatie.Bij dit transformatieproces wordt tekst omgezet in vectoren met vaste dimensies met behulp van GPT-modellen.
Eén benadering om dit te bereiken is door gebruik te maken van de Term Frequency-Inverse Document Frequency-methode.
# Perform Text Vectorization using TF-IDF
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
# Print the TF-IDF vectorized features for the first few samples
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5]) # Change to X_test_tfidf if you want to print the test set
Hier is de uitvoer:
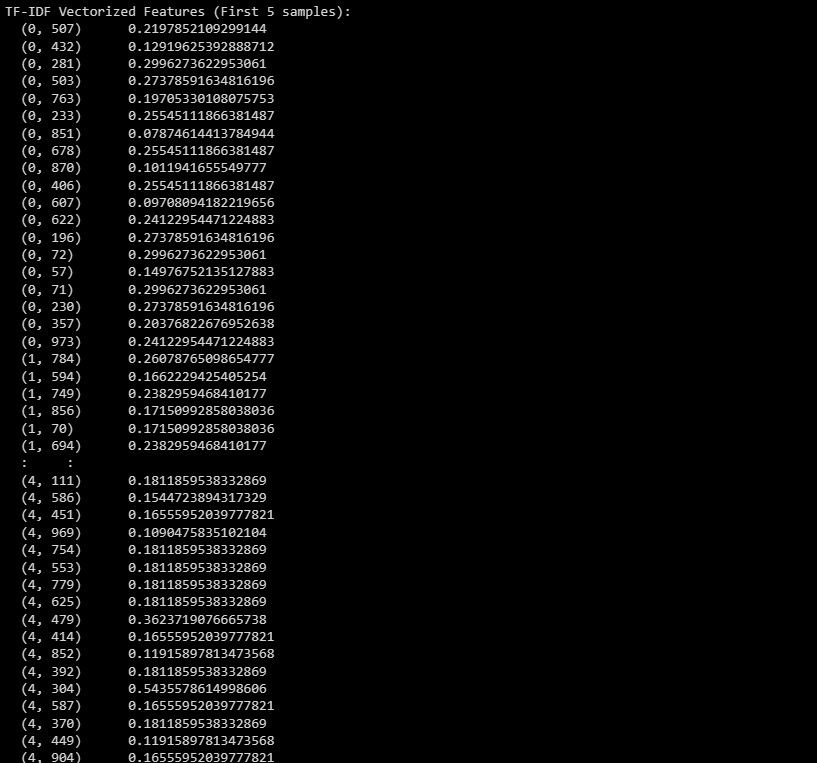
De bovenstaande informatie heeft betrekking op de getransformeerde representatie van de eerste vijf instanties in de dataset, die wordt aangeduid als het TF-IDF-vectorisatieresultaat.
Tekstsamenvatting met Scikit-LLM
Tekstsamenvatting is een proces waarbij een geschreven werk wordt gecomprimeerd met behoud van de essentiële inhoud. De GPTSummarizer, beschikbaar via de Scikit-LLM bibliotheek, gebruikt geavanceerde taalmodellen gebaseerd op de GPT architectuur om beknopte samenvattingen van teksten te maken.
# Perform Text Summarization
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
De uitvoer is als volgt:
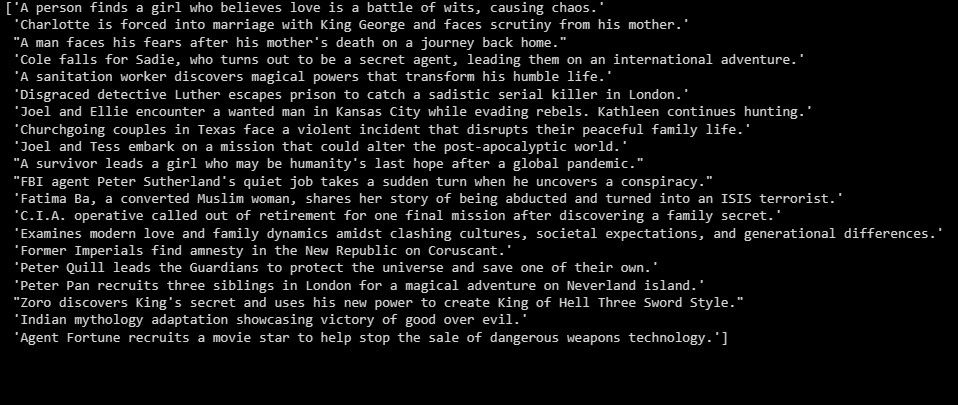
Het voorgaande dient als een overzicht van de experimentele bevindingen.
Bouw toepassingen bovenop LLM’s
Scikit-LLM biedt een uitgebreide reeks mogelijkheden om tekst uitgebreid te onderzoeken met geavanceerde taalmodellen. Het begrijpen van de basisprincipes van de technologische onderbouwing van deze modellen is essentieel, omdat het een grondig begrip van hun krachtige mogelijkheden en beperkingen mogelijk maakt. Dit is van groot belang bij het bouwen van goed presterende softwareoplossingen op basis van deze state-of-the-art innovatie.