Documenten analyseren met LangChain en de OpenAI API
Inzichten halen uit documenten en gegevens is cruciaal voor het nemen van weloverwogen beslissingen. Er zijn echter zorgen over privacy als het gaat om gevoelige informatie. Met LangChain, in combinatie met de OpenAI API, kunt u uw lokale documenten analyseren zonder dat u ze online hoeft te uploaden.
Door de lokale opslag van gegevens, het gebruik van embeddings en vectorisaties voor onderzoek en het uitvoeren van bewerkingen binnen het eigen systeem, behoudt OpenAI effectief de privacy. Belangrijk is dat informatie die door klanten via hun API wordt verzonden, niet wordt gebruikt voor modeltraining of serviceverbetering.
Uw omgeving instellen
Om een nieuwe virtuele Python-omgeving te maken en de benodigde bibliotheken te installeren, volgt u deze stappen:Maak eerst een nieuwe Python-omgeving door gebruik te maken van de venv module die wordt geleverd bij Python 3.x. Dit voorkomt compatibiliteitsproblemen tussen verschillende versies van geïnstalleerde pakketten. Open hiervoor uw terminal of opdrachtprompt en navigeer naar de gewenste map waar u de virtuele omgeving wilt aanmaken. Voer daar het volgende commando in:bashpython -m venv myenvVervang “myenv” met de naam die je verkiest voor je virtuele omgeving. Activeer vervolgens de nieuw aangemaakte omgeving met de opdracht ./bin/activate (op Windows) of source bin/activate (op macOS of Linux). Ga na de activering verder met het installeren van de vereiste bibliotheken door de opdracht
pip install langchain openai tiktoken faiss-cpu pypdf
uit te voeren Het gebruik van elke bibliotheek kan als volgt worden samengevat:
LangChain is een veelzijdige tool die is ontworpen om het maken en beheren van linguïstische ketens voor verschillende tekstverwerkings- en analysetaken te vergemakkelijken. Het platform biedt een scala aan functionaliteiten zoals het laden van documenten, tekstsegmentatie, het genereren van insluitingen en vectoropslag, allemaal gericht op het stroomlijnen van uw taalgerelateerde activiteiten met gemak en efficiëntie.
Het gewaardeerde platform van OpenAI biedt gebruikers de mogelijkheid om vragen uit te voeren en antwoorden op te halen uit geavanceerde linguïstische modellen, wat een waardevolle bron is voor diegenen die op zoek zijn naar inzichtelijke analyse of assistentie.
Het TikTokoken dient als hulpmiddel voor het kwantificeren van het aantal tekens in een gespecificeerde hoeveelheid tekst, waardoor het tokengebruik nauwkeurig kan worden bijgehouden tijdens interacties met de Open AI API, waar de kosten worden bepaald door de hoeveelheid gebruikte tekst.
FAISS is een efficiënt hulpprogramma waarmee je een opslagplaats van vectorvoorstellingen kunt aanleggen en onderhouden, zodat je snel toegang hebt tot gelijk gecodeerde vectoren via hun inbeddingen.
PyPDF2 is een Python-pakket waarmee tekst uit PDF-bestanden (Portable Document Format) kan worden geëxtraheerd. De software stroomlijnt het proces van het laden van PDF-documenten en maakt het mogelijk om de inhoud ervan op te halen voor latere manipulatie of analyse.
Nadat de installatie van alle bibliotheken is voltooid, is je werkruimte nu voorbereid en voorzien van de nodige tools om aan de slag te gaan.
Een OpenAI API Key verkrijgen
Om gebruik te kunnen maken van de diensten die door de OpenAI API worden geleverd, is het verplicht om een API key op te nemen in je aanvraag. Hierdoor kan de API provider de authenticiteit van de verzoekende partij bevestigen en tevens verifiëren of de verzender over de vereiste autorisatie beschikt om toegang te krijgen tot de beschikbare functionaliteiten.
Om een OpenAI API key te verkrijgen, ga naar het OpenAI platform .
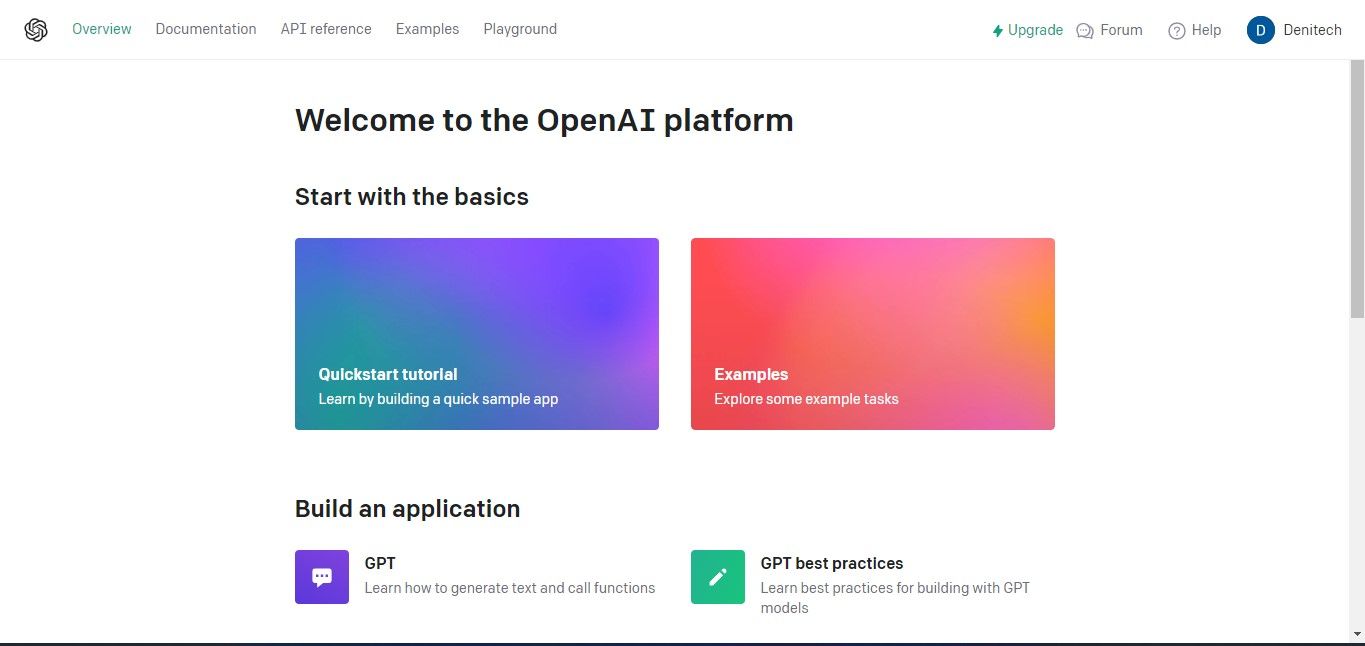
Om toegang te krijgen tot de API-sleutels gaat u naar het gedeelte Profiel rechtsboven op het dashboard van uw account en selecteert u ‘API-sleutels weergeven’. Deze actie zal onmiddellijk de pagina met API-sleutels weergeven voor verder beheer.
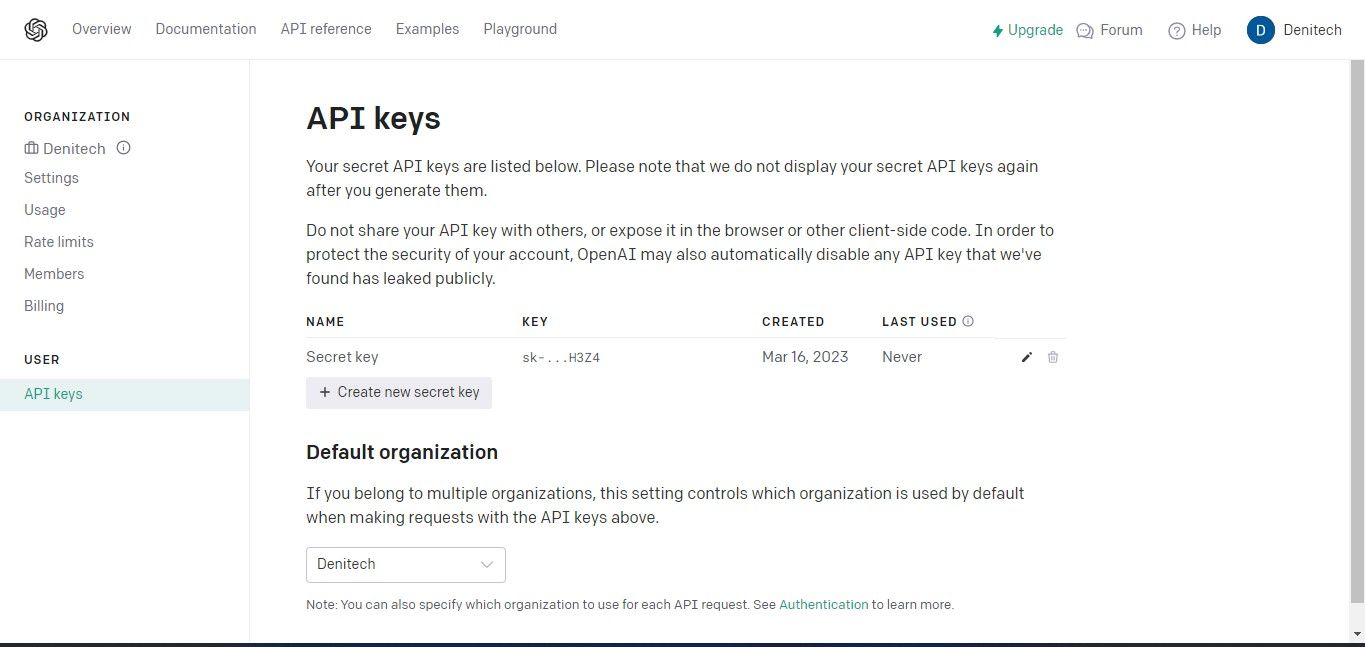
Klik alstublieft op de “Create New Secret Key” knop om het proces van het genereren van een API sleutel voor uw gebruik met OpenAI te starten. Geef na het genereren een naam op voor uw sleutel en klik vervolgens op de optie “Create New Secret Key” om het aanmaken van uw sleutel te voltooien. Het is belangrijk dat u de gegenereerde API-sleutel veilig bewaart, omdat toegang tot de sleutel mogelijk niet beschikbaar is via uw OpenAI account vanwege veiligheidsoverwegingen. In het geval dat u de geheime sleutel kwijtraakt of verliest, moet u een nieuwe in de plaats maken.
De volledige broncode is toegankelijk via een GitHub repository, die gebruikers de mogelijkheid biedt om de inhoud van het project te verkennen en te gebruiken.
Importeren van de benodigde bibliotheken
Om een gebruiker de pakketten te laten gebruiken die geïnstalleerd zijn in zijn virtuele omgeving, is het nodig om ze te importeren.
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
Bij bestudering van de code wordt duidelijk dat het proces bestaat uit het importeren van noodzakelijke afhankelijkheden binnen het LangChain framework, waardoor toegang wordt verkregen tot een uitgebreide reeks functionaliteiten die door dit framework worden aangeboden.
Het document laden voor analyse
Maak om te beginnen een variabele aan die dient als opslagplaats voor uw API-sleutel. Deze entiteit zal later in het script worden gebruikt voor validatiedoeleinden.
# Hardcoded API key
openai_api_key = "Your API key"
Bij het distribueren van code op productieniveau die gedeeld kan worden met externe entiteiten, is het raadzaam om gevoelige informatie zoals API-sleutels niet direct in de broncode op te nemen. In plaats van deze aanpak te implementeren, biedt het gebruik van een omgevingsvariabele een veiligere en praktischere oplossing voor het beheren van zulke referenties in een gedeelde context.
Natuurlijk! Hier is een voorbeeld van hoe je dit zou kunnen implementeren in Python met behulp van de PyPDF2 bibliotheek voor het werken met PDF-bestanden en de ingebouwde open() functie om platte tekstbestanden te lezen:pythonimport PyPDF2from io import BytesIOdef load_document(file_path):“““Laadt een document van het opgegeven bestandspad.”# Controleer of het bestand bestaat voordat je het probeert te openenpoging:if not file_path.endswith(’.pdf’):# Document is geen PDF-bestand, dus probeer het te openen als een tekstbestandmet open(file_path, ‘r’) als f:return f.read()elif file_path.endswith(’.pdf’):
def load_document(filename):
if filename.endswith(".pdf"):
loader = PyPDFLoader(filename)
documents = loader.load()
elif filename.endswith(".txt"):
loader = TextLoader(filename)
documents = loader.load()
else:
raise ValueError("Invalid file type")
Nadat de documenten zijn geladen, wordt een instantie van CharacterTextSplitter gemaakt. Deze splitter is verantwoordelijk voor het verdelen van de geladen documentatie in beter hanteerbare porties, waarbij elke verdeling wordt bepaald door afzonderlijke tekens.
text_splitter = CharacterTextSplitter(chunk_size=1000,
chunk_overlap=30, separator="\n")
return text_splitter.split_documents(documents=documents)
Het verwerken van de inhoud in kleinere, samenhangende segmenten vergemakkelijkt efficiënte verwerking en behoudt een zekere mate van relevante contextuele overlap, wat gunstig is bij ondernemingen zoals tekstanalyse en het ophalen van gegevens.
Het document opvragen
Om informatie uit het ingediende document te halen, ontwikkel je een functie die een zoekterm samen met een gegevensopvraagcomponent als invoer accepteert. Deze functie gebruikt de meegeleverde retriever in combinatie met een instantiatie van het Open AI natuurlijke taalmodel om een RetrievalQA object te maken.
def query_pdf(query, retriever):
qa = RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),
chain_type="stuff", retriever=retriever)
result = qa.run(query)
print(result)
Deze functie gebruikt het geïnstantieerde vraag-antwoordmodel om de vraag uit te voeren en het resultaat weer te geven.
De hoofdfunctie maken
De hoofdfunctie regelt het algemene verloop van het programma door invoer van de gebruiker voor een bestandsnaam van een document te accepteren en vervolgens het gespecificeerde document te laden. Vervolgens maakt het een instantie van OpenAIEmbeddings aan, ontworpen voor woordinbeddingen en bouwt het een vectoropslag op basis van het eerder verwerkte document en de bijbehorende woordinbeddingen. Uiteindelijk wordt de opgebouwde vectordatabase opgeslagen op een lokaal opslagmedium in de vorm van een bestand.
Nadat de persistentielaag is geïnitialiseerd en alle benodigde gegevens zijn geladen, gaat het systeem over in een iteratieve fase waarin gebruikers worden gevraagd om zoekopdrachten in te dienen via een tekstinterface. Tijdens dit proces wordt de primaire functionaliteit gedelegeerd aan de methode query_pdf , die wordt aangeroepen naast de verantwoordelijke vectorrepository retriever die tijdens de initialisatie is verkregen. Deze cyclus gaat oneindig door totdat de gebruiker besluit de sessie te beëindigen door het woord “exit” in te voeren.
def main():
filename = input("Enter the name of the document (.pdf or .txt):\n")
docs = load_document(filename)
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectorstore = FAISS.from_documents(docs, embeddings)
vectorstore.save_local("faiss_index_constitution")
persisted_vectorstore = FAISS.load_local("faiss_index_constitution", embeddings)
query = input("Type in your query (type 'exit' to quit):\n")
while query != "exit":
query_pdf(query, persisted_vectorstore.as_retriever())
query = input("Type in your query (type 'exit' to quit):\n")
Embeddings kapselen de ingewikkelde interconnecties in die bestaan tussen lexicale items, en dienen als een abstracte weergave van geschreven of gesproken taal in een numeriek formaat. Met andere woorden, vectoren bieden een methode om tekstpassages weer te geven door middel van een reeks numerieke waarden, waardoor linguïstische gegevens computationeel verwerkt en geanalyseerd kunnen worden.
De huidige code transformeert de tekstuele inhoud van het document in vectorvoorstellingen met behulp van de embeddings geproduceerd door OpenAIEmbeddings en indexeert vervolgens deze vectorvoorstellingen met FAISS (Facebook AI Similarity Search) om snel ophalen en vergelijken van vergelijkbare vectorpatronen mogelijk te maken. Dit maakt het onderzoek van het ingediende document mogelijk.
Het opnemen van het __name__ attribuut met de bijbehorende waarde van "__main__" is een essentiële stap in het uitvoeren van de hoofdfunctie wanneer het script wordt uitgevoerd als een zelfstandig programma. Door deze constructie te gebruiken, kan de hoofdfunctie naadloos worden uitgevoerd na interactie met de gebruiker, zonder dat externe prompts of interventie nodig zijn.
if __name__ == "__main__":
main()
Dit softwareprogramma werkt als een terminalgebaseerde tool. Als uitbreiding kan Streamlit worden gebruikt om een grafische gebruikersinterface voor de toepassing via het internet op te nemen.
Documentanalyse uitvoeren
Om een documentanalyse uit te voeren, plaatst u het document dat u wilt onderzoeken in de map van uw project en start u vervolgens de softwaretoepassing. Het systeem vraagt u het specifieke document dat u wilt analyseren te identificeren door de volledige naam in te voeren. Geef vervolgens een reeks zoektermen op die het programma moet verwerken tijdens de onderzoeksprocedure.
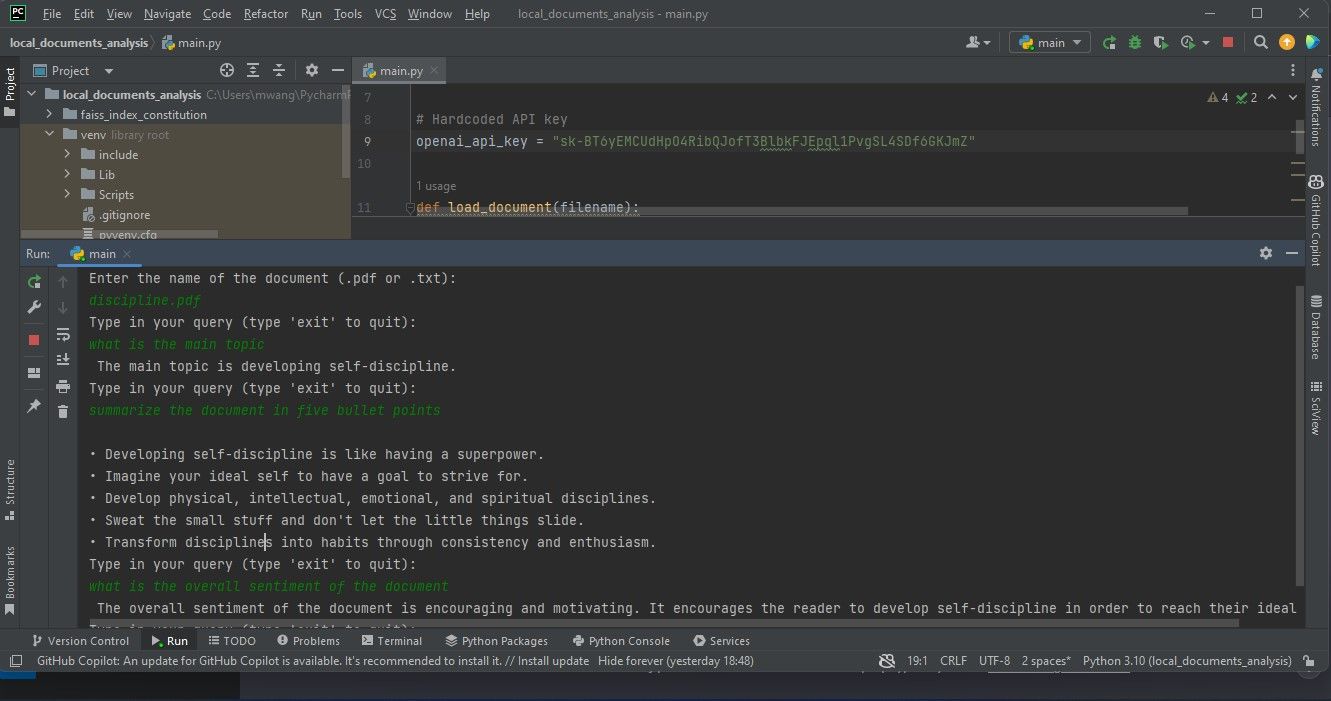
De grafische weergave in dit document toont de bevindingen van het verwerken van een Portable Document Format (PDF)-bestand, zoals geïllustreerd in de schermafbeelding onder deze verklaring.
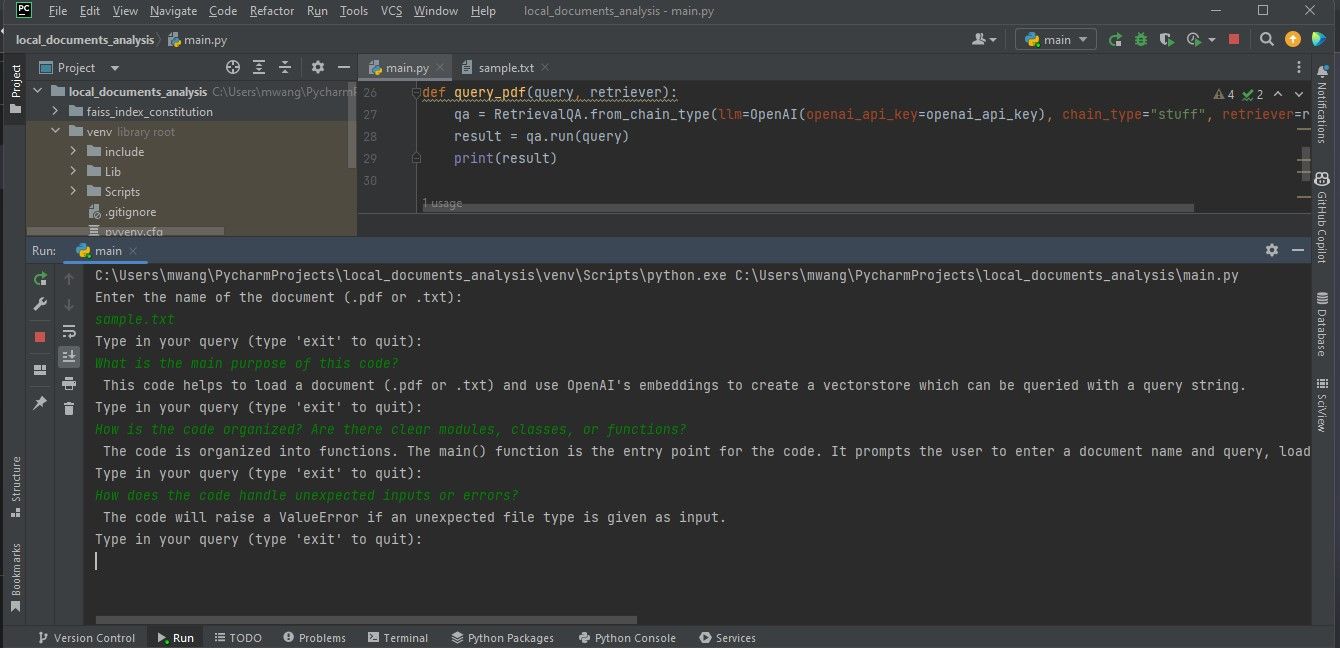
De volgende weergave toont de bevindingen van een onderzoek van een document met programmeercode.
Voor een nauwkeurige analyse van de gewenste bestanden is het essentieel dat ze in PDF- of tekstformaat zijn. Mochten de documenten een ander bestandstype hebben, dan zijn er verschillende online hulpmiddelen beschikbaar om deze bestanden te converteren naar een geschikt PDF-formaat voor grondig onderzoek en interpretatie.
Inzicht in de technologie achter grote taalmodellen
LangChain stroomlijnt het ontwikkelingsproces voor toepassingen die gebruik maken van geavanceerde natuurlijke taalcapaciteiten door te abstraheren van complexe technische details, zodat gebruikers zich kunnen richten op de beoogde functionaliteit zonder zich te verdiepen in de fijne kneepjes van AI-gedreven taalmodellering. Het is belangrijk om een goed begrip te hebben van de onderliggende technologieën die deze modellen mogelijk maken om de werking van de specifieke toepassing die wordt ontwikkeld volledig te begrijpen.