De aggregatiepijplijn gebruiken in MongoDB
De aggregatie pijplijn is de aanbevolen manier om complexe queries uit te voeren in MongoDB. Als je MapReduce van MongoDB hebt gebruikt, kun je beter overstappen op de aggregatie pijplijn voor efficiëntere berekeningen.
Wat is aggregatie in MongoDB en hoe werkt het?
De aggregatie pijplijn, ook bekend als de “Agg” pijplijn, is een uitgebreid query mechanisme in MongoDB dat complexe data analyse en manipulatie vergemakkelijkt. Door gebruik te maken van een reeks onderling verbonden stappen, stelt deze pijplijn gebruikers in staat om verschillende bewerkingen uit te voeren op hun datasets door de uitvoer van één stap te gebruiken als invoer voor volgende stappen. Met deze veelzijdige tool kunnen gebruikers hun gegevensverwerkingstaken stroomlijnen en tegelijkertijd de algehele efficiëntie en nauwkeurigheid verbeteren.
Het resultaat van een matchingsproces kan bijvoorbeeld naar volgende fasen worden gestuurd om opnieuw te worden gerangschikt volgens de genoemde ordening totdat de gewenste uitvoer is bereikt.
In de loop van een aggregatie pijplijn bestaat elke fase uit een MongoDB component en produceert een of meer gewijzigde documenten als output. De frequentie waarmee een bepaald niveau verschijnt binnen de pijplijn is afhankelijk van de specifieke aard van het onderzoek dat wordt gedaan. In sommige gevallen kan het nodig zijn om operatoren op te nemen zoals de
De fasen van de aggregatie pijplijn
De aggregatie pijplijn doorloopt gegevens door meerdere fasen in een enkele query. Er zijn verschillende stappen en je kunt hun details vinden in de MongoDB documentatie .
Laten we een aantal van de meest voorkomende termen in deze context afbakenen.
De $match-fase
In de eerste fase van dit proces kunnen precieze selectiecriteria worden vastgesteld, die kunnen worden gebruikt voordat de volgende aggregatiefasen worden gestart. Door deze voorbereidende stap te gebruiken, is men in staat om de specifieke datasetelementen te identificeren en te isoleren die relevant worden geacht voor opname in de bredere aggregatiepijplijn.
De $groepfase
De groeperingsfase organiseert informatie in verschillende categorieën door sleutelwaardeparen te gebruiken, waarbij elke categorie overeenkomt met een element in het eindrapport.
Beschouw de volgende illustratieve verkoopvoorbeeldgegevens als voorbeeld:
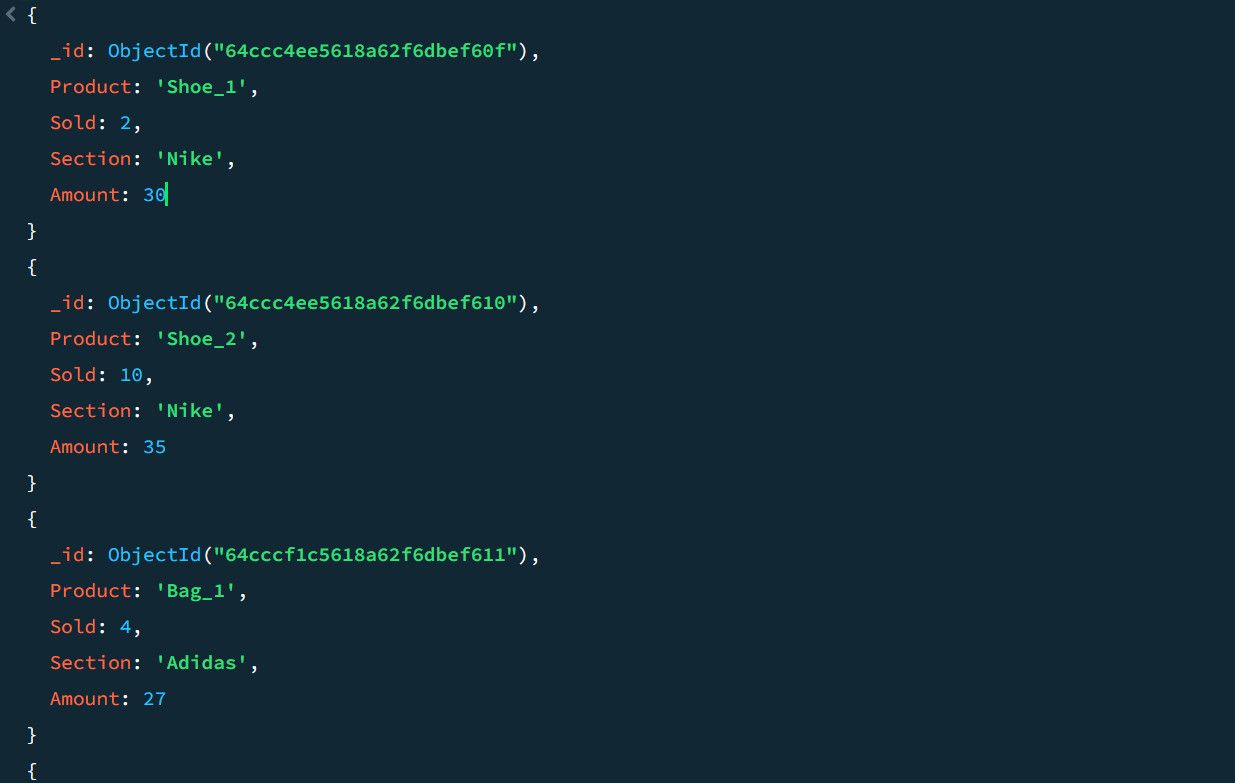
Het gebruik van een aggregatiepijplijn maakt de berekening mogelijk van zowel de totale verkoophoeveelheid als de producten met de hoogste omzet binnen elke respectieve categorie.
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
Met de groepeerfunctie van MongoDB kunnen documenten worden georganiseerd op basis van hun onderverdeling in secties. Dit wordt bereikt door het gebruik van het id-veld in combinatie met een gespecificeerde sleutel. Bij het gebruik van specifieke aggregatie operatoren zoals \ \ som, \ \ min, \ \ max, of \ \avg, genereert MongoDB nieuwe identifiers voor elke groep op basis van de operaties afgebakend in de aggregator.
De $skip-fase
Door gebruik te maken van de “$skip”-fase binnen een aggregatiepijplijn kan een vooraf bepaald aantal documenten uit de uiteindelijke resultaatverzameling worden weggelaten. Gewoonlijk wordt deze fase na de groeperingsfase gebruikt en dient om de uitvoer te stroomlijnen door de documenten uit te sluiten die niet gewenst zijn. Als bijvoorbeeld verwacht wordt dat er twee documenten geproduceerd worden, waarvan er één moet worden verwijderd, dan levert het aggregatieproces alleen het resterende document op.
Om een bypass-stap in de aggregatie-pijplijn op te nemen, kunt u de bewerking “$skip” erin introduceren.
...,
{
$skip: 1
},
De $sort-fase
Het sorteerproces maakt het mogelijk om informatie op een aflopende of oplopende manier te organiseren. Ter illustratie kan ervoor worden gekozen om de dataset uit het voorgaande onderzoeksscenario te herschikken met een aflopende orde van grootte om te onderscheiden welke afdeling de grootste omzet heeft.
Wijzig de voorgaande query door de operator “$sort” als volgt op te nemen:
...,
{
$sort: {top_sales: -1}
},
De $limit-fase
Het gebruik van de “limit”-operatie vergemakkelijkt het verkleinen van de gewenste uitvoerdocumenten van een aggregatiepijplijn. Om dit concept te illustreren, kunt u overwegen om de “$limit” operator toe te passen om de specifieke sectie op te halen die is geïdentificeerd als de sectie met het hoogste verkoopniveau in een voorgaande verwerkingsfase:
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}
Het bovengenoemde resultaat levert alleen het eerste document op; dit specifieke segment vormt het gedeelte met de hoogste omzet, omdat het de bovenste positie inneemt binnen de geordende lijst met uitkomsten.
De $project Stage
De richtlijn $project biedt een zekere mate van flexibiliteit met betrekking tot het vormgeven van de uiteindelijke uitvoer door de specificatie van gewenste velden en hun bijbehorende sleutelnamen mogelijk te maken.
Neem bijvoorbeeld een illustratief voorbeeld van de uitvoer zonder de “$project” stap, die er als volgt uit zou kunnen zien:
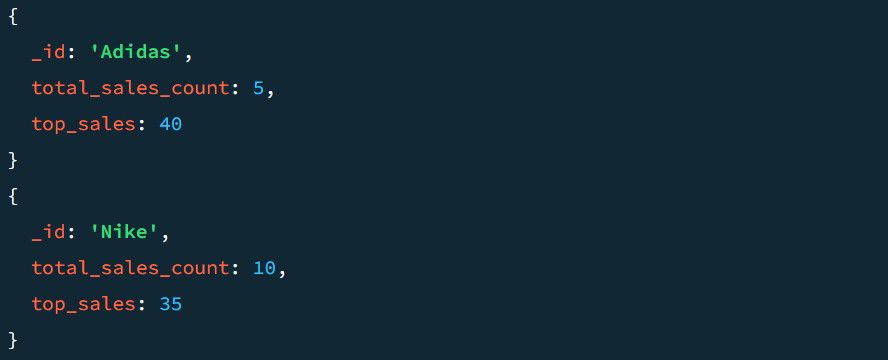
Om het project in onze pijplijn op te nemen, zullen we onderzoeken hoe het eruit ziet als het wordt geassocieerd met het label “$project”. Volg deze stappen om deze integratie te bereiken:
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
Rekening houdend met onze eerdere organisatie van de gegevens per productcategorie, neemt de bovengenoemde aanpak alle relevante productsecties op in het gegenereerde rapport. Bovendien garandeert het dat zowel het totale verkoopcijfer als het gemarkeerde best verkopende item worden geïntegreerd als onderdeel van de uiteindelijke uitvoer, respectievelijk weergegeven door de metriek “Totaal verkocht” en “Topverkoop”.
Het herziene resultaat vertoont een hogere mate van verfijning in vergelijking met zijn voorganger en laat een verbeterde organisatie en helderheid in presentatie zien.

De $unwind-fase
De unwind-fase in MongoDB is verantwoordelijk voor het deconstrueren van een array in een enkel document en het transformeren in meerdere documenten. Laten we ter illustratie de volgende voorbeelddataset met orders bekijken:
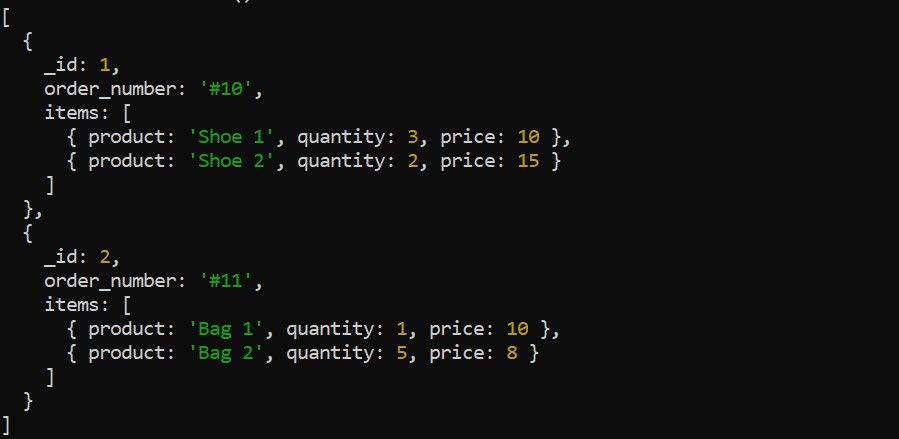
Het gebruik van de $unwind stap is een effectieve methode om de items array te ontleden voordat aanvullende aggregatiebewerkingen worden uitgevoerd. Deze stap is vooral handig als je een samenvattende statistiek probeert te berekenen voor elk element in de matrix. Als illustratief voorbeeld kunnen we de totale inkomsten berekenen die door individuele producten zijn gegenereerd.
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
])
Zeker, hier is een meer verfijnde weergave van het resultaat gegenereerd door de eerder genoemde aggregate onderzoek:

Hoe maak je een aggregatie pijplijn in MongoDB
De bovengenoemde fasen bieden een uitgebreid begrip van het toepassingsproces voor verschillende bewerkingen binnen de aggregatie pijplijn, met inbegrip van fundamentele query’s geassocieerd met elke fase.
Sta mij toe om een meer verfijnde weergave van de gegeven tekst te geven: In het licht van ons onderzoek van de voorgaande verkoopdataset, is het verstandig om een overzicht te geven van een aantal belangrijke stappen binnen de aggregatie pijplijn als geheel. Door dit te doen, kunnen we een uitgebreid perspectief krijgen op het proces dat betrokken is bij het transformeren van ruwe gegevens in zinvolle inzichten.
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])
Het eindproduct vertoont een opvallende gelijkenis met iets dat we al eerder zijn tegengekomen, wat gevoelens van vertrouwdheid en misschien zelfs deja vu’s oproept.
Aggregatiepijplijn vs. MapReduce
Voordat het werd verwijderd met versie 5.0 van MongoDB, was de traditionele methode voor het uitvoeren van gegevensaggregaties binnen de database het gebruik van MapReduce. Hoewel MapReduce een reeks potentiële toepassingen heeft buiten MongoDB, wordt het over het algemeen als minder efficiënt beschouwd in vergelijking met de aggregatiepijplijn, waardoor het gebruik van externe scripts nodig is om zowel de mapping- als de reductieprocessen afzonderlijk te definiëren.
Daarentegen biedt de aggregatie pijplijn in MongoDB een unieke methode voor het uitvoeren van ingewikkelde queries met behoud van een grotere efficiëntie en organisatie in vergelijking met andere benaderingen. Bovendien bevat deze pijplijn extra functies waarmee de resulterende uitvoer beter kan worden aangepast.
De overgang van MapReduce naar de aggregatie pijplijn presenteert een veelheid aan verschillen die men tegen kan komen tijdens dit proces.
Maak Big Data Queries Efficiënt in MongoDB
Om ingewikkelde informatie die is opgeslagen in MongoDB effectief te verwerken, is het cruciaal om je query’s te optimaliseren voor maximale efficiëntie. Gelukkig biedt de aggregatie pijplijn een uitstekende oplossing voor het uitvoeren van uitgebreide berekeningen op complexe datasets. In tegenstelling tot afzonderlijke bewerkingen die vaak ten koste gaan van de prestaties, stelt het aggregatieraamwerk gebruikers in staat om meerdere verwerkingsstappen te stroomlijnen in een zeer efficiënte, enkelvoudige pijplijn. Hierdoor kunnen deze omslachtige taken op een uniforme manier worden uitgevoerd met een hogere snelheid en nauwkeurigheid.
Het gebruik van indexering kan de prestaties van aggregatiebewerkingen in MongoDB aanzienlijk verbeteren, omdat het de hoeveelheid gegevens vermindert die in elke fase van het proces moet worden gescand.