웹 스크래핑을 활용하면 웹 사이트에서 데이터를 자동화된 방식으로 추출할 수 있으므로 시간과 노력이 많이 소요되는 수동 프로세스를 거치지 않고도 종합적인 분석이 가능합니다. 이러한 작업을 수작업으로 수행할 수도 있지만, 웹 스크래핑 도구를 사용하면 절차를 신속하게 처리하고 비용을 절감하면서 효율성을 높일 수 있습니다.
실제로 Google 스프레드시트는 IMPORTXML 기능을 통해 종합적인 웹 스크래핑 솔루션으로서 흥미로운 가능성을 제시합니다. 이 기능을 사용하면 웹 사이트에서 정보를 원활하게 추출할 수 있으며 분석 작업, 보고서 생성 또는 데이터 기반 인사이트가 필요한 기타 작업과 같은 다양한 목적에 정보를 쉽게 활용할 수 있습니다.
구글 스프레드시트의 IMPORTXML 기능
구글 스프레드시트에 내장된 ‘IMPORTXML’이라는 기능을 활용하면 XML, HTML, RSS, CSV 등 다양한 웹 형식에서 데이터를 추출할 수 있어 고급 프로그래밍 기술을 통해 웹 사이트에서 정보를 수집하는 과정을 간소화할 수 있습니다.
IMPORTXML 함수의 기본 구조는 다음과 같습니다:
=IMPORTXML(url, xpath_query)
URL(Uniform Resource Locator)은 웹 스크래핑 기술을 사용하여 정보를 추출하고자 하는 특정 웹페이지의 주소를 지정합니다.
XML 문서 내에서 요소를 탐색하고 선택하기 위한 언어인 XPath 표현식은 해당 소스에서 검색하려는 정보를 나타냅니다.
HTML을 포함한 XML 기반 구조에서 정보를 탐색하고 찾기 위한 탐색 도구 역할을 하는 XPath(XML 경로 언어)의 활용은 IMPORTXML의 기능을 효과적으로 사용할 때 매우 중요합니다. 이 강력한 기능의 잠재력을 최대한 활용하려면 XPath 쿼리의 복잡성을 파악하는 것이 중요합니다.
XPath 이해
XPath는 HTML 문서 내에서 정보를 탐색하고 필터링할 수 있는 다양한 함수와 연산자를 제공합니다. 그러나 XML과 XPath의 모든 측면에 대해 자세히 설명하는 것은 이 글의 범위를 벗어납니다. 그럼에도 불구하고 HTML 구조 내에서 데이터를 탐색하고 조작하는 데 중요한 몇 가지 기본 XPath 원칙에 대해 설명합니다.
계층 구조 내에서 특정 요소를 선택하는 프로세스는 슬래시 “/”와 이중 슬래시 “//”를 활용하여 수행됩니다. 이러한 문자를 사용하여 지정된 문서 내에서 특정 노드를 대상으로 하는 경로를 지정할 수 있습니다. 예를 들어, “/html/body/div”라는 표현은 특정 HTML 페이지의 본문 섹션에 있는 div 요소의 모든 인스턴스를 식별하는 수단으로 사용됩니다.
웹 페이지 내의 특정 속성을 식별하기 위해 해당 속성 이름 뒤에 at 기호를 사용할 수 있습니다. 예를 들어, “//@href” 명령은 추가 분석 또는 조작을 위해 웹 페이지에 존재하는 모든 href 속성을 추출합니다.
[ ]로 표시된 대괄호 안에 술어를 사용하면 속성 또는 특성에 따라 요소를 필터링할 수 있습니다. 예를 들어 “/div[@class=’container’]”라는 표현으로 표시되는 “class” 속성이 “container”와 같은 모든 div 요소를 선택하는 것입니다.
XPath는 “contains()”, “starts-with()”, “text()” 등의 연산자를 활용하여 텍스트 콘텐츠 또는 속성 값을 확인할 수 있는 함수를 비롯한 다양한 기능을 제공합니다.
웹사이트에서 XPath를 추출하는 방법
특정 웹사이트에서 요소의 XPath를 추출하는 것은 원하는 요소와 HTML 구조 내 해당 위치에 대한 지식과 함께 IMPORTXML 함수를 활용하여 수행할 수 있습니다. 이 프로세스에는 태그 이름 또는 클래스 속성을 사용하여 대상 요소를 지정한 다음 상위 요소를 탐색하거나 상대 경로를 활용하는 등 다양한 기술을 사용하여 원하는 정보의 정확한 위치를 찾아내는 과정이 포함됩니다. 일단 획득한 XPath는 지정된 요소에서 데이터를 검색하는 데 중요한 식별자 역할을 하여 Google 스프레드시트 내에서 웹 콘텐츠를 효율적으로 추출하고 조작할 수 있게 해줍니다.
IMPORTXML을 활용하면 정보를 추출하기 위해 웹사이트의 아키텍처에 대한 백과사전적 지식이 필요하지 않습니다. 편리하게도 각 웹 브라우징 애플리케이션에는 모든 요소의 XPath를 즉시 복사할 수 있는 편리한 기능이 있습니다.
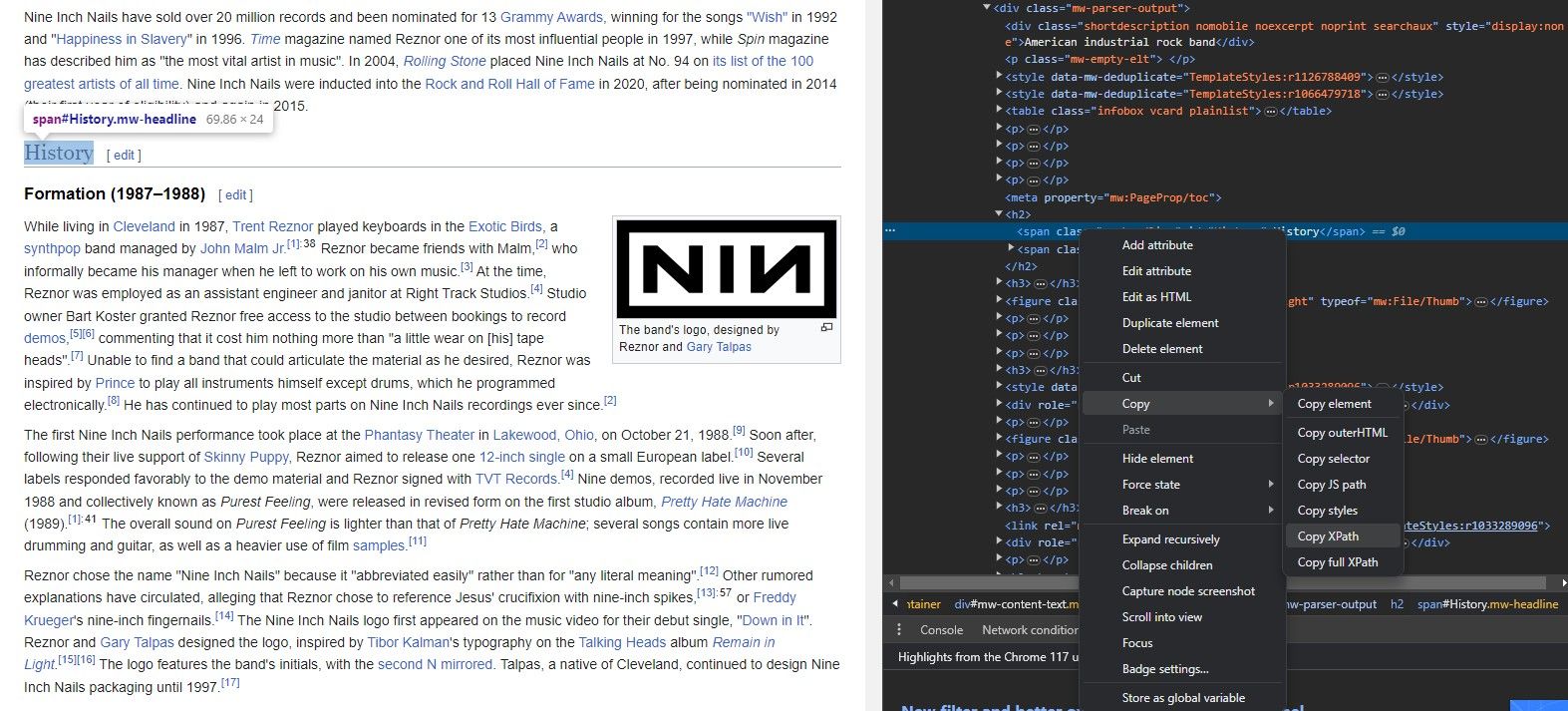
“요소 검사” 도구를 사용하면 웹페이지의 특정 요소에서 XPath 표현식을 추출할 수 있습니다. 이를 수행하려면 다음 단계를 따르세요:
스크래핑을 위해 원하는 웹페이지에 액세스하려면 선택한 인터넷 브라우저를 활용하세요.
스크래핑 기술을 사용하여 웹 페이지에서 원하는 특정 데이터 또는 정보를 식별하고 검색하려면 먼저 원하는 콘텐츠가 있는 웹 페이지에서 관련 요소를 찾아야 합니다. 여기에는 검색 엔진, 브라우저 개발자 확장 프로그램 또는 특수 스크래핑 소프트웨어와 같은 다양한 도구를 활용하여 추출할 대상 정보를 찾아 분리하는 작업이 포함될 수 있습니다. 일단 식별되면 적절한 코드를 사용하여 원하는 데이터를 자동화된 방식으로 추출할 수 있으므로 여러 소스에서 대량의 정보를 효율적으로 수집할 수 있습니다.
지정된 요소를 마우스 오른쪽 버튼으로 클릭하면 해당 요소와 관련된 추가 옵션 또는 컨텍스트 메뉴에 액세스할 수 있습니다.
컨텍스트 메뉴에서 ‘요소 검사’를 선택하면 브라우저에 웹페이지의 기본 HTML 코드가 포함된 패널이 표시됩니다. 이 패널은 해당 코드 내에서 초점이 맞춰진 특정 HTML 구성 요소를 눈에 띄게 표시합니다.
요소 검사 패널에 액세스하고 그 안에서 선택한 요소를 편집하려면 먼저 마우스 커서로 클릭하거나 터치스크린 장치를 사용하는 경우 탭하여 수정하려는 요소를 선택합니다. 요소가 강조 표시되면 해당 키보드 키를 누른 상태에서 마우스 오른쪽 버튼을 클릭(또는 모바일 장치의 경우 화면 하단 가장자리에서 위로 스와이프)하면 선택한 요소를 추가로 조작할 수 있는 추가 옵션이 나타납니다.
앞서 언급한 도구를 사용하면 ‘XPath 복사’를 클릭하기만 하면 특정 요소와 연결된 XPath 주소를 원활하게 복사할 수 있습니다.
이제 필요한 도구를 마음대로 사용할 수 있으므로 다양한 소스에서 링크를 추출하여 IMPORTXML의 실제 적용을 시연할 수 있습니다.
IMPORTXML로 웹사이트에서 링크를 스크랩하는 방법
IMPORTXML을 사용하면 하이퍼링크, 비디오 및 이미지와 같은 멀티미디어 콘텐츠, 기타 광범위한 웹 페이지 구성 요소를 포함하여 웹 사이트에서 다양한 유형의 정보를 추출할 수 있습니다. 하이퍼링크는 인터넷 기반 연구에서 중요한 역할을 하며, 하이퍼링크가 가리키는 목적지를 조사하여 사이트의 구조와 목적에 대한 귀중한 통찰력을 제공합니다.
Google 스프레드시트에서 IMPORTXML을 활용하면 웹페이지에서 링크 데이터를 효율적으로 추출한 후 플랫폼에서 제공하는 다양한 분석 기능을 통해 이러한 요소에 대한 종합적인 조사를 수행할 수 있습니다.
모든 링크 스크래핑
웹사이트에 존재하는 모든 URL을 추출하려면 다음과 같은 방법을 사용할 수 있습니다:
=IMPORTXML(url, "//a/@href")
제공된 XPath 표현식은 앵커 태그와 연결된 href 속성 값을 검색하여 HTML 문서 내에 존재하는 사용 가능한 모든 하이퍼링크를 효율적으로 추출하도록 설계되었습니다.
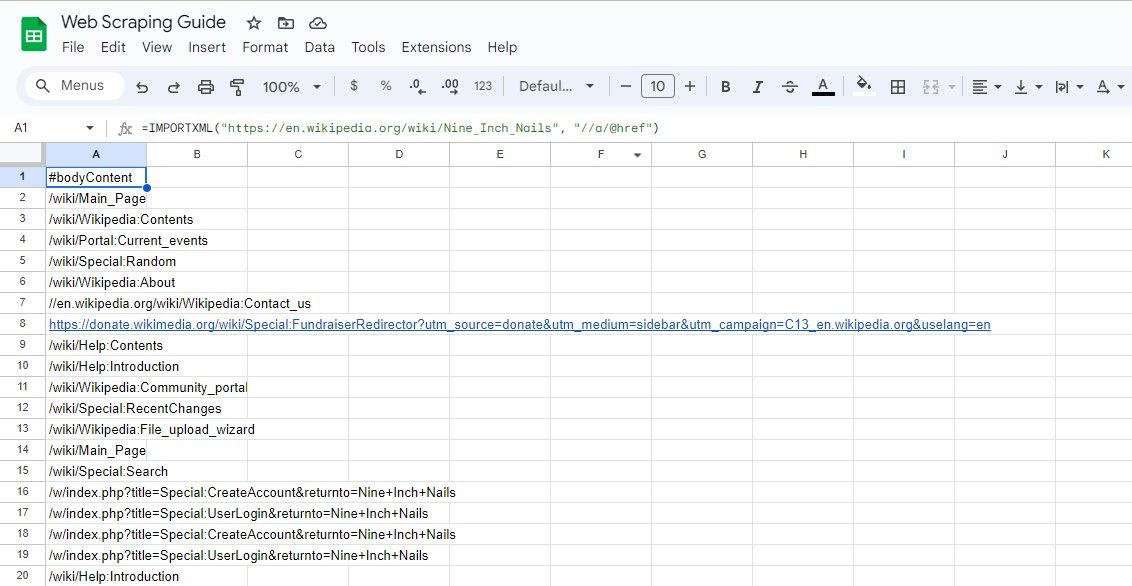
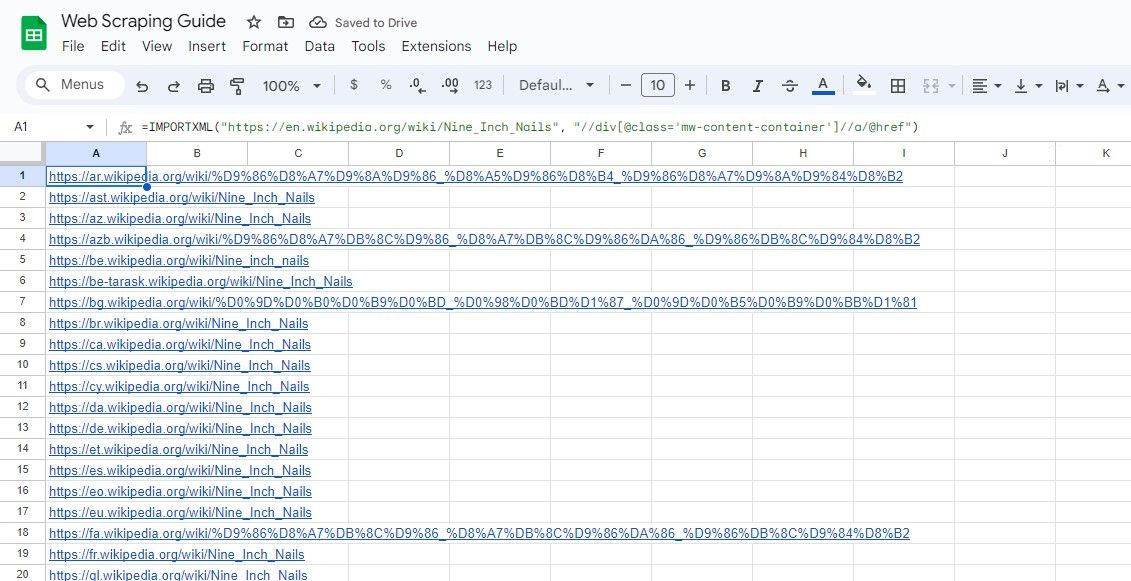
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
제공된 표현식은 위키백과 항목 내에 존재하는 모든 하이퍼링크를 추출합니다.
개별 셀에 웹 페이지의 URL을 입력한 후 참조하는 방식을 통합하면 지나치게 긴 수식을 피할 수 있어 유리한 것으로 밝혀졌습니다. XPath 쿼리를 공식화할 때도 유사한 접근 방식을 채택하여 사용 편의성과 가독성을 높일 수 있습니다.
모든 링크 텍스트 스크래핑
주어진 텍스트 내의 하이퍼링크의 콘텐츠와 웹 주소를 모두 검색하려면 다음과 같은 방법을 사용할 수 있습니다:
=IMPORTXML(url, "//a")
주어진 쿼리는 포괄적인 데이터 집합을 검색하여 얻은 결과에서 링크된 텍스트와 해당 URL 정보를 모두 추출할 수 있도록 합니다.
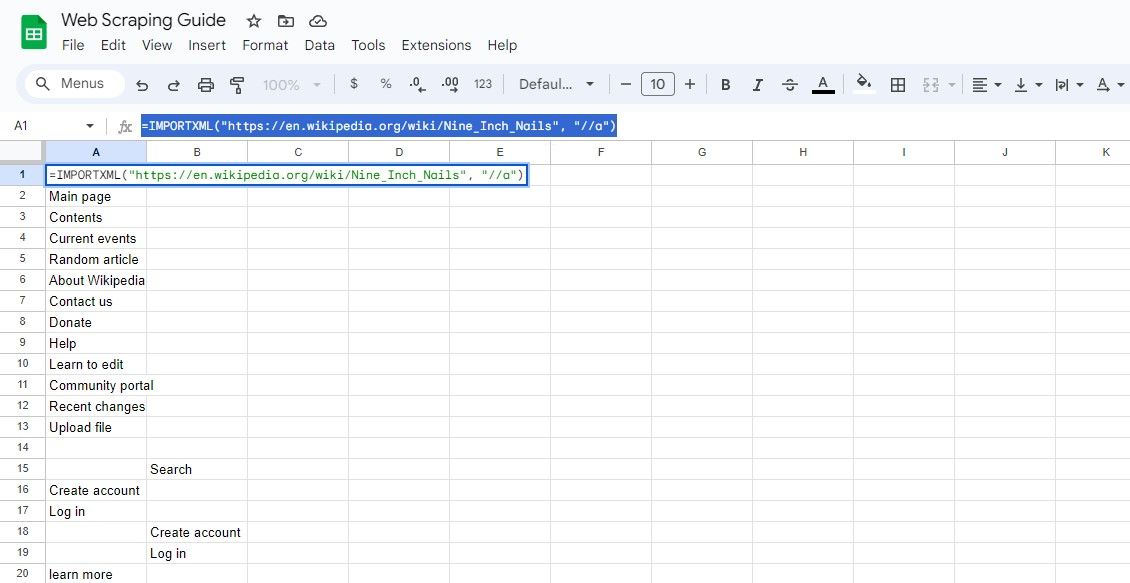
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
앞서 언급한 방정식은 동일한 위키백과 항목 내에 존재하는 하이퍼링크를 검색합니다.
IMPORTXML을 사용하여 웹사이트에서 특정 링크를 스크랩하는 방법
때로는 미리 정해진 특정 매개변수를 기반으로 특정 소스에서 웹 페이지를 검색해야 할 수 있습니다. 예를 들어, 특정 키워드가 포함된 URL이나 웹페이지의 특정 부분 내에 위치한 URL을 얻고자 할 수 있습니다.
XPath에 대한 포괄적인 이해를 활용하면 원하는 요소를 정확하게 식별할 수 있습니다.
키워드가 포함된 링크 스크래핑
XPath를 사용하여 특정 키워드가 포함된 URL을 추출하기 위해 “contains()” 함수를 사용할 수 있습니다. 이를 통해 콘텐츠 내에 지정된 용어가 포함되어 있는지 또는 제외되어 있는지에 따라 요소를 필터링할 수 있습니다.
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
주어진 쿼리는 문자열의 일부로 특정 검색어가 포함된 href 값을 가진 HTML 요소의 href 속성을 검색합니다.
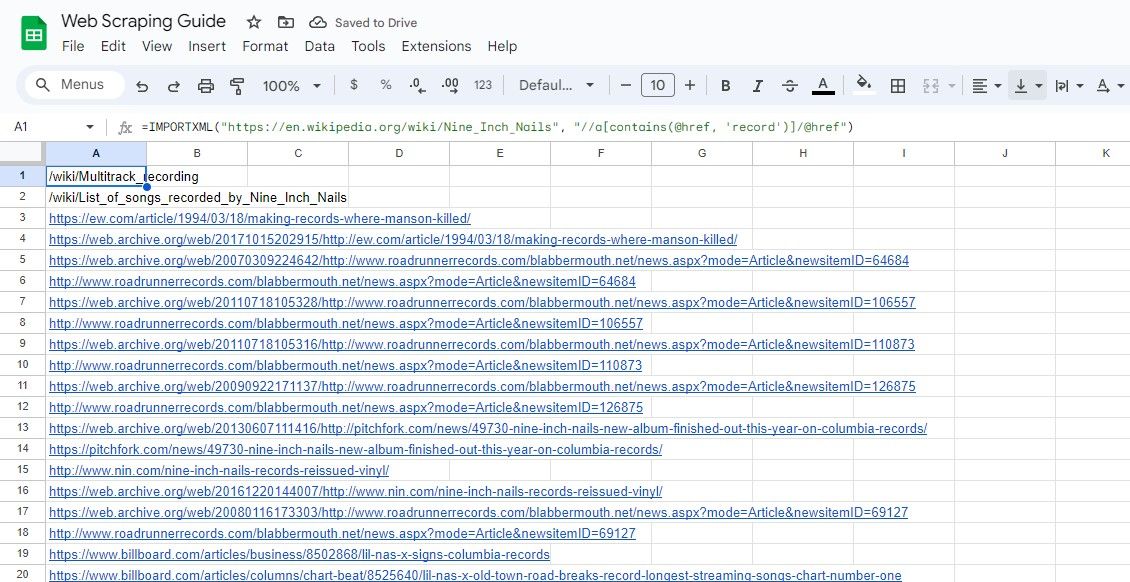
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
앞서 설명한 알고리즘은 앵커 텍스트의 일부로 “record”라는 용어가 포함된 임의의 Wikipedia 페이지 본문 내에서 발견되는 모든 URL을 추출합니다.
섹션 내 링크 스크래핑
웹페이지의 특정 부분에서 링크를 추출하기 위해 XPath 표현식을 사용하여 해당 영역을 식별할 수 있습니다. 다음 코드 스니펫을 예로 들어 보겠습니다:
=IMPORTXML(url, "//div[@class='section']//a/@href")
주어진 쿼리는 클래스 속성 “섹션”을 가진
By 최은지
윈도우(Windows)와 웹 서비스에 대한 전문 지식을 갖춘 노련한 UX 디자이너인 최은지님은 효율적이고 매력적인 디지털 경험을 개발하는 데 탁월한 능력을 발휘합니다. 사용자의 입장에서 생각하며 누구나 쉽게 접근하고 즐길 수 있는 콘텐츠를 개발하는 데 주력하고 있습니다. 사용자 경험을 향상시키기 위해 연구를 거듭하는 은지님은 All Things N 팀의 핵심 구성원으로 활약하고 있습니다.