데이터 증강은 학습 데이터에 다양한 변환을 적용하는 프로세스입니다. 데이터 세트의 다양성을 높이고 과적합을 방지하는 데 도움이 됩니다. 과적합은 주로 모델을 훈련할 데이터가 제한되어 있을 때 발생합니다.
여기서는 텐서플로우의 데이터 증강 모듈을 사용하여 데이터 집합을 다양화하는 방법을 알아봅니다. 이렇게 하면 원본 데이터와 약간 다른 새로운 데이터 포인트를 생성하여 과적합을 방지할 수 있습니다.
사용할 샘플 데이터 집합
Kaggle 의 고양이와 개 데이터 집합을 사용합니다. 이 데이터 세트에는 약 3,000개의 고양이와 개 이미지가 포함되어 있습니다. 이 이미지는 훈련, 테스트 및 검증 세트로 나뉩니다.

레이블 1.0은 개를 나타내고 레이블 0.0은 고양이를 나타냅니다.
데이터 증강 기법을 구현하는 전체 소스 코드와 그렇지 않은 소스 코드는 GitHub 리포지토리에서 확인할 수 있습니다.
텐서플로우 설치 및 가져오기
이 과정을 따라하려면 Python에 대한 기본적인 이해가 있어야 합니다. 또한 머신 러닝에 대한 기본 지식이 있어야 합니다. 복습이 필요한 경우 머신 러닝에 대한 튜토리얼을 참조하는 것이 좋습니다.
열기 Google Colab . 런타임 유형을 GPU로 변경합니다. 그런 다음 첫 번째 코드 셀에서 다음 매직 명령을 실행하여 TensorFlow를 사용자 환경에 설치합니다.
!pip install tensorflow
TensorFlow와 관련 모듈 및 클래스를 가져옵니다.
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
데이터 세트에서 데이터 증강을 수행할 수 있는 tensorflow.keras.preprocessing.image를 사용합니다.
이미지 데이터 생성기 클래스의 인스턴스 생성
열차 데이터에 대한 이미지 데이터 생성기 클래스의 인스턴스를 생성합니다. 이 객체는 학습 데이터를 전처리하는 데 사용됩니다. 모델 훈련 중에 증강 이미지 데이터 배치를 실시간으로 생성합니다.
이미지가 고양이인지 개인지 분류하는 작업에서는 뒤집기, 임의 너비, 임의 높이, 임의 밝기 및 확대/축소 데이터 증강 기법을 사용할 수 있습니다. 이러한 기법은 실제 시나리오를 나타내는 원본 데이터의 변형을 포함하는 새로운 데이터를 생성합니다.
# define the image data generator for training
train_datagen = ImageDataGenerator(rescale=1./255,
horizontal_flip=True,
width_shift_range=0.2,
height_shift_range=0.2,
brightness_range=[0.2,1.0],
zoom_range=0.2)
테스트 데이터에 대한 ImageDataGenerator 클래스의 다른 인스턴스를 만듭니다. 재조정 매개변수가 필요합니다. 이 매개변수는 테스트 이미지의 픽셀 값을 훈련 중에 사용된 형식과 일치하도록 정규화합니다.
# define the image data generator for testing
test_datagen = ImageDataGenerator(rescale=1./255)
유효성 검사 데이터에 대한 ImageDataGenerator 클래스의 최종 인스턴스를 생성합니다. 테스트 데이터와 동일한 방식으로 유효성 검사 데이터의 스케일을 다시 조정합니다.
# define the image data generator for validation
validation_datagen = ImageDataGenerator(rescale=1./255)
테스트 및 유효성 검사 데이터에 다른 증강 기법을 적용할 필요는 없습니다. 이는 모델이 테스트 및 유효성 검사 데이터를 평가 목적으로만 사용하기 때문입니다. 원본 데이터 배포를 반영해야 합니다.
데이터 로드 중
트레이닝 디렉토리에서 DirectoryIterator 객체를 만듭니다. 이 객체는 증강 이미지 배치를 생성합니다. 그런 다음 학습 데이터를 저장하는 디렉터리를 지정합니다. 이미지 크기를 고정된 크기인 64×64픽셀로 조정합니다. 각 배치에 사용할 이미지 수를 지정합니다. 마지막으로 라벨 유형을 이진(예: 고양이 또는 개)으로 지정합니다.
# defining the training directory
train_data = train_datagen.flow_from_directory(directory=r'/content/drive/MyDrive/cats_and_dogs_filtered/train',
target_size=(64, 64),
batch_size=32,
class_mode='binary')
테스트 디렉토리에서 다른 DirectoryIterator 객체를 생성합니다. 매개변수를 훈련 데이터와 동일한 값으로 설정합니다.
# defining the testing directory
test_data = test_datagen.flow_from_directory(directory='/content/drive/MyDrive/cats_and_dogs_filtered/test',
target_size=(64, 64),
batch_size=32,
class_mode='binary')
유효성 검사 디렉터리에서 최종 DirectoryIterator 객체를 만듭니다. 매개변수는 훈련 및 테스트 데이터의 매개변수와 동일하게 유지합니다.
# defining the validation directory
validation_data = validation_datagen.flow_from_directory(directory='/content/drive/MyDrive/cats_and_dogs_filtered/validation',
target_size=(64, 64),
batch_size=32,
class_mode='binary')
디렉터리 반복기는 유효성 검사 및 테스트 데이터 집합을 보강하지 않습니다.
모델 정의하기
신경망의 아키텍처를 정의합니다. 컨볼루션 신경망(CNN)을 사용합니다. CNN은 이미지의 패턴과 특징을 인식하도록 설계되었습니다.
model = Sequential()
# convolutional layer with 32 filters of size 3x3
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
# max pooling layer with pool size 2x2
model.add(MaxPooling2D(pool_size=(2, 2)))
# convolutional layer with 64 filters of size 3x3
model.add(Conv2D(64, (3, 3), activation='relu'))
# max pooling layer with pool size 2x2
model.add(MaxPooling2D(pool_size=(2, 2)))
# flatten the output from the convolutional and pooling layers
model.add(Flatten())
# fully connected layer with 128 units and ReLU activation
model.add(Dense(128, activation='relu'))
# randomly drop out 50% of the units to prevent overfitting
model.add(Dropout(0.5))
# output layer with sigmoid activation (binary classification)
model.add(Dense(1, activation='sigmoid'))
이진 교차 엔트로피 손실 함수를 사용하여 모델을 컴파일합니다. 이진 분류 문제는 일반적으로 이 함수를 사용합니다. 옵티마이저는 아담 옵티마이저를 사용합니다. 이는 적응형 학습률 최적화 알고리즘입니다. 마지막으로 정확도 측면에서 모델을 평가합니다.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
모델의 아키텍처에 대한 요약을 콘솔에 인쇄합니다.
model.summary()
다음 스크린샷은 모델 아키텍처의 시각화를 보여줍니다.
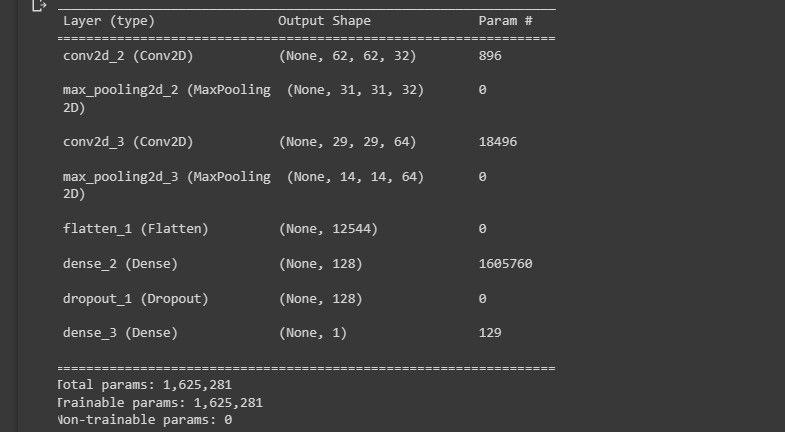
모델 디자인이 어떻게 보이는지에 대한 개요를 제공합니다.
모델 훈련하기
fit() 메서드를 사용하여 모델을 훈련합니다. 에포크당 단계 수를 훈련 샘플 수를 batch_size로 나눈 값으로 설정합니다. 또한 유효성 검사 데이터와 유효성 검사 단계 수를 설정합니다.
# Train the model on the training data
history = model.fit(train_data,
steps_per_epoch=train_data.n // train_data.batch_size,
epochs=50,
validation_data=validation_data,
validation_steps=validation_data.n // validation_data.batch_size)
ImageDataGenerator 클래스는 훈련 데이터에 데이터 증강을 실시간으로 적용합니다. 따라서 모델의 학습 과정이 느려집니다.
모델 평가하기
평가() 메서드를 사용하여 테스트 데이터에 대한 모델의 성능을 평가합니다. 또한 테스트 손실 및 정확도를 콘솔에 인쇄합니다.
test_loss, test_acc = model.evaluate(test_data,
steps=test_data.n // test_data.batch_size)
print(f'Test loss: {test_loss}')
print(f'Test accuracy: {test_acc}')
다음 스크린샷은 모델의 성능을 보여줍니다.

이 모델은 한 번도 본 적이 없는 데이터에 대해 상당히 잘 수행합니다.
데이터 증강 기법을 구현하지 않은 코드를 실행하면 모델 학습 정확도가 즉, 과적합입니다. 또한 이전에 본 적이 없는 데이터에 대해서는 성능이 저하됩니다. 이는 데이터 세트의 특성을 학습하기 때문입니다.
데이터 증강이 도움이 되지 않는 경우는 언제인가요?
⭐ 데이터 집합이 이미 다양하고 큰 경우: 데이터 증강은 데이터 세트의 크기와 다양성을 증가시킵니다. 데이터 세트가 이미 크고 다양하다면 데이터 증강은 유용하지 않습니다.
⭐ 데이터 집합이 너무 작은 경우: 데이터 증강은 원래 데이터 세트에 없는 새로운 기능을 만들 수 없습니다. 따라서 모델이 학습하는 데 필요한 대부분의 기능이 부족한 작은 데이터 세트는 보정할 수 없습니다.
⭐ 데이터 증강 유형이 부적절한 경우: 예를 들어, 객체의 방향이 중요한 경우 회전 이미지가 도움이 되지 않을 수 있습니다.
텐서플로우의 기능
텐서플로는 다양하고 강력한 라이브러리입니다. 복잡한 딥러닝 모델을 훈련할 수 있으며 스마트폰부터 서버 클러스터에 이르기까지 다양한 기기에서 실행할 수 있습니다. 머신 러닝을 활용하는 엣지 컴퓨팅 장치를 강화하는 데 도움이 되었습니다.