Hoe je Python-code verbeteren met gelijktijdigheid en parallellisme
Belangrijkste opmerkingen
Concurrency en parallellisme zijn essentiële aspecten van de prestaties van computationele taken, waarbij ze elk unieke kenmerken hebben die ze van elkaar onderscheiden.
Concurrency zorgt voor een effectieve toewijzing van bronnen en een verhoogde reactiesnelheid in applicaties, terwijl parallellisme een vitale rol speelt in het bereiken van topprestaties en schaalbaarheid.
Python biedt verschillende benaderingen voor het beheren van gelijktijdige operaties, waaronder het gebruik van threads via de ingebouwde threading bibliotheek en ondersteuning voor asynchroon programmeren met het asyncio framework. Daarnaast stelt de multiprocessing module ontwikkelaars in staat om de kracht van parallelle verwerking in hun applicaties te gebruiken.
Concurrency verwijst naar de mogelijkheid van een systeem om meerdere processen of threads tegelijkertijd uit te voeren, terwijl parallellisme de mogelijkheid is om een taak op te delen in kleinere deeltaken en deze gelijktijdig uit te voeren door verschillende delen van het systeem. In Python zijn er verschillende benaderingen beschikbaar voor het beheren van gelijktijdigheid en parallellisme, zoals multiprocessing, threading, asynchroon programmeren met async/await en het gebruik van bibliotheken zoals Celery of Dask voor gedistribueerd computergebruik. Deze opties kunnen echter tot verwarring leiden bij het kiezen van de meest geschikte aanpak voor een specifieke situatie.
Verdiep je in het scala aan hulpmiddelen en frameworks die de implementatie van gelijktijdige programmeertechnieken in Python effectief kunnen vergemakkelijken, evenals hun onderlinge verschillen.
Concurrency en parallellisme begrijpen
Concurrency en parallellisme zijn twee belangrijke concepten die beschrijven hoe taken worden uitgevoerd in computersystemen, elk met hun eigen unieke kenmerken.
⭐ Concurrency is het vermogen van een programma om meerdere taken tegelijkertijd uit te voeren zonder dat ze noodzakelijkerwijs op exact hetzelfde moment worden uitgevoerd. Het draait om het idee om taken met elkaar te verbinden en ertussen te schakelen op een manier die gelijktijdig lijkt. 
⭐ Bij parallellisme worden daarentegen meerdere taken echt parallel uitgevoerd. Het maakt meestal gebruik van meerdere CPU cores of processoren. Parallellisme zorgt voor echte gelijktijdige uitvoering, waardoor je taken sneller kunt uitvoeren en is zeer geschikt voor rekenintensieve bewerkingen. 
Het belang van gelijktijdigheid en parallellisme
Het belang van gelijktijdige en parallelle verwerking in computers is onbetwistbaar, omdat hiermee meerdere taken tegelijkertijd kunnen worden uitgevoerd, waardoor de efficiëntie toeneemt en de totale uitvoeringstijd afneemt.Deze aanpak is steeds belangrijker geworden door de groeiende vraag naar snellere en efficiëntere verwerkingsmogelijkheden in een breed scala aan toepassingen, van wetenschappelijke simulaties tot automatisering van zakelijke workflows. Door gebruik te maken van de kracht van multi-core processoren en gedistribueerde systemen, maakt gelijktijdige en parallelle verwerking een beter gebruik van bronnen en een betere schaalbaarheid mogelijk, wat uiteindelijk leidt tot betere prestaties en een hogere productiviteit.
Geoptimaliseerde resourcetoewijzing is mogelijk door middel van gelijktijdige verwerking, omdat het effectief gebruik van systeemmiddelen mogelijk maakt, waardoor gegarandeerd wordt dat processen productief blijven doorgaan in plaats van passief te wachten op externe bronnen.
De mogelijkheid om de reactiesnelheid van applicaties te verbeteren, in het bijzonder met betrekking tot gebruikersinterface en webserverinteracties, is een opmerkelijk voordeel van gelijktijdigheid.
Verbeterde prestaties kunnen worden bereikt door parallellisme, vooral bij rekentaken die sterk afhankelijk zijn van centrale verwerkingseenheden (CPU’s), zoals ingewikkelde berekeningen, gegevensmanipulatie en modelsimulaties.
Schaalbaarheid is een kritisch aspect van systeemontwerp, waarbij zowel gelijktijdige uitvoering als parallelle verwerking nodig zijn om optimale prestaties op schaal te bereiken. Het vermogen om toenemende werklasten aan te kunnen met behoud van efficiëntie is van het grootste belang bij de ontwikkeling van moderne software.
In het licht van opkomende trends in hardwaretechnologie die prioriteit geven aan multi-core verwerkingsmogelijkheden, is het noodzakelijk geworden voor softwaresystemen om effectief gebruik te maken van parallellisme om hun levensvatbaarheid en duurzaamheid op de lange termijn te garanderen.
Concurrency in Python
Concurrente uitvoering kan worden bereikt in Python door gebruik te maken van threading of asynchrone technieken, die worden vergemakkelijkt door de asyncio bibliotheek.
Threading in Python
Threading is een intrinsieke eigenschap in Python programmeren die het mogelijk maakt om meerdere gelijktijdige taken aan te maken en te beheren binnen een verenigd proces. Dit mechanisme is vooral voordelig voor taken met zware invoer/uitvoerbewerkingen of taken die kunnen profiteren van parallelle uitvoering.
Python’s threading module biedt een interface op hoog niveau voor het maken en beheren van threads. Hoewel de GIL (Global Interpreter Lock) threads beperkt in termen van echte parallelliteit, kunnen ze nog steeds gelijktijdigheid bereiken door taken efficiënt met elkaar te verbinden.
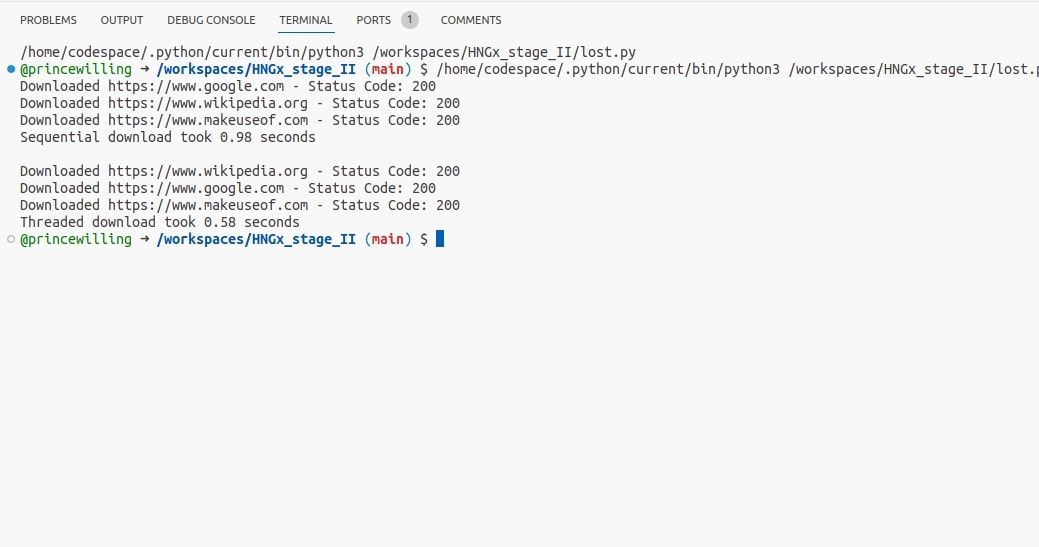
De bijgeleverde code demonstreert een voorbeeld van gelijktijdig programmeren door het gebruik van threads in Python.Specifiek maakt het gebruik van de Python Request bibliotheek voor het initiëren van een HTTP verzoek, wat een typische operatie is die input-output (I/O) operaties met zich meebrengt en kan resulteren in blokkerende taken. Daarnaast maakt de code gebruik van de tijdmodule om de duur van de programma-uitvoering te bepalen.
import requests
import time
import threading
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# function to request a URL
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
# Execute without threads and measure execution time
start_time = time.time()
for url in urls:
download_url(url)
end_time = time.time()
print(f"Sequential download took {end_time - start_time:.2f} seconds\n")
# Execute with threads, resetting the time to measure new execution time
start_time = time.time()
threads = []
for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
# Wait for all threads to complete
for thread in threads:
thread.join()
end_time = time.time()
print(f"Threaded download took {end_time - start_time:.2f} seconds")
Het uitvoeren van dit programma laat inderdaad een waarneembare verbetering in efficiëntie zien bij het gebruik van gelijktijdige threads om I/O-intensieve bewerkingen uit te voeren, ondanks het marginale tijdsverschil tussen sequentiële en parallelle uitvoeringen.
Asynchroon programmeren met Asyncio
asyncio biedt een gebeurtenislus die asynchrone taken beheert die coroutines worden genoemd. CoroutineÂs zijn functies die je kunt pauzeren en hervatten, waardoor ze ideaal zijn voor I/O-gebonden taken. De bibliotheek is vooral handig voor scenario’s waarin taken moeten wachten op externe bronnen, zoals netwerkverzoeken.
Om het vorige voorbeeld van synchroon verzoeken verzenden aan te passen voor gebruik met asynchroon programmeren in Python, moet je een paar wijzigingen aanbrengen. Ten eerste, in plaats van requests.get() en time.sleep() te gebruiken, wat blokkeringsoperaties zijn die de uitvoering pauzeren tot respectievelijk de voltooiing of verstreken tijd, zou je niet-blokkeringsalternatieven moeten gebruiken zoals asyncio en aiohttp . Dit houdt in dat je de bestaande code in een asynchrone functie wikkelt met async def en de traditionele I/O-bewerkingen vervangt door hun async tegenhangers. Bijvoorbeeld, async met aiohttp.ClientSession().post(url) zou gebruikt kunnen worden om een POST verzoek asynchroon te versturen zonder te wachten op een antwoord. Daarnaast moeten de foutafhandeling en logboekregistratie mogelijk worden aangepast aan het nieuwe async framework.
import asyncio
import aiohttp
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# asynchronous function to request URL
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"Downloaded {url} - Status Code: {response.status}")
# Main asynchronous function
async def main():
# Create a list of tasks to download each URL concurrently
tasks = [download_url(url) for url in urls]
# Gather and execute the tasks concurrently
await asyncio.gather(*tasks)
start_time = time.time()
# Run the main asynchronous function
asyncio.run(main())
end_time = time.time()
print(f"Asyncio download took {end_time - start_time:.2f} seconds")
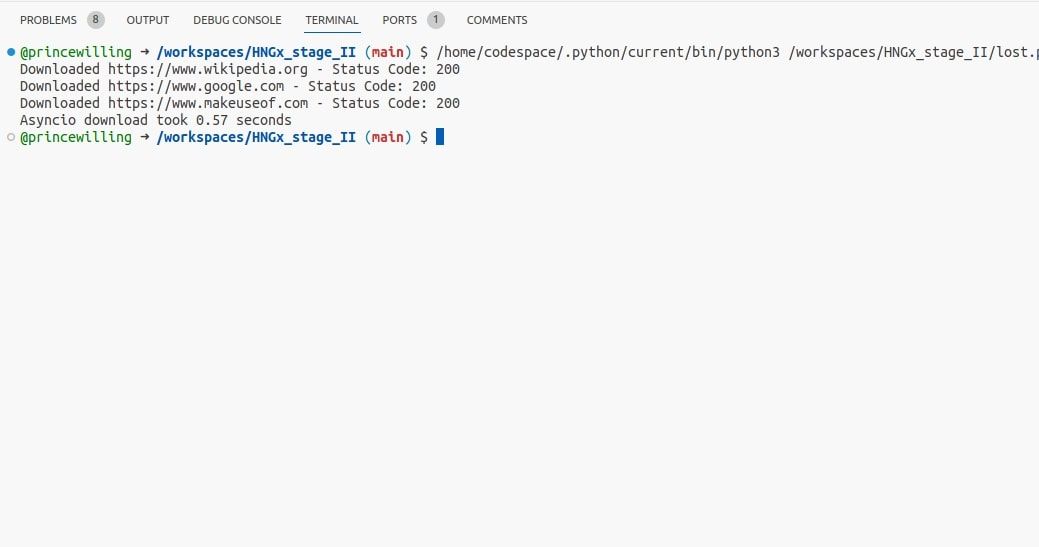
Met behulp van de meegeleverde code kan men efficiënt meerdere gelijktijdige downloads van webpagina’s uitvoeren door gebruik te maken van de mogelijkheden van asyncio en de kracht van asynchrone I/O-bewerkingen te benutten. In tegenstelling tot traditionele threading-technieken die beter geschikt zijn voor CPU-intensieve taken, is deze aanpak vooral effectief bij het optimaliseren van I/O-gebonden processen.
Parallellisme in Python
Je kunt parallellisme implementeren met behulp van Python’s multiprocessing module , waarmee je optimaal gebruik kunt maken van multicore processoren.
Multiprocessing in Python
De multiprocessing module van Python biedt een aanpak om parallellisme te benutten door het creëren van individuele processen, elk uitgerust met zijn eigen Python-interpreter en geheugendomein. Hierdoor omzeilt deze methode de Global Interpreter Lock (GIL) die vaak voorkomt in CPU-gebonden taken.
import requests
import multiprocessing
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# function to request a URL
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
def main():
# Create a multiprocessing pool with a specified number of processes
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)
start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
# Close the pool and wait for all processes to finish
pool.close()
pool.join()
print(f"Multiprocessing download took {end_time-start_time:.2f} seconds")
main()
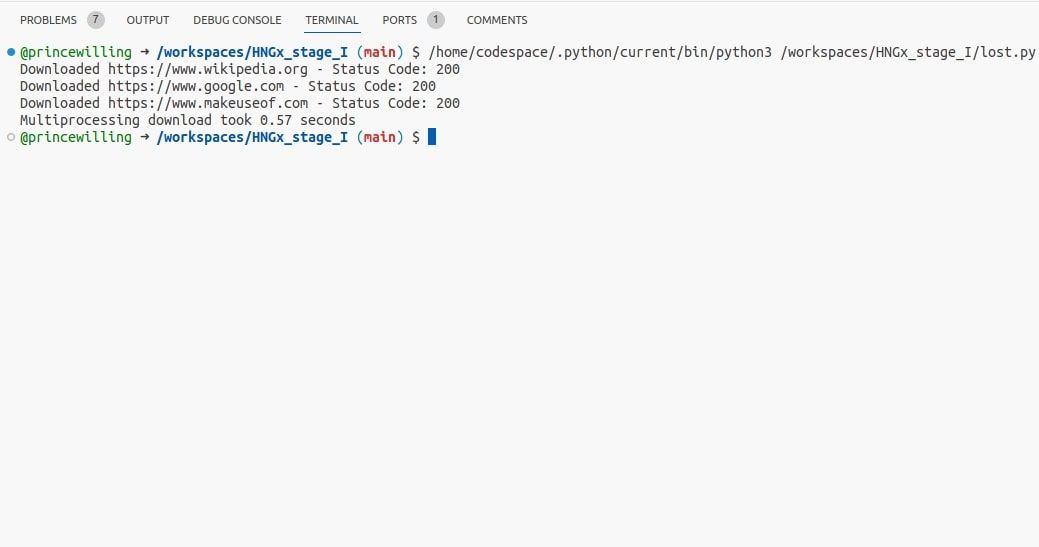
Multiprocessing maakt het mogelijk om de functie download_url gelijktijdig over meerdere processen uit te voeren, waardoor parallelle verwerking van de gegeven URL mogelijk wordt.
Wanneer gelijktijdige of parallelle verwerking gebruiken
De beslissing om te kiezen voor gelijktijdige of parallelle verwerking hangt af van de kenmerken van de bewerkingen die worden uitgevoerd en de capaciteit van de hardwarebronnen van het onderliggende systeem.
Bij het afhandelen van input/output (I/O)-gerichte bewerkingen, zoals lees/schrijfbewerkingen van bestanden of netwerkverzoeken, wordt het gebruik van concurrency aanbevolen vanwege de mogelijkheid om meerdere taken tegelijk af te handelen. Daarnaast kan het gebruikt worden in situaties waar geheugenbeperkingen een uitdaging vormen.
Wanneer het gebruik van multiprocessing geschikt is voor CPU-intensieve bewerkingen die verbeterd kunnen worden door gelijktijdige uitvoering en wanneer het zorgen voor een robuuste scheiding van processen prioriteit heeft, omdat het falen van elk proces de anderen niet onnodig mag beïnvloeden.
Profiteer van Concurrency en Parallelisme
Parallelisme en gelijktijdige uitvoering zijn bruikbare methoden om de efficiëntie en doorvoer van Python-programma’s te verbeteren. Het is echter cruciaal om de verschillen tussen deze technieken te begrijpen om een weloverwogen beslissing te nemen over welke aanpak het beste past bij een bepaalde situatie.
Python biedt een uitgebreide verzameling gereedschappen en modules waarmee ontwikkelaars de efficiëntie van hun code kunnen verbeteren door gebruik te maken van gelijktijdige of parallelle verwerkingstechnieken, ongeacht of de betreffende taken voornamelijk van computationele of input/output-intensieve aard zijn.