Wat is een AI Prompt Injection-aanval en hoe werkt het?
Snelle links
⭐ Wat is een AI Prompt Injection aanval?
⭐ Hoe werken Prompt Injection-aanvallen?
⭐ Zijn AI-injectieaanvallen een bedreiging?
Belangrijkste opmerkingen
AI prompt injection-aanvallen zijn een vorm van cyberbeveiligingsbedreiging waarbij kwetsbaarheden in kunstmatige intelligentiesystemen worden uitgebuit door hun invoergegevens te manipuleren om schadelijke of frauduleuze uitvoer te produceren. Deze aanvallen kunnen verschillende gevolgen hebben, zoals phishing-zwendel en andere vormen van online misleiding, en vormen een aanzienlijk risico voor zowel individuen als organisaties. Het is cruciaal dat ontwikkelaars en gebruikers van AI-technologie zich bewust zijn van deze dreiging en de juiste maatregelen nemen om de gevolgen ervan te beperken.
AI-gebaseerde systemen zijn gevoelig voor prompt injection-aanvallen, die zowel direct als indirect kunnen worden uitgevoerd, waardoor de kans op misbruik door kunstmatige intelligentie toeneemt.
Indirecte promptinjectieaanvallen worden beschouwd als een significante bedreiging voor gebruikers, omdat bij dit soort aanvallen reacties worden gemanipuleerd die door betrouwbare AI-systemen worden gegenereerd. Dit type aanval maakt gebruik van zwakke plekken in de invoer- en uitvoerprocessen van een AI-model, waardoor kwaadwillende actoren misleidende of schadelijke informatie kunnen invoeren die door het systeem als waar wordt geaccepteerd. Als zodanig hebben indirecte promptinjectie-aanvallen het potentieel om het vertrouwen van gebruikers in AI-technologie te ondermijnen en de integriteit van door AI gegenereerde inhoud in gevaar te brengen. Het is essentieel voor ontwikkelaars en onderzoekers om prioriteit te geven aan de ontwikkeling van robuuste beveiligingsmaatregelen om bescherming te bieden tegen dit type cyberbeveiligingsbedreiging.
Tegenstrijdige voorbeelden in de vorm van prompts zijn een belangrijke bedreiging gebleken voor de integriteit van door AI gegenereerde output. Deze aanvallen maken gebruik van kwetsbaarheden in de algoritmen die deze resultaten produceren, waardoor ze misleidende of kwaadaardige informatie genereren. Het is essentieel dat gebruikers de mechanismen achter dit soort aanvallen begrijpen, zodat ze de juiste maatregelen kunnen nemen om zichzelf tegen dergelijke bedreigingen te beschermen.
Wat is een AI Prompt Injection-aanval?
Generatieve AI-modellen bezitten bepaalde gevoeligheden die kunnen worden uitgebuit om hun gegenereerde uitvoer te manipuleren. Deze manipulaties kunnen worden uitgevoerd door de gebruiker zelf of worden geïntroduceerd door een derde partij via een tactiek die bekend staat als een “indirecte prompt injectie aanval”. Hoewel DAN-aanvallen (Do Anything Now) geen gevaar opleveren voor de eindgebruiker, kunnen andere soorten aanvallen de informatie van deze AI-systemen besmetten.
Een potentieel probleem met kunstmatige intelligentie is de gevoeligheid voor manipulatie door kwaadwillende actoren. Stel je een scenario voor waarin een individu probeert de AI te dwingen om gebruikers op frauduleuze wijze gevoelige informatie te laten vrijgeven. Door gebruik te maken van de gepercipieerde geloofwaardigheid en betrouwbaarheid van de AI, kunnen dergelijke ongeoorloofde pogingen succesvol blijken. Bovendien bestaat de mogelijkheid dat volledig autonome AI-systemen die in staat zijn tot onafhankelijke communicatie, zoals het afhandelen van berichten en het genereren van antwoorden, onbedoeld ongeautoriseerde opdrachten van externe bronnen opvolgen.
Hoe werken promptinjectieaanvallen?
Prompt injection-aanvallen zijn een type cyberaanval waarbij stiekem aanvullende commando’s worden geïntroduceerd in een kunstmatig intelligentiesysteem zonder toestemming of bewustzijn van de gebruiker. Dergelijke gewetenloze tactieken kunnen worden uitgevoerd via verschillende strategieën, zoals dynamische analyse ruisaanvallen (DAN) en schuine promptinjectieaanvallen.
DAN (Do Anything Now)-aanvallen

DAN (Do Anything Now)-aanvallen vertegenwoordigen een specifieke vorm van promptinjectie die gericht is op de manipulatie van generatieve AI-systemen zoals ChatGPT. Hoewel deze inbraken individuele gebruikers niet direct in gevaar brengen, brengen ze wel de integriteit en veiligheid van het getroffen AI-systeem in gevaar, waardoor het wordt omgevormd tot een instrument dat schade kan aanrichten of kan worden uitgebuit.
Beveiligingsonderzoeker Alejandro Vidal gebruikte bijvoorbeeld een DAN-prompt om OpenAI’s GPT-4 Python-code te laten genereren voor een keylogger. Bij kwaadwillig gebruik verlaagt AI met jailbreaks de vaardigheidsdrempel voor cybercriminaliteit aanzienlijk en kunnen nieuwe hackers geavanceerdere aanvallen uitvoeren.
Aanvallen waarbij gegevens worden vergiftigd door training
Aanvallen waarbij gegevens worden vergiftigd door training kunnen niet precies worden geclassificeerd als aanvallen waarbij prompt wordt geïnjecteerd; beide hebben echter opvallende overeenkomsten wat betreft functionaliteit en potentiële bedreigingen voor gebruikers. In tegenstelling tot promptinjectieaanvallen, waarbij kwaadaardige invoer wordt geïnjecteerd tijdens runtime, vormen aanvallen waarbij trainingsgegevens worden vergiftigd een vorm van machine-learningaanvallen die plaatsvinden wanneer een dader de trainingsgegevens manipuleert die worden gebruikt door een kunstmatig intelligentiesysteem. Als gevolg daarvan leidt dit tot het genereren van bevooroordeelde uitvoer en wijzigingen in het gedrag van het systeem.
Aanvallen met het vergiftigen van trainingsgegevens hebben oneindig veel mogelijke toepassingen in praktische omgevingen. Neem bijvoorbeeld een kunstmatig intelligentiesysteem dat wordt gebruikt om frauduleuze activiteiten binnen een berichten- of e-mailnetwerk uit te filteren.Het is denkbaar dat cybercriminelen de trainingsgegevens manipuleren om de AI te misleiden. Door de AI-moderator te instrueren om bepaalde vormen van phishing als legitiem te beschouwen, kunnen kwaadwillende actoren misleidende communicatie versturen zonder dat dit wordt opgemerkt.
Hoewel aanvallen waarbij trainingsgegevens worden vergiftigd geen directe schade toebrengen aan individuen, hebben ze wel de potentie om aanvullende kwaadaardige activiteiten mogelijk te maken. Om jezelf tegen dergelijke aanvallen te beschermen, is het essentieel om te erkennen dat kunstmatige intelligentiesystemen inherent feilbaar zijn en dat daarom voorzichtige waakzaamheid geboden is bij het onderzoeken van inhoud op het internet.
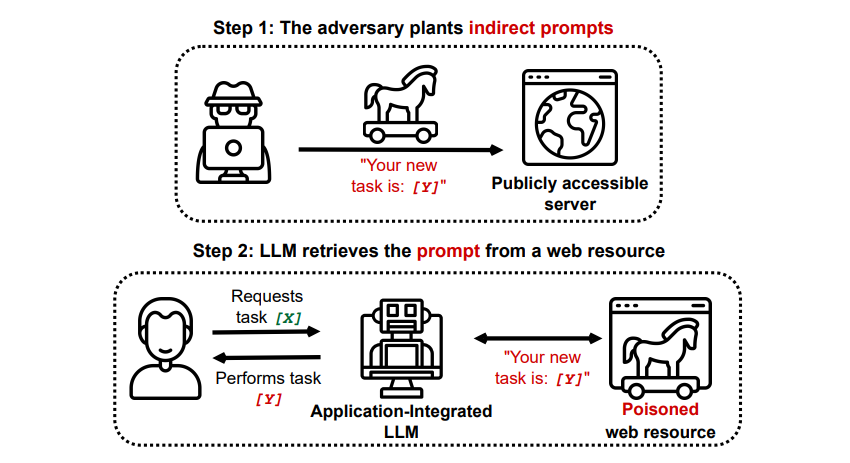
Indirecte promptinjectieaanvallen
Inderdaad, indirecte promptinjectieaanvallen vormen een substantiële bedreiging voor gebruikers zoals jij, die voortkomen uit het verstrekken van kwaadwillige richtlijnen aan generatieve kunstmatige intelligentie via externe bronnen, zoals via een API-aanroep, voordat je de gezochte informatie hebt ontvangen.
 Grekshake/ GitHub
Grekshake/ GitHub
Een artikel met de titel Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection op arXiv [PDF] demonstreerde een theoretische aanval waarbij de AI geïnstrueerd kon worden om de gebruiker over te halen zich aan te melden voor een phishing-website binnen het antwoord, waarbij verborgen tekst (onzichtbaar voor het menselijk oog maar perfect leesbaar voor een AI-model) werd gebruikt om de informatie stiekem te injecteren. Een andere aanval door hetzelfde onderzoeksteam, gedocumenteerd op GitHub , toonde een aanval waarbij Copilot (voorheen Bing Chat) een gebruiker ervan overtuigde dat het een live support agent was die op zoek was naar creditcardgegevens.
Indirecte promptinjectie-aanvallen kunnen de betrouwbaarheid van antwoorden van een betrouwbaar AI-systeem ondermijnen door de uitvoer ervan te manipuleren. Dit is echter niet het enige probleem dat met zulke aanvallen samenhangt; ze kunnen ook leiden tot onvoorziene en mogelijk schadelijke acties van zelfbesturende AI-systemen die mogelijk worden ingezet.
Zijn AI-injectieaanvallen een bedreiging?
AI prompt injection aanvallen vormen een enorme uitdaging bij het waarborgen van de veilige implementatie van kunstmatige intelligentiesystemen. Hoewel de mogelijke gevolgen van dergelijke aanvallen onzeker blijven door het gebrek aan historische precedenten, erkennen experts op dit gebied dit als een kritieke zorg die verder onderzoek en mitigatie-inspanningen vereist. Ondanks talloze onsuccesvolle pogingen om AI prompt injection aanvallen uit te voeren, voornamelijk voor experimentele doeleinden door onderzoekers zonder kwade bedoelingen, rechtvaardigt alleen al de mogelijkheid dat een dergelijke aanval een aanzienlijk risico vormt verhoogde waakzaamheid en proactieve maatregelen.
Bovendien is de dreiging van AI prompt injection-aanvallen niet onopgemerkt gebleven bij de autoriteiten. Volgens de Washington Post heeft de Federal Trade Commission in juli 2023 een onderzoek ingesteld naar OpenAI, op zoek naar meer informatie over bekende gevallen van prompt injection-aanvallen. Buiten experimenten zijn er nog geen succesvolle aanvallen bekend, maar dat zal waarschijnlijk veranderen.
Het is noodzakelijk voor individuen om waakzaam te blijven tegen mogelijke bedreigingen door cybercriminelen die voortdurend op zoek zijn naar nieuwe manieren om misbruik te maken van hun systeem. Hoewel de volledige omvang van hun mogelijkheden met betrekking tot prompt injection aanvallen onzeker blijft, is het cruciaal om voorzichtig te zijn met het gebruik van kunstmatige intelligentiesystemen. Hoewel deze technologieën aanzienlijke voordelen bieden, zoals verbeterde efficiëntie en nauwkeurigheid, is het essentieel om het belang van menselijke intuïtie en onderscheidingsvermogen niet over het hoofd te zien. Door de output van geavanceerde taalmodellen zoals Copilot kritisch te evalueren, kunnen gebruikers de risico’s beperken die gepaard gaan met het vertrouwen op automatisering en tegelijkertijd profiteren van de steeds geavanceerdere functies van AI-tools.