Hoe Llama 2 lokaal downloaden en installeren
Meta bracht Llama 2 uit in de zomer van De nieuwe versie van Llama is verfijnd met 40% meer tokens dan het originele Llama model, waardoor de contextlengte is verdubbeld en het aanzienlijk beter doet dan andere beschikbare open-sourced modellen. De snelste en eenvoudigste manier om toegang te krijgen tot Llama 2 is via een API via een online platform. Als je echter de beste ervaring wilt, kun je Llama 2 het beste direct op je computer installeren en laden.
Met deze overweging in het achterhoofd hebben we een uitgebreide handleiding ontwikkeld die het proces beschrijft van het gebruik van Text-Generation-WebUI om een gekwantificeerd Llama 2 Large Language Model (LLM) te downloaden en uit te voeren op je computer.
Waarom Llama 2 lokaal installeren
Het direct uitvoeren van Llama 2 kan worden gemotiveerd door verschillende factoren, zoals privacyoverwegingen, de wens tot aanpassing en de behoefte aan offline functionaliteit. Als iemand echter bezig is met onderzoek, verfijning of het integreren van Llama 2 in zijn werk, is het gebruik van de API misschien niet geschikt. Het primaire doel van het gebruik van een lokaal AI-model zoals Llama 2 is om de afhankelijkheid van externe AI-bronnen te verminderen en tegelijkertijd te genieten van de flexibiliteit van het gebruik van kunstmatige intelligentie op elk moment en op elke plaats zonder bezorgdheid over het lekken van potentieel gevoelige informatie naar bedrijven en andere entiteiten.
Om te beginnen met onze discussie over het installatieproces van Llama 2 in een lokale omgeving, presenteer ik je een welsprekende en gedetailleerde stap-voor-stap handleiding om deze taak tot een goed einde te brengen.
Stap 1: Installeer Visual Studio 2019 Build Tool
Om het proces te stroomlijnen, hebben we een installatiepakket met één klik geïmplementeerd voor Text-Generation-WebUI, dat wordt gebruikt om te interfacen met Llama 2 via een grafische gebruikersinterface. Het is echter noodzakelijk dat je de Visual Studio 2019 Build Tools verkrijgt en de vereiste componenten installeert voordat je verder gaat met de installatie van het genoemde pakket.
Downloaden: Visual Studio 2019 (gratis)
Voel je vrij om een exemplaar van onze community versie software te verkrijgen door deze nu te downloaden.
⭐ Installeer nu Visual Studio 2019 en open de software. Eenmaal geopend, vink het vakje bureaubladontwikkeling met ⭐ aan en klik op installeren. 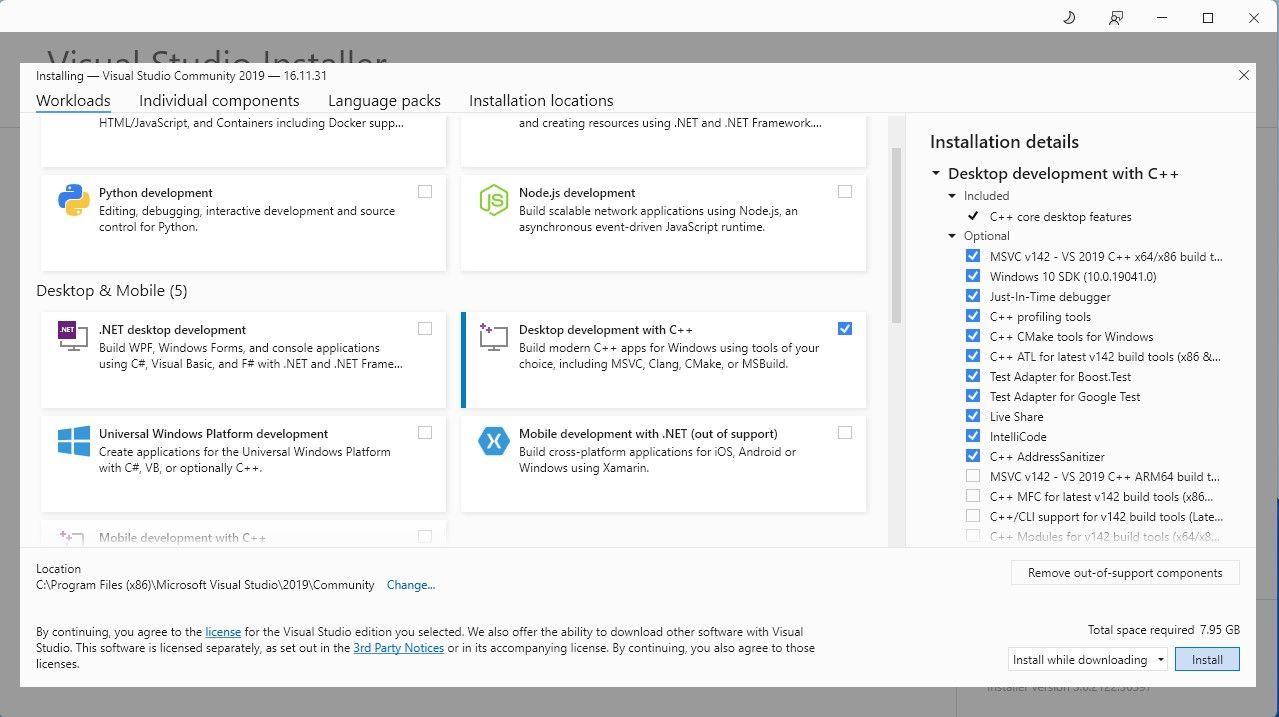
Als de installatie van Desktop development met C\+ voltooid is, ga dan verder met het verkrijgen van het Text-Generation-WebUI installatieprogramma met één klik voor een naadloze ervaring.
Stap 2: Installeer Text-Generation-WebUI
De Text-Generation-WebUI one-click installer is een script dat, door middel van automatisering, de vereiste mappen aanmaakt en de Conda-omgeving configureert samen met alle randvoorwaarden voor het uitvoeren van een Artificial Intelligence model.
Om het script te verkrijgen, kun je de handige one-click installer downloaden door op “Code” te klikken en vervolgens “Download ZIP” te selecteren.
Downloaden: Tekst-Generatie-WebUI Installer (Gratis)
Na het downloaden van een ZIP-archief kun je ervoor kiezen om het uit te pakken en de inhoud op te slaan in een map naar keuze. Om dit te doen, pak je het gecomprimeerde bestand uit door de map te openen die het bevat. Daarna kun je de nieuw aangemaakte map op je gemak verkennen.
⭐ Blader in de map naar beneden en zoek het juiste startprogramma voor je besturingssysteem. Voer de programma’s uit door te dubbelklikken op het juiste script.
Kies een geschikt besturingssysteem en platform voor je softwaretoepassing. Als je Windows als besturingssysteem gebruikt, volg dan deze stappen om je software in te stellen met behulp van een batchbestand:1. Open Bestandsbeheer en navigeer naar de map waar je project zich bevindt.2. Klik met de rechtermuisknop in een leeg gebied van de map en selecteer “Nieuw” in het contextmenu.3. Kies “Alle taken” > “Batchbestand” om een nieuw batchbestand aan te maken. U kunt ook op Ctrl \ Shift \ B drukken of met de rechtermuisknop klikken en “Nieuw batchbestand” selecteren in het contextmenu.4. De standaard teksteditor opent met een leeg document. Kopieer en plak het bijgeleverde codefragment in het document.5. Sla het bestand op door op Ctrl \S te drukken of “Bestand
⭐voor MacOS, selecteer start_macos shell scrip
⭐voor Linux, start_linux shell script. 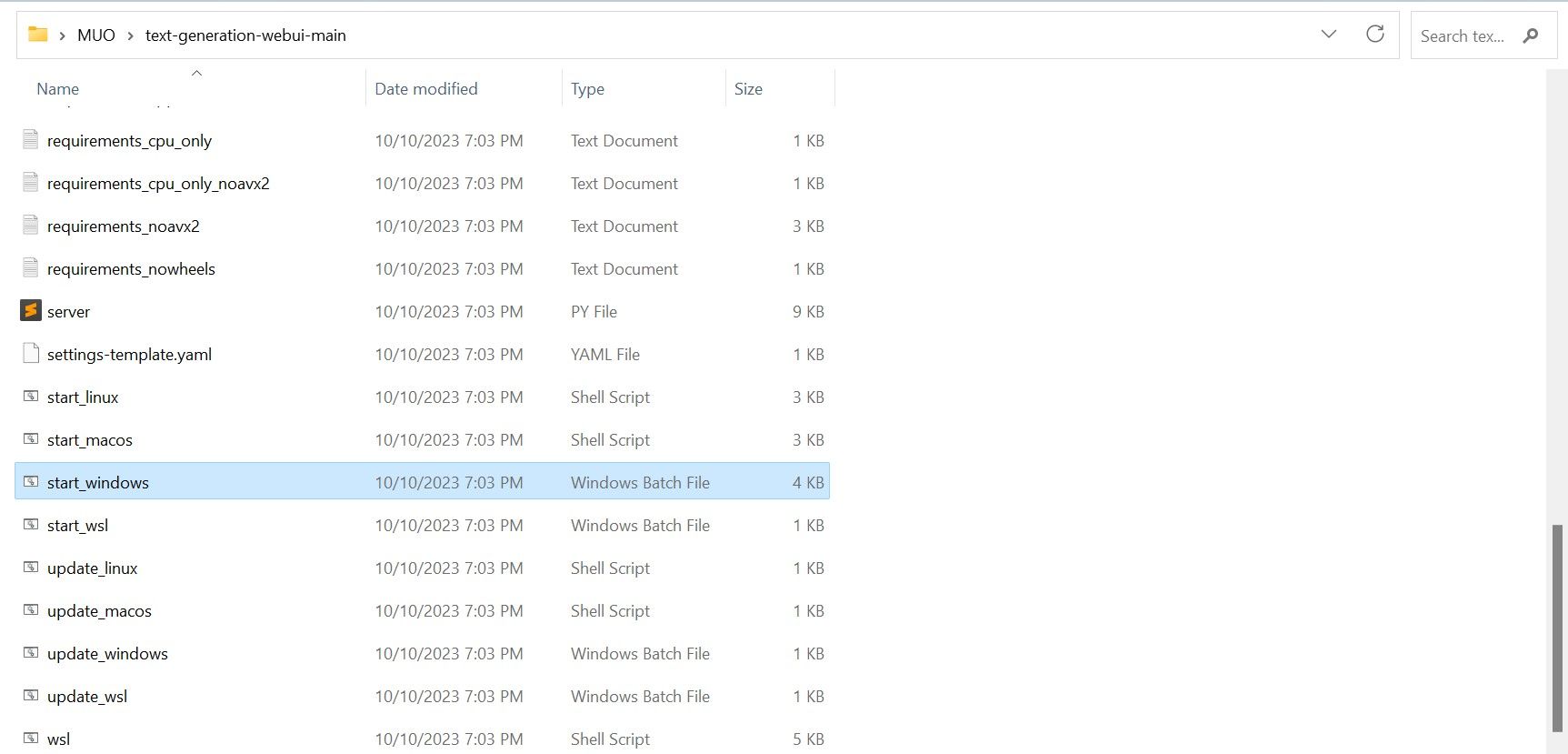
Er kan een indicatie worden weergegeven dat uw antivirussoftware mogelijk schadelijke activiteit heeft gedetecteerd, maar dit hoeft geen reden tot bezorgdheid te zijn omdat het gewoon een vals positief is als gevolg van het uitvoeren van een batchbestand of script. Om door te gaan met de bewerking, klik je op “Toch uitvoeren” om mogelijke beveiligingsproblemen te omzeilen en door te gaan met het proces.
⭐ Een terminal wordt geopend en de installatie wordt gestart. In het begin zal de setup pauzeren en vragen welke GPU je gebruikt. Selecteer het juiste type GPU dat op je computer is geïnstalleerd en druk op enter. Als je geen speciale grafische kaart hebt, selecteer je None (ik wil de modellen in CPU-modus uitvoeren). Houd er rekening mee dat het uitvoeren in CPU-modus veel langzamer is in vergelijking met het uitvoeren van het model met een speciale GPU. 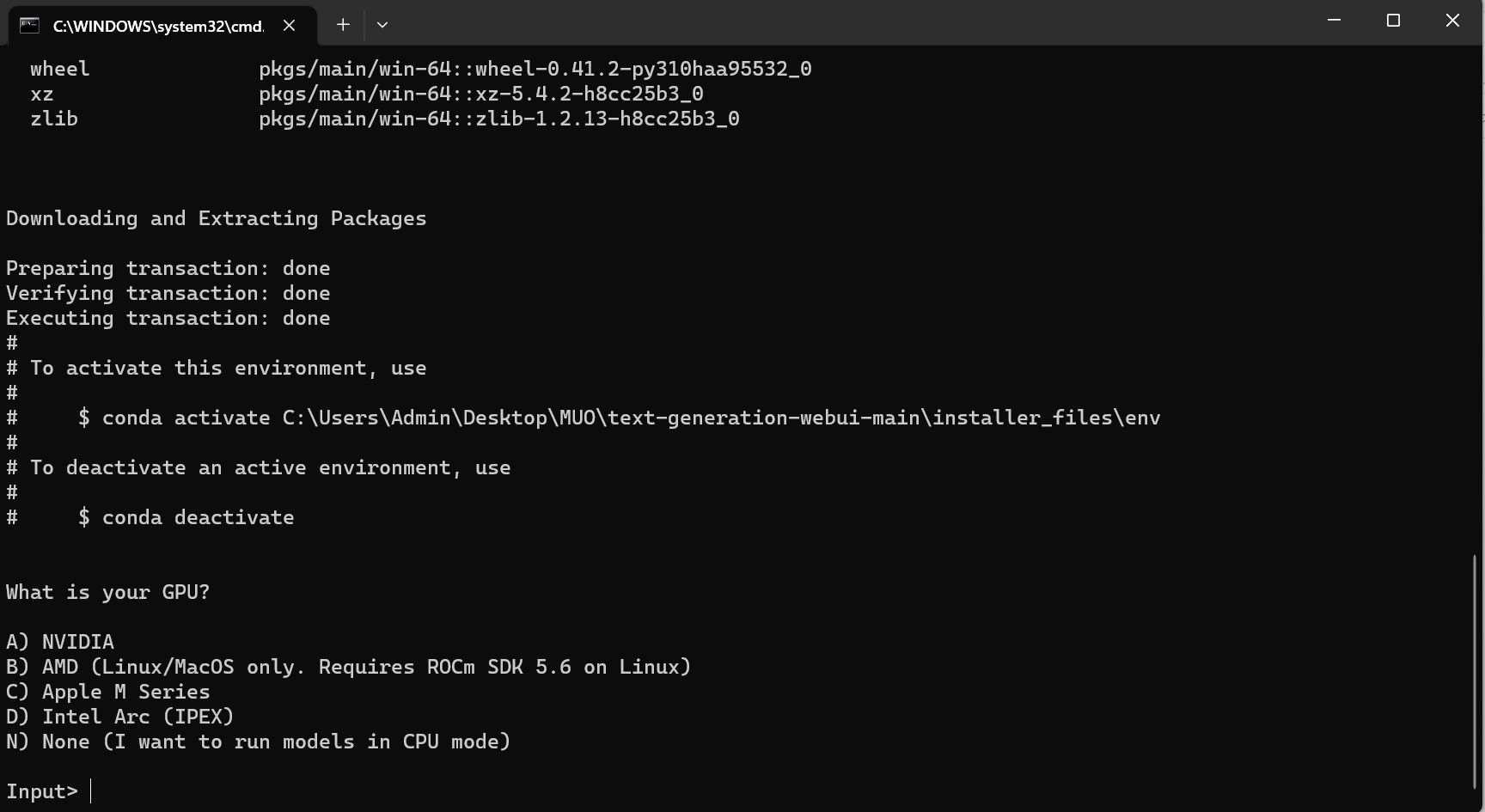
⭐ Zodra de installatie is voltooid, kun je Text-Generation-WebUI lokaal starten. Je kunt dit doen door de webbrowser van je voorkeur te openen en het opgegeven IP-adres in te voeren op de URL. 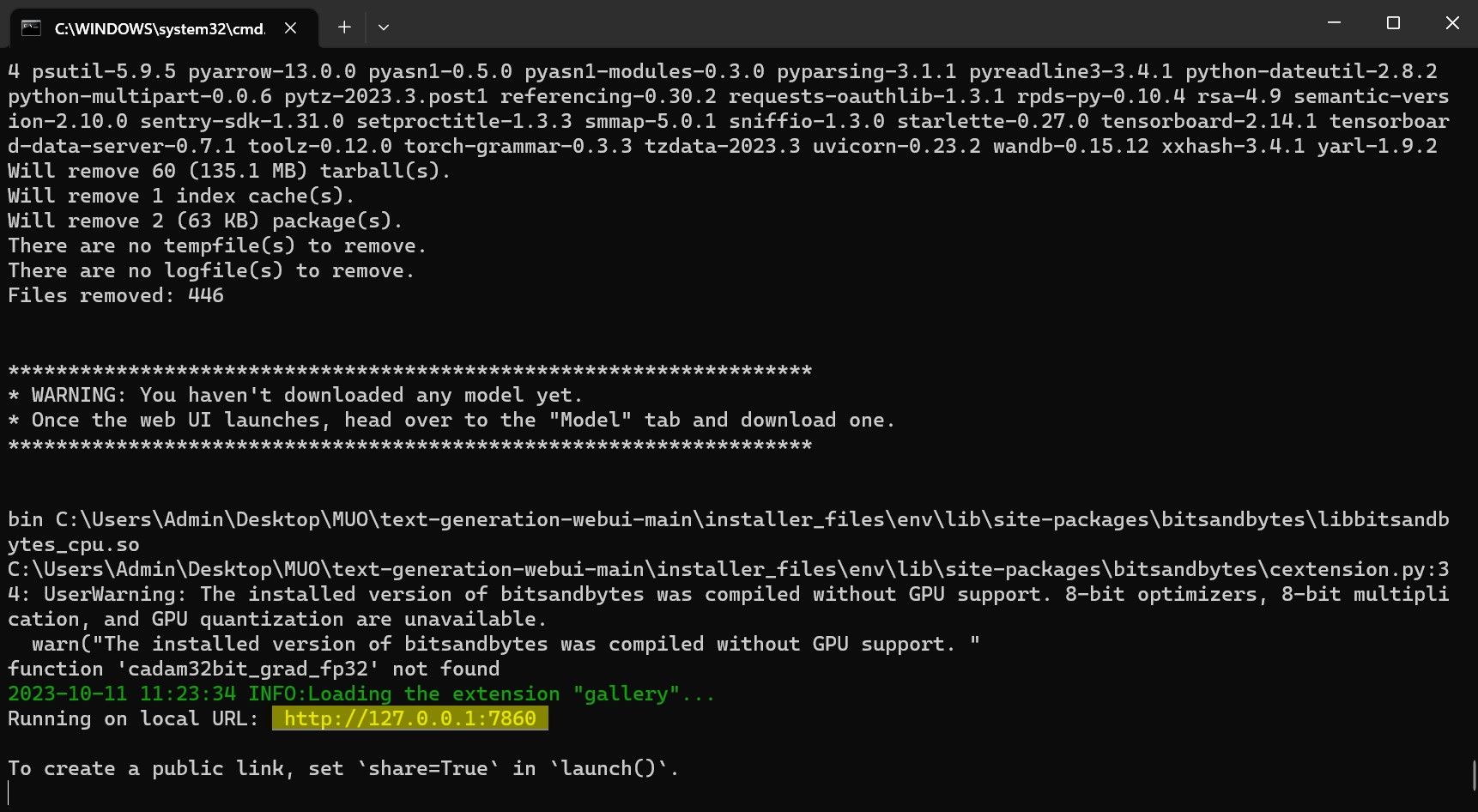
⭐ De WebUI is nu klaar voor gebruik. 
Hoewel de software dient als modellader, moet Llama 2 worden aangeschaft om de functionaliteit te starten.
Stap 3: Download het Llama 2 model
Bij het selecteren van een iteratie van Llama 2 is het belangrijk rekening te houden met verschillende factoren. Dit kunnen parameters, kwantisatie, hardwareoptimalisatie, afmetingen en het beoogde gebruik zijn, die allemaal kunnen worden afgeleid uit de naam van het model.
De grootte van de parameters die voor trainingsdoeleinden worden gebruikt, kan worden beschouwd als een parameter. Over het algemeen resulteren grotere waarden van deze parameter in bekwamere modellen, hoewel een dergelijke toename ten koste kan gaan van de efficiëntie.
standaard en chat. De chatvariant is specifiek verfijnd voor gebruik met conversatieagenten zoals chatbots, terwijl de standaardversie als standaardoptie dient.
Het proces van het optimaliseren van hardware voor het efficiënt uitvoeren van modellen voor machinaal leren kan worden gecategoriseerd als hardwareoptimalisatie. Hierbij wordt bepaald welk specifiek type hardwareplatform optimale prestaties levert voor een bepaald model. GPT-Q is bijvoorbeeld ontworpen en geoptimaliseerd om efficiënt te werken op speciale grafische verwerkingseenheden (GPU’s), terwijl GGML effectief werkt op centrale verwerkingseenheden (CPU’s). Dit onderscheid benadrukt het belang van het kiezen van geschikte hardwareconfiguraties gebaseerd op de unieke vereisten van elk respectief machine-leermodel om de gewenste prestatieniveaus en efficiëntie te bereiken.
Kwantisering verwijst naar het proces van het verkleinen van het bereik of niveau van waarden die worden toegewezen aan gewichten en activeringen binnen een machine-learningmodel tijdens inferentie. De optimalisatie van kwantisatie voor efficiënte berekening omvat het instellen van een specifieke precisiedrempel, zoals q4, die een bepaald detailniveau of granulariteit in gewichts- en activeringswaarden aangeeft.
De term “grootte” in deze context verwijst naar de afmetingen of schaal van een bepaald model, die kan worden uitgedrukt in termen van de fysieke afmetingen of andere relevante meeteenheden.
Merk op dat bepaalde modellen anders gestructureerd kunnen zijn en mogelijk geen identiek formaat voor de presentatie van gegevens hebben. Desalniettemin is een dergelijke nomenclatuur gangbaar binnen de

Het huidige model kan worden gekarakteriseerd als een matig geproportioneerde Llama 2-architectuur, die is getraind met behulp van 13 miljard parameters en specifiek is afgestemd op conversational inference door het gebruik van een speciale centrale verwerkingseenheid (CPU).
Voor gebruikers die een speciale GPU gebruiken, raden we aan een GPT-3-model (GPT-3 Q) te selecteren. Gebruikers die vertrouwen op een CPU kunnen daarentegen het beste kiezen voor GGML. Als je de voorkeur geeft aan interactie met de AI op een manier die lijkt op ChatGPT, overweeg dan om de optie “chat” te kiezen. Als je echter alle mogelijkheden van de AI wilt verkennen, gebruik dan het standaardmodel. Als het gaat om instellingen, moet je weten dat uitgebreidere modellen over het algemeen betere resultaten opleveren, maar ook kunnen leiden tot verminderde efficiëntie. Persoonlijk stel ik voor om te beginnen met een 7B modelconfiguratie. Met betrekking tot kwantisatie is het belangrijk op te merken dat de instelling ‘q4’ uitsluitend bedoeld is voor inferentiedoeleinden en niet voor training of optimalisatie.
Downloaden: GGML (gratis)
Downloaden: GPTQ (gratis)
In de context van het gebruik van een specifieke versie van Llama 2, verzoeken wij u vriendelijk het gewenste model voor uw behoeften aan te schaffen.
In het licht van mijn huidige configuratie als een ultrabook gebruiker, ben ik van plan om een Generalized Game Model (GG
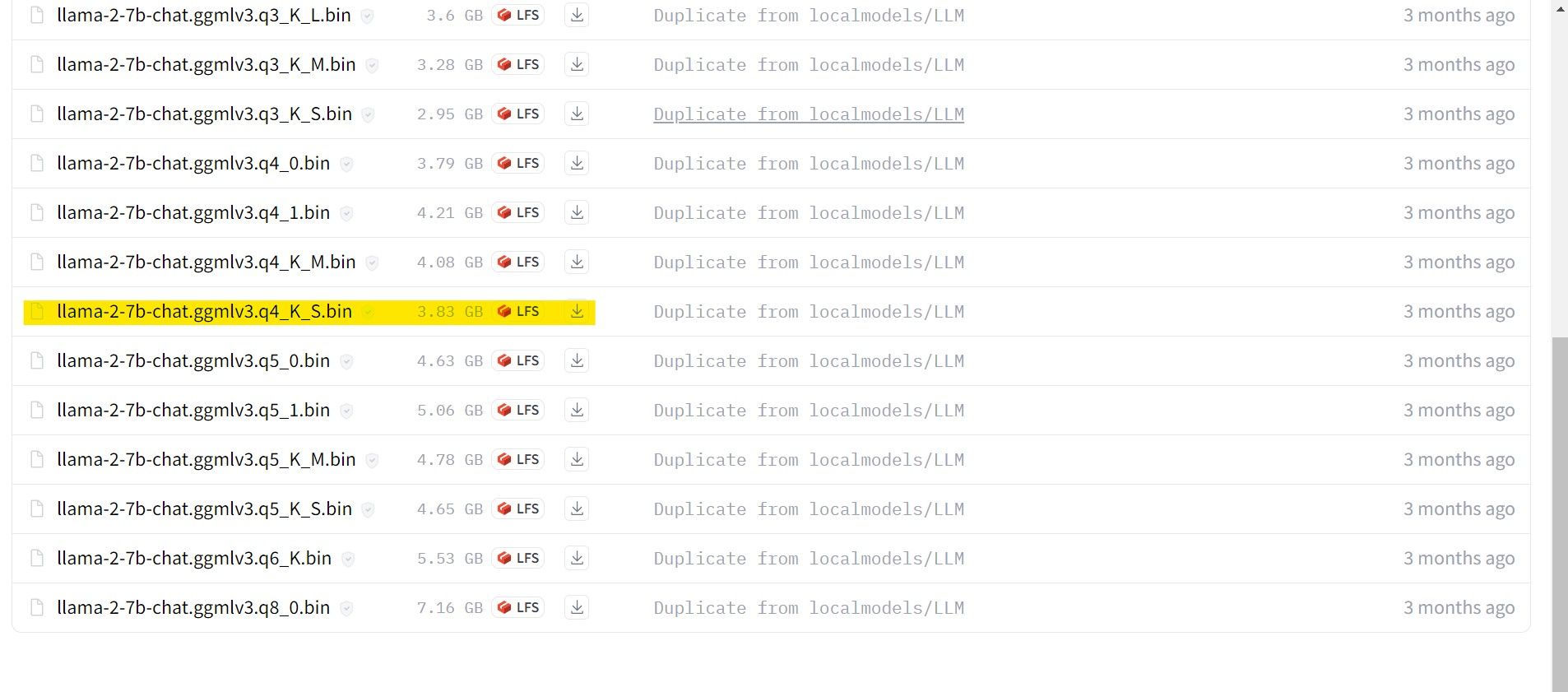
Zodra het downloaden is voltooid, zorg er dan voor dat je het bovengenoemde model overbrengt naar de “text-generation-webui-main” map die zich in de “models” map bevindt.
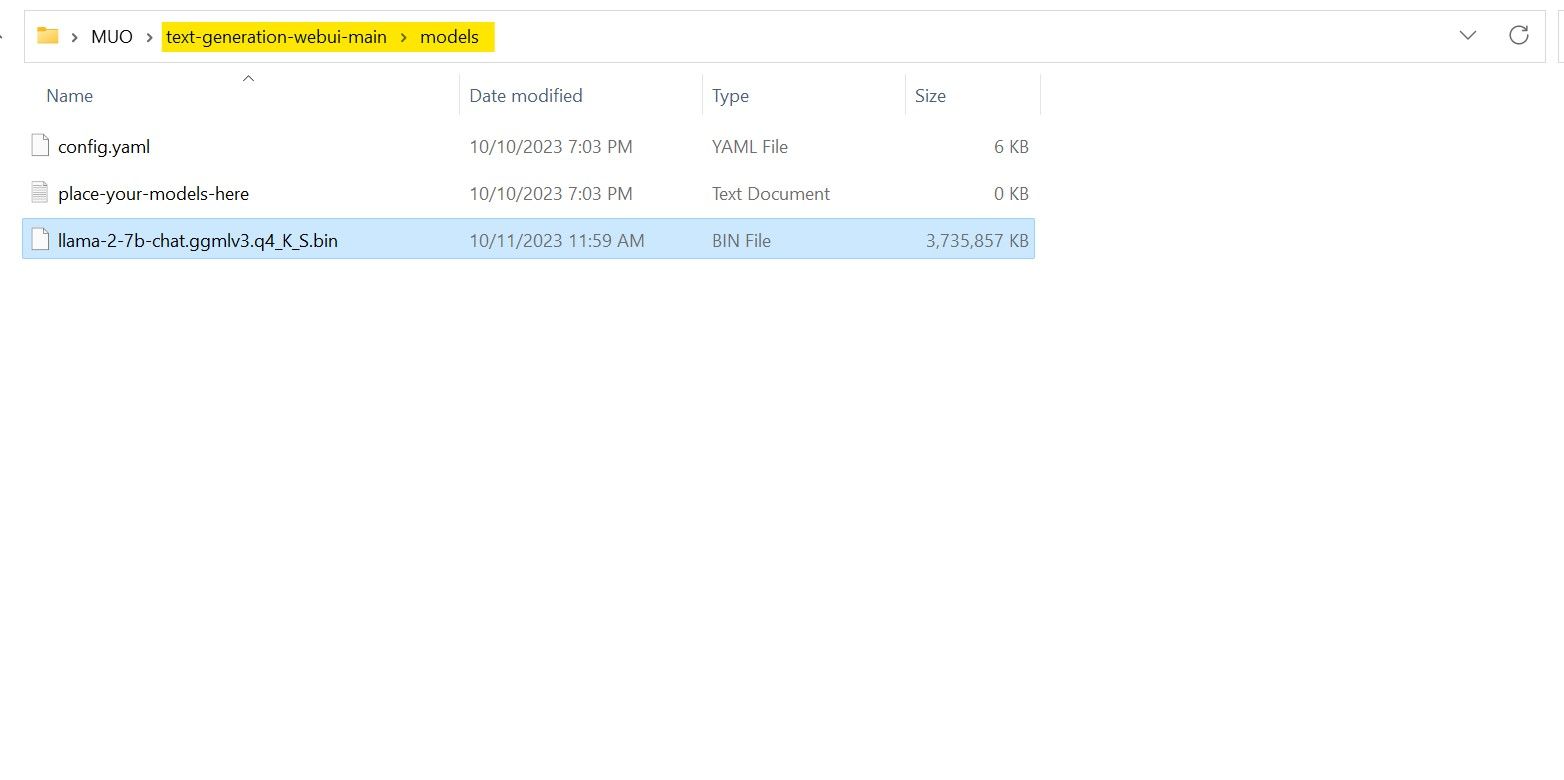
Nu het model is gedownload en opgeslagen in de aangewezen ‘model’ map, is het noodzakelijk om verder te gaan met het configureren van de benodigde componenten voor het laden van dit model.
Stap 4: Tekstgeneratie-WebUI configureren
Laten we nu beginnen met de configuratiefase.
Om de Text-Generation-WebUI op je besturingssysteem te starten, voer je het juiste opstartcommando uit zoals eerder beschreven in de voorgaande stappen.
Gelieve geen godslastering of vulgaire taal te gebruiken op dit platform. Laten we een professionele toon aanhouden in onze communicatie.
⭐ Klik nu op het vervolgkeuzemenu van de modellader en selecteer AutoGPTQ voor degenen die een GTPQ-model gebruiken en ctransformers voor degenen die een GGML-model gebruiken. Klik ten slotte op Load om het model te laden. 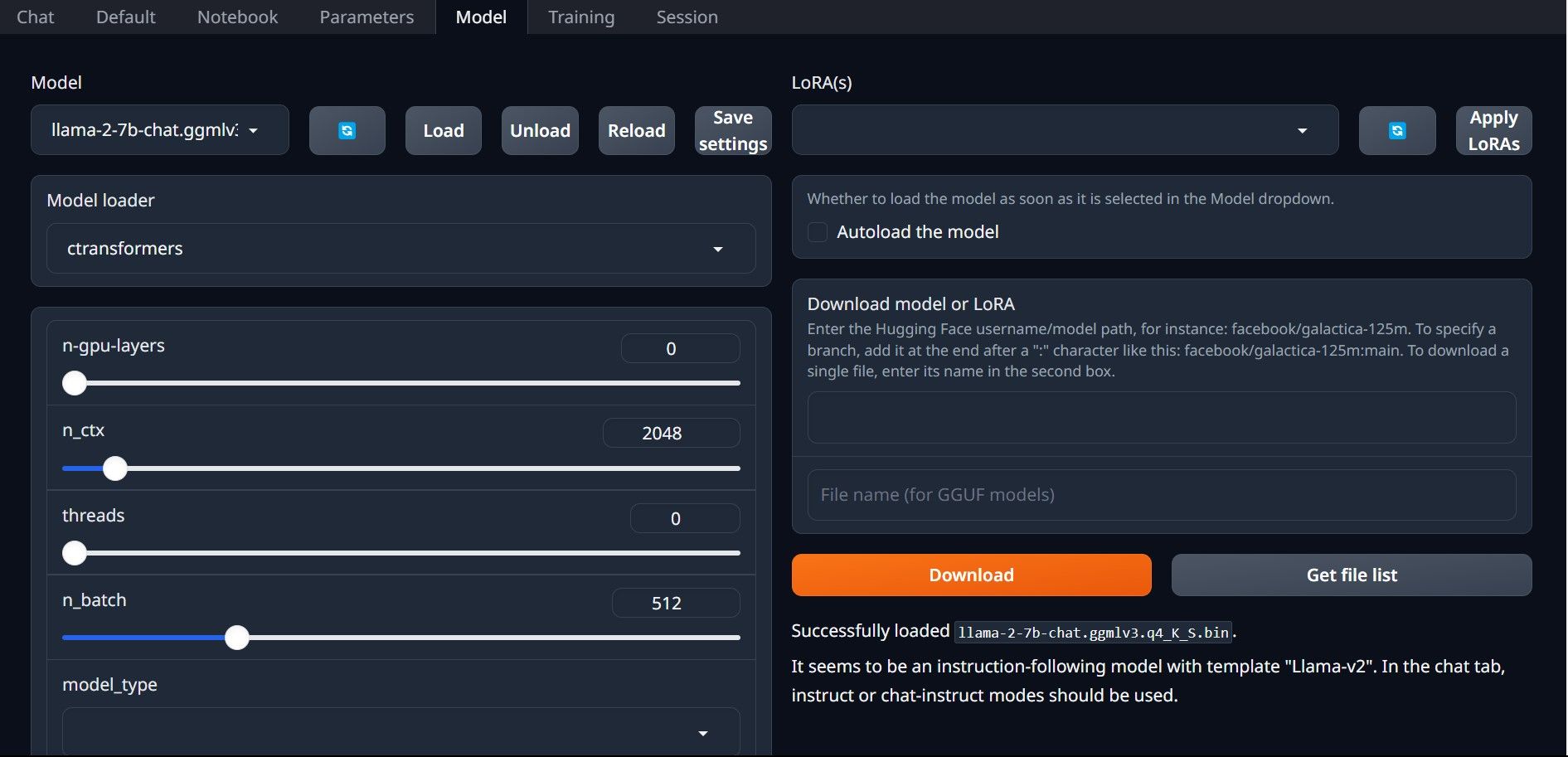
⭐ Om het model te gebruiken, opent u het tabblad Chat en begint u met het testen van het model. 
Gefeliciteerd, je hebt Llama2 met succes geïnstalleerd op je lokale machine!
Andere LLM’s uitproberen
Nu je de mogelijkheid hebt gekregen om Llama 2 uit te voeren met behulp van Tekst-Generatie-WebUI op je eigen computer, begrijp ik dat je ook andere Taalmodel Avatars dan Llama kunt gebruiken. Om dit te doen, houd rekening met de nomenclatuur die gebruikt wordt bij het identificeren van deze avatars, en merk op dat alleen die met verminderde numerieke precisie (meestal aangeduid als “q4”) gebruikt kunnen worden op standaard computerapparatuur. Een groot aantal modellen die dit proces van kwantificering hebben ondergaan zijn te vinden in het enorme archief van HuggingFace. Mocht je je verder willen verdiepen in het rijk van alternatieve avatars, dan zal een zoekopdracht naar TheBloke binnen de eerder genoemde bibliotheek een overvloed aan opties opleveren waaruit