Een chatbot bouwen met Streamlit en Llama 2
Llama 2 is een open-source groot taalmodel dat is ontwikkeld door Meta. Dit specifieke model heeft indrukwekkende mogelijkheden, waardoor het een geduchte concurrent is in vergelijking met andere gesloten modellen zoals GPT-3.5 en PaLM. Veel experts beweren zelfs dat Llama 2 deze alternatieven overtreft in termen van prestaties. De architectuur van dit model bestaat uit drie verschillende voorgetrainde en verfijnde generatieve tekstmodellen, elk met verschillende niveaus van complexiteit. Deze modellen omvatten versies met respectievelijk 7 miljard, 13 miljard en 70 miljard parameters.
Verdiep je in het dialogische potentieel van Llama 2 door een chatbot te bouwen die gebruik maakt van Streamlit en de mogelijkheden van Llama 2 om in realtime met gebruikers te communiceren.
Llama 2 begrijpen: functies en voordelen
Hoe afwijkend is Llama 2, de nieuwste iteratie van het grote taalmodel, in vergelijking met de vorige versie, Llama 1?
Het uitgebreide model heeft een aanzienlijk uitgebreide architectuur, met wel 70 miljard parameters. Een dergelijk uitgebreid aantal parameters vergemakkelijkt het verwerven van steeds complexere relaties die inherent zijn aan woordreeksen.
Reinforcement Learning from Human Feedback (RLHF) heeft zijn effectiviteit bewezen in het verbeteren van de mogelijkheden van gesprekstoepassingen, wat resulteert in meer natuurlijke en overtuigende reacties die gegenereerd kunnen worden in een breed scala aan complexe dialogen. De integratie van RLHF in deze modellen verbetert niet alleen hun vermogen om de context te begrijpen, maar stelt ze ook in staat om meer samenhangende en relevante reacties te geven, waardoor de gebruikerservaring wordt verbeterd.
De introductie van de innovatieve techniek die bekend staat als “gegroepeerde-vraag-aandacht” heeft het inferentieproces aanzienlijk versneld, waardoor de ontwikkeling van zeer functionele toepassingen zoals chatbots en virtuele assistenten mogelijk is geworden.
De huidige versie vertoont een superieur niveau van efficiëntie met betrekking tot zowel geheugengebruik als rekenkracht, vergeleken met de vorige iteratie.
Llama 2 is gelicenseerd onder een open-source en niet-commercieel raamwerk, waardoor onderzoekers en ontwikkelaars de functies vrij kunnen gebruiken en wijzigen zonder enige beperkingen of restricties opgelegd door commerciële belangen.
Llama 2 vertoont superieure prestaties op verschillende aspecten in vergelijking met de vorige versie, waardoor het een uitzonderlijk robuust instrument is voor tal van toepassingen, waaronder chatbotinteracties, virtuele helpers en het begrijpen van natuurlijke taal.
Een streamlit-omgeving opzetten voor chatbotontwikkeling
Om te beginnen met het bouwen van je applicatie, is het nodig om een ontwikkelomgeving op te zetten die dient om je huidige project te scheiden van eventuele reeds bestaande projecten die zijn opgeslagen op je apparaat.
Maak om te beginnen op de volgende manier een virtuele omgeving met behulp van de Pipenv-bibliotheek:
pipenv shell
Vervolgens gaan we verder met het installeren van de benodigde softwarecomponenten om de conversatie-agent te bouwen.
pipenv install streamlit replicate
Streamlit is een veelzijdig, open-source framework voor het ontwikkelen van webapplicaties, ontworpen om een snelle implementatie van machine learning en data science projecten te vergemakkelijken.
In essentie verwijst “Replicate” naar een cloud computing platform dat gebruikers toegang biedt tot een uitgebreide reeks open-source modellen voor machinaal leren die eenvoudig kunnen worden ingezet en gebruikt in verschillende toepassingen.
Krijg je Llama 2 API Token van Replicate
Om een Replicate token sleutel te krijgen, moet je eerst een account registreren op Replicate met behulp van je GitHub account.
Replicate staat alleen inloggen via een GitHub account toe .
Als je het dashboard opent, ga dan naar het tabblad “Verkennen” en zoek de zoekbalk. Voer ‘Llama 2 chat’ in het zoekveld in om het specifieke model met de naam ’llama-2-70b-chat’ te bekijken.
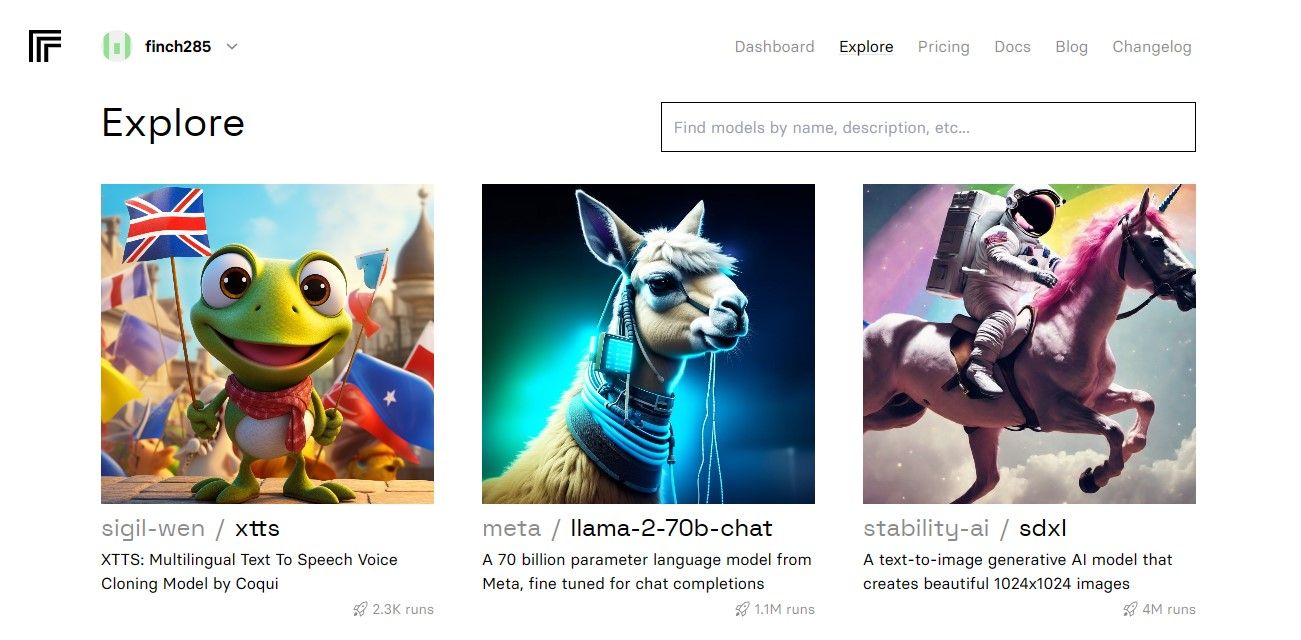
Selecteer de optie “Llama 2 API Endpoint” in het vervolgkeuzemenu en klik erop. Zodra je dit hebt gedaan, navigeer je naar de sectie met het label “API Token”. Hier vind je een knop met de naam “Python Application”. Door op deze knop te klikken, krijg je toegang tot de benodigde credentials voor het gebruik van de Llama 2 API in je Python projecten.
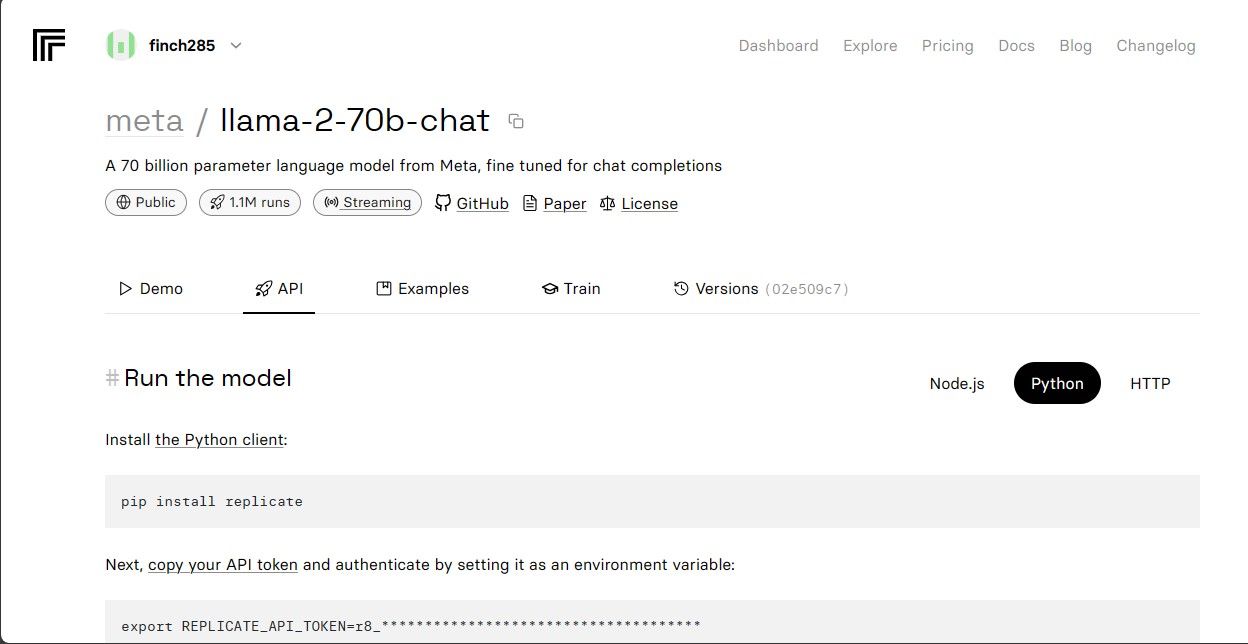
Kopieer het API token voor replicatiedoeleinden en zorg ervoor dat het veilig wordt opgeslagen voor toekomstig gebruik.
De volledige broncode is toegankelijk via onzeGitHub repository, die een uitgebreide bron biedt voor ontwikkelaars om te gebruiken en bij te dragen aan het project.
De chatbot bouwen
Om te beginnen met de ontwikkeling van de Llama Chatbot, genereer je in eerste instantie twee aparte bestanden - een met de naam “llama\_chatbot.py” die dient als het primaire script voor het implementeren van de functionaliteit van de chatbot, en een ander bestand met de naam “.env”, speciaal ontworpen voor het onderbrengen van gevoelige informatie zoals geheime sleutels en API-tokens die nodig zijn voor een goede werking. Door je aan deze beginopstelling te houden, kun je gevoelige gegevens effectief isoleren van de hoofdbroncode en tegelijkertijd een naadloze integratie met externe services garanderen.
Om verschillende functionaliteiten in het llama_chatbot.py script te kunnen gebruiken, is het nodig om verschillende bibliotheken te importeren. Het proces van het importeren van deze bibliotheken bestaat uit het specificeren van hun respectievelijke namen en ervoor zorgen dat ze op de juiste manier worden geïntegreerd met de bestaande codebase. Dit zorgt voor een naadloze werking en uitvoering van de beoogde functionaliteit van de chatbot.
import streamlit as st
import os
import replicate
Vervolgens stellen we de globale parameters voor het “llama-2-70b-chat” taalmodel in door de bijbehorende variabelen te initialiseren.
# Global variables
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default='')
# Define model endpoints as independent variables
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default='')
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default='')
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default='')
Om de Replicate API tokens en modelinformatie op te nemen in de omgevingsvariabelen van je applicatie, moet je de relevante details toevoegen aan het “.env” bestand met behulp van een specifieke opmaakstructuur. Dit zorgt voor een naadloze integratie van deze componenten in je project.
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Repliceer de meegeleverde token en zorg ervoor dat je het bijbehorende .env-bestand hebt opgeslagen.
De Gespreksstroom van de Chatbot ontwerpen
Het proces van het initiëren van het gebruik van het Llama 2-taalmodel voor specifieke taken kan worden vergemakkelijkt door het genereren van een inleidende prompt die het gewenste doel schetst. Als het bijvoorbeeld de bedoeling is om het model als assistent te gebruiken, dan zou het formuleren van een geschikte inleidende instructie inhouden dat deze intentie wordt gespecificeerd en mogelijk specifieke aandachtsgebieden of domeinkennis worden afgebakend die nodig zijn om de rol effectief te vervullen. Door vooraf duidelijke instructies te geven, zal de daaropvolgende interactie met de virtuele assistent met AI efficiënter en nauwkeuriger verlopen.
# Set Pre-propmt
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."
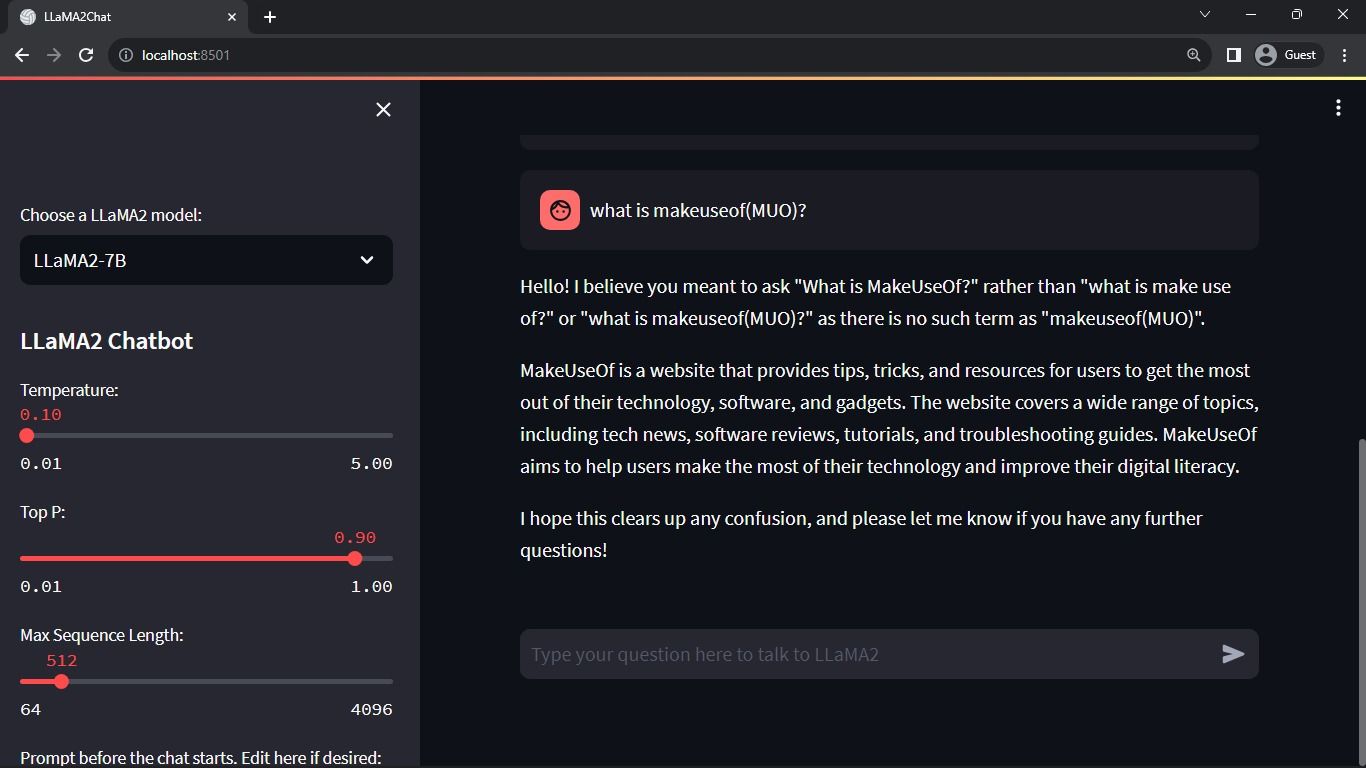
De pagina van een chatbot kan op verschillende manieren worden ingericht, afhankelijk van het gewenste uiterlijk en de gewenste functionaliteit. Enkele belangrijke overwegingen om in gedachten te houden zijn ontwerpelementen zoals kleurenschema’s, lettertypes en lay-outopties. Daarnaast is het belangrijk om te bepalen welke informatie of functies worden weergegeven op de pagina, inclusief eventuele interactieve onderdelen zoals knoppen of formulieren. De specifieke details van de indeling kunnen variëren op basis van individuele voorkeuren en vereisten, maar een duidelijk plan kan ervoor zorgen dat het eindresultaat voldoet aan de beoogde doelen en doelstellingen.
# Set initial page configuration
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Sessiespecifieke variabele configuraties initiëren en instellen door middel van de implementatie van een functionele procedure.
# Constants
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
# Session State Variables
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPT
def setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Het bovengenoemde proces configureert de cruciale parameters, zoals chat_dialogue , pre_prompt , llm , top_p , max_seq_len , en temperature binnen de status van de sessie. Daarnaast vergemakkelijkt het de selectie van het gewenste Llama 2 model volgens de voorkeur van de gebruiker.
Hier is een voorbeeld van hoe je een functie in Python kunt maken die de inhoud van de zijbalk rendert voor je Streamlit app:pythondef render_sidebar():# Code om HTML-code te genereren voor de zijbalk gaat hierereturn “Your sidebar content goes here”
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt \\+ "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
De bovengenoemde component toont de header en de configuratieparameters die kunnen worden aangepast om de prestaties van de Llama 2 chatbot te optimaliseren, waardoor noodzakelijke aanpassingen voor optimale functionaliteit mogelijk worden.
Hier is een mogelijke implementatie voor het renderen van de chatgeschiedenis in het hoofdinhoudsgebied van de Streamlit app met behulp van HTML en CSS:pythonimport streamlit as stfrom transformers import GPT2LMHeadModel, GPT2Tokenizerfrom streamlit_chat import message# Laadt verfijnd model en tokenizermodel = GPT2LMHeadModel.from_pretrained(‘meditations_model’)tokenizer = GPT2Tokenizer. from_pretrained(‘meditations_model’)#chatbotfunctie definiërendefchatbot(tekst):input_ids = tokenizer.encode(tekst, return_tensors=‘pt’)output = model. genereren(input_ids=input_ids, max_length=
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
De methode doorloopt het chat_dialogue object dat is opgeslagen in de sessiestatus, en toont elke communicatie die is uitgewisseld tussen de gebruiker en de assistent, vergezeld van de respectievelijke rolidentifier (ofwel “gebruiker” of “assistent”).
Het gegeven codefragment lijkt een placeholder te zijn voor een functie die gebruikersinvoer verwerkt, maar er wordt geen daadwerkelijke implementatie gegeven. Om gebruikersinvoer op een meer geavanceerde manier te verwerken, zou het nodig zijn om een geschikt algoritme of logica te definiëren en te implementeren binnen de functie op basis van de specifieke vereisten van je toepassing.
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
De presentational component biedt een tekstinvoerinterface voor gebruikers, waarmee ze berichten of vragen kunnen indienen binnen de context van de conversatie. Na ontvangst van de invoer van de gebruiker, voegt het bericht toe aan de lopende dialoog die is opgeslagen als onderdeel van de sessie-specifieke gegevens, die metadata bevatten die de rol van de deelnemer specificeren als “gebruiker” of “bot”.
Hier is een voorbeeld van hoe je deze functionaliteit zou kunnen implementeren met behulp van Python en de Hugging Face Transformers bibliotheek:pythonfrom transformers import LlamaTokenizer, LlamaForCausalLMimport torchdef generate_responses(input_text):# Laad de voorgetrainde Llama tokenizer en modeltokenizer = LlamaTokenizer.from_pretrained(‘facebook/llama-base’)model = LlamaForCausalLM. from_pretrained(‘facebook/llama-base’)#codeer de input tekst als input IDsinputs = tokenizer(input_text, return_tensors=‘pt’).input_ids# Genereer
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue \\+= f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue \\+ "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response \\+= item
message_placeholder.markdown(full_response \\+ "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Het systeem genereert een archief van eerdere communicatie, dat zowel menselijke als AI-input omvat, voordat het uitgestelde replicatieproces wordt aangeroepen. Dit zorgt voor een naadloze dialoogervaring doordat de interface dynamisch wordt bijgewerkt met het laatste antwoord van de AI.
De primaire taak van deze toepassing is het renderen van alle componenten binnen het Streamlit framework, dat dient als een uitgebreide interface voor gebruikers.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
De applicatie gebruikt een georganiseerde volgorde van operaties om de status quo van de sessie vast te stellen, het zijpaneel weer te geven, chats te chronometreren, gebruikersinputs te verwerken en helperantwoorden te produceren met behulp van alle eerder gedefinieerde functies.
Hier is een voorbeeld van hoe je je main() functie in index.js kunt wijzigen om de renderApp() functie te gebruiken en de applicatie te starten wanneer het script wordt uitgevoerd:javascriptasync functie main() {const app = createContext(null); // Maak de Provider-context aan met de beginwaarde null// Omwikkel de renderApp-functie met een try-catch blok voor foutafhandelingtry {renderApp(app, document.getElementById(‘root’));} catch (err) {console.error( Fout bij het uitvoeren van de root-component:${err. stack} );}}// Roep de main-functie aan om de toepassing uit te voerenmain();Deze code creëert een nieuwe instantie van de Provider-context door null
def main():
render_app()
if __name__ == "__main__":
main()
Je toepassing is nu voorbereid en uitgerust voor implementatie, zodat deze eenvoudig kan worden uitgevoerd.
API-verzoeken afhandelen
Om de gevraagde functionaliteit te implementeren, is het nodig om een nieuwe Python-module genaamd “utils.py” aan te maken in de hoofdmap van het project. Deze module zal een enkele functie bevatten die de gespecificeerde taak uitvoert. Hieronder staat een voorbeeld van hoe dit kan worden bereikt:pythondef some_function():# Functiecode moet hier…
import replicate
import time
# Initialize debounce variables
last_call_time = 0
debounce_interval = 2 # Set the debounce interval (in seconds)
def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)
current_time = time.time()
elapsed_time = current_time - last_call_time
if elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."
last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt \\+ "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
De functionaliteit bevat een debouncing mechanisme om het risico van te frequente en prodigale API verzoeken als gevolg van de interactie van een gebruiker te beperken, waardoor een verstandig gebruik van bronnen wordt gegarandeerd.
Integreer de debounced response functie in het llama_chatbot.py script door de volgende stappen uit te voeren:
from utils import debounce_replicate_run
Voer nu de applicatie uit:
streamlit run llama_chatbot.py
Verwachte uitvoer:
De interactie die in deze uitvoer wordt weergegeven is een dialoog tussen een AI-taalmodel en een menselijke gebruiker.
Toepassingen in de echte wereld van Streamlit en Llama 2 Chatbots
Verschillende voorbeelden van praktisch gebruik van Llama 2 software kunnen worden waargenomen in verschillende industrieën, zoals:
Chatbots zijn een veelzijdige tool die wordt gebruikt voor het ontwikkelen van interactieve agents die in staat zijn om real-time discussies te voeren over een scala aan onderwerpen, waarbij natuurlijke taalverwerking en kunstmatige intelligentie-algoritmen worden gebruikt om relevante antwoorden te geven op basis van de input van de gebruiker.
Deze tool, waarin technologie voor het begrijpen van natuurlijke taal is verwerkt, is ontworpen voor het ontwikkelen van conversatieagenten die menselijke communicatie kunnen begrijpen en beantwoorden op een manier die menselijke interactie nabootst.
Het gebruik van taalvertaaltechnologie is beperkt tot het vertalen van talen in verschillende linguïstische taken.
Het samenvatten van een tekst bestaat uit het comprimeren van een lang geschrift tot een kortere, beknoptere versie die de essentiële betekenis en kernpunten behoudt, terwijl overbodige details worden weggelaten. Dit proces kan nuttig zijn in verschillende contexten zoals journalistiek, onderzoekspapers of sociale media waar snelle toegang tot informatie cruciaal is. Door alleen de belangrijkste aspecten van een bepaald onderwerp weer te geven, stelt een samenvatting lezers in staat om efficiënt de belangrijkste ideeën te begrijpen zonder een heel document woord voor woord te hoeven doorlezen.
De toepassing van Llama 2 voor onderzoeksdoeleinden omvat het beantwoorden van vragen over een breed scala aan onderwerpen.
De toekomst van AI
De uitdaging van de hoge kosten die gepaard gaan met het gebruik van grote taalmodellen zoals die in GPT-3.5 en GPT-4 heeft de capaciteit van kleinere entiteiten beperkt om noemenswaardige toepassingen daarvan te bouwen, aangezien het verkrijgen van toegang tot de API voor deze modellen vaak een aanzienlijke kostenpost is.
De onthulling van krachtige linguïstische frameworks zoals Llama 2 aan de ontwikkelaars markeert het begin van een nieuw tijdperk in kunstmatige intelligentie. Deze gebeurtenis zal inventief en vindingrijk gebruik van deze systemen in praktische scenario’s stimuleren, waardoor de voortgang naar het bereiken van Kunstmatige Superintelligentie in een versneld tempo zal toenemen.