AI komt voor uw sociale-mediagegevens: Kun je er iets aan doen?
Belangrijkste resultaten
Terwijl er een groeiende bezorgdheid is over de privacy van gebruikersinformatie op sociale mediaplatforms, zijn er berichten dat sommige van deze platforms toegang tot gebruikersgegevens hebben verkocht aan kunstmatige intelligentie (AI)-bedrijven om hun generatieve AI-modellen te trainen. Dit roept vragen op over de ethische implicaties en mogelijke gevolgen van dergelijke acties.
Van de eerder genoemde platforms, zoals Meta, Reddit, Tumblr en WordPress.com, is bekend dat ze deelnemen aan overeenkomsten waarbij ze gegevens in licentie geven voor het trainen van kunstmatige intelligentie.
Gebruikers kunnen een aantal bescheiden maatregelen nemen om hun informatie te beschermen door hun privacyvoorkeuren aan te passen, door te weigeren gegevens te delen en door voorzichtig te zijn met het plaatsen van inhoud op internet.
In de afgelopen tijd hebben social media-bedrijven nieuwe methoden onderzocht om munt te slaan uit gebruikersinformatie door overeenkomsten te sluiten met kunstmatige intelligentiebedrijven. Dit roept echter de vraag op welke maatregelen gewone individuen kunnen nemen om hun persoonlijke gegevens en digitale creaties te beschermen tegen misbruik in dergelijke transacties.
Sociale mediaplatforms sluiten overeenkomsten met AI-bedrijven
Het gebruik van sociale media-informatie voor het trainen van modellen voor kunstmatige intelligentie heeft tot veel discussie geleid, maar het lijkt erop dat sociale mediabedrijven niet bereid zijn om gebruikersgegevens af te staan.
Meta heeft sociale-mediagegevens geïntegreerd in zijn generatieve AI-functies, die werden geïntroduceerd tijdens het Meta Connect-evenement. Deze functies omvatten Meta AI en mogelijkheden zoals het genereren van AI-gestuurde emoji’s voor platforms als WhatsApp.
Zoals Mike Clark, Director of Product Management bij Meta, verklaarde in een Meta Newsroom-post :
De kunstmatige intelligentie-modellen die worden gebruikt in de functies die werden getoond tijdens ons recente evenement, bekend als Connect, werden getraind met behulp van openbaar beschikbare inhoud van zowel Instagram als Facebook, inclusief afbeeldingen en bijbehorende onderschriften.
Deze trend lijkt niet te vertragen in Volgens Reuters heeft Reddit een deal gesloten met Google om de content van het sociale mediaplatform beschikbaar te maken voor het trainen van AI-modellen.
Reddit’s S-1 filing voor zijn IPO, ingediend op 22 februari 2024, bevestigt dat het bedrijf licentieovereenkomsten onderzoekt. In het dossier staat:
Het gebruik van Reddit-gegevens is essentieel gebleken voor de ontwikkeling van hedendaagse kunstmatige intelligentietechnologieën, waaronder grote taalmodellen (LLM’s).Daarom verwachten we dat Reddit’s uitgebreide opslagplaats van conversatie-informatie en expertise instrumenteel zal blijven in het verfijnen en verbeteren van de mogelijkheden van deze geavanceerde linguïstische systemen.
Reddit heeft een programma opgestart waarmee externe entiteiten toestemming kunnen krijgen voor het openen, onderzoeken en presenteren van zowel vroegere als huidige gegevens van zijn platform, met als doel deze informatie te gebruiken om grote taalmodellen (LLM’s) te verbeteren.
En hoewel Meta en Reddit enkele van de grootste namen in sociale media zijn, zijn ze niet de enige platforms die betrokken zijn bij het gebruik van sociale mediagegevens om AI te trainen. Volgens een rapport van 404 Media bereiden Tumblr en WordPress.com zich voor om gebruikersgegevens te verkopen aan Midjourney en OpenAI.
Kun je platforms stoppen met het verkopen van je sociale-mediagegevens voor AI-training?
Het gebruik van platforms zoals Facebook, Instagram, Reddit, Tumblr en WordPress.com kan ertoe leiden dat iemands openbaar toegankelijke inhoud wordt opgenomen in het ontwikkelingsproces van Language Model Learners (LLM’s).
Als je bijvoorbeeld de Washington Post zoekfunctie gebruikt om te zien welke sites werden opgenomen in Google’s C4 dataset, die werd gebruikt als onderdeel van Bard’s training, zie je dat Reddit.com goed is voor 7,9 miljoen tokens.
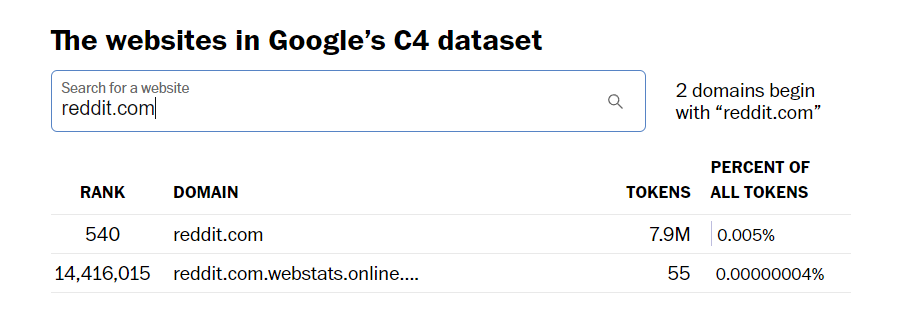
De dataset omvat een aanzienlijk aantal inhoudsbronnen, waaronder Tumblr.com met een aanzienlijke vertegenwoordiging van ongeveer 1,6 miljoen tokens, maar ook kleinere websites zoals mijn eigen WordPress.com, die een minimale bijdrage leveren van slechts ongeveer 14.000 tokens. Het is de moeite waard om op te merken dat zelfs deze bescheiden persoonlijke blogs zijn opgenomen in de dataset.
De opkomende overeenkomsten tussen kunstmatige intelligentiebedrijven en entiteiten van sociale netwerken hebben betrekking op de actieve marketing van dergelijke gegevens, in tegenstelling tot de passieve extractie uit online bronnen.
Maar wat kun je doen aan toekomstige verwerking? Meta heeft een formulier geïntroduceerd voor generatieve AI data subject rights waarmee je bezwaar kunt maken tegen of beperkingen kunt opleggen aan de verwerking van je persoonlijke gegevens van derden voor het trainen van Meta’s generatieve AI modellen.
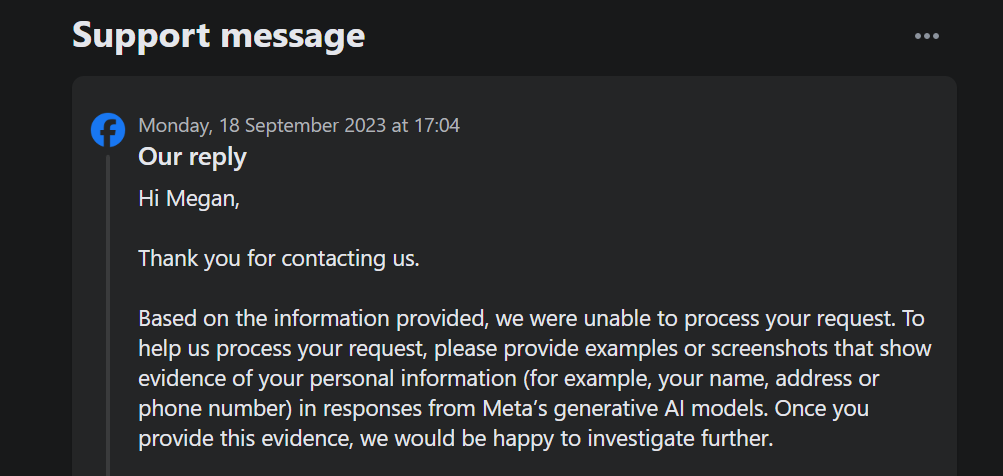
Het is vermeldenswaard dat deze optie het niet mogelijk maakt om bezwaar te maken tegen Meta’s verwerking van gebruikersgegevens voor het trainen van kunstmatige intelligentiesystemen. Toen we probeerden bezwaar aan te tekenen via het meegeleverde formulier, ontdekten we dat er als onderdeel van het supportticketproces bewijs nodig was dat iemands persoonlijke gegevens werden gebruikt voor Meta’s AI-outputs.
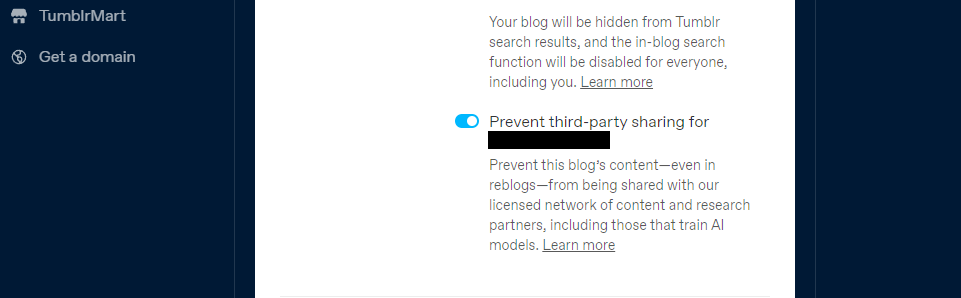
Tumblr biedt een oplossing waarmee gebruikers de verspreiding van hun openbare blogberichten naar externe entiteiten kunnen weigeren via de configuratie van hun account. Om toegang te krijgen tot deze functie gaat u naar uw profielpagina en scrollt u naar beneden totdat u de opties ‘Zichtbaarheid’ vindt. Selecteer daar het alternatief dat ongeoorloofd delen van uw blog met derden voorkomt.
Als u platforms zoals Instagram gebruikt, is het een mogelijke strategie om de privacy-instellingen van uw account aan te passen om de toegankelijkheid te beperken. Hoewel deze maatregel geen absolute garantie biedt dat je informatie niet zal worden misbruikt, kan het overschakelen naar een privéaccount een formidabel afschrikmiddel zijn, gezien de wijdverspreide verzamelpraktijken van gegevens die gericht zijn op openbaar beschikbare inhoud.
Je hebt ook de optie om je Twitter-account privé te maken. Het is echter belangrijk op te merken dat deze maatregel geen absolute garantie biedt voor de privacybescherming van je gegevens.
Een gezamenlijke verklaring van verschillende nationale informatiecommissarissen en experts van over de hele wereld heeft ook een aantal acties voorgesteld voor individuen die het privacyrisico van dataschrapen door AI-bedrijven willen minimaliseren. Het advies omvat:
Bekijk de algemene voorwaarden en het privacybeleid van deze website om de praktijken met betrekking tot het delen van persoonsgegevens te begrijpen.
Bij het delen van persoonlijke informatie op internet is het belangrijk om voorzichtig en terughoudend te zijn, vooral bij het vrijgeven van gevoelige gegevens.
⭐Beheer uw privacy-instellingen.
Bij het bepalen van de inhoud die men op het internet wil delen, is het belangrijk om een langetermijnperspectief te behouden en zorgvuldig na te denken over de mogelijke implicaties van dergelijke openbaarmakingen in zowel de nabije als de verre toekomst.
Als je vermoedt dat je persoonlijke gegevens zonder de juiste toestemming van een sociaal netwerkplatform of -site zijn gehaald, is het raadzaam om contact op te nemen met de betreffende serviceprovider voor opheldering. Als je niet tevreden bent met hun antwoord, kun je overwegen een klacht in te dienen bij de betreffende instantie voor gegevensbescherming.
Je hebt de mogelijkheid om specifieke gegevens te verwijderen die mogelijk toegankelijk zijn voor derden, hoewel informatie die publiekelijk op je profiel is geplaatst mogelijk al door anderen is geëxtraheerd.
Helaas is de mate waarin gewone gebruikers hun gegevens kunnen beschermen tegen AI-bedrijven beperkt.Voor het uiteindelijke toezicht en de uiteindelijke autoriteit op dit gebied kan de tussenkomst van regelgevende instanties nodig zijn.