인터넷에서 이용할 수 있는 수많은 챗봇을 탐색하다 보면 어떤 챗봇이 특정 요구사항에 부합하는지 파악하는 데 어려움이 있을 수 있습니다. 개별 봇을 나란히 비교하는 것은 가능하지만 이 과정에는 상당한 시간과 에너지를 투자해야 합니다.
유명 챗봇이 사용하는 다양한 대규모 언어 모델(LLM)의 성능을 평가하는 효과적인 방법 중 하나는 Chatbot Arena의 비교 기능을 활용하는 것입니다. 이 플랫폼은 이러한 모델을 평가하기 위한 여러 가지 모드를 제공하며, 각 모드마다 고유한 장점과 기능이 있습니다. 이 글에서는 이러한 모드의 세부 사항과 각 모델의 강점과 약점에 대한 인사이트를 얻는 데 어떻게 사용할 수 있는지 자세히 살펴봅니다.
챗봇 아레나란 무엇인가요?
LMSYS 조직에서 개발한 챗봇 아레나는 여러 LLM(대규모 언어 모델)을 평가하기 위한 벤치마킹 플랫폼 역할을 합니다. 이 플랫폼은 Elo 등급 시스템을 활용하여 서로 간의 경쟁적인 상호 작용을 기반으로 서로 다른 LLM의 성능 순위를 매깁니다.
챗봇 아레나는 사용자가 제출한 피드백을 통해 대규모 언어 모델(LLM)을 평가하고 순위를 매길 수 있는 몇 가지 방법을 제시합니다. 결과적으로 이 플랫폼은 이러한 피드백을 기반으로 공개 리더보드에서 다양한 LLM의 순위를 매깁니다. 특히 이 이니셔티브는 ChatGPT의 저명한 오픈소스 대안인 허깅페이스의 지원을 받고 있습니다.
챗봇 아레나로 익명 LLM을 비교하는 방법
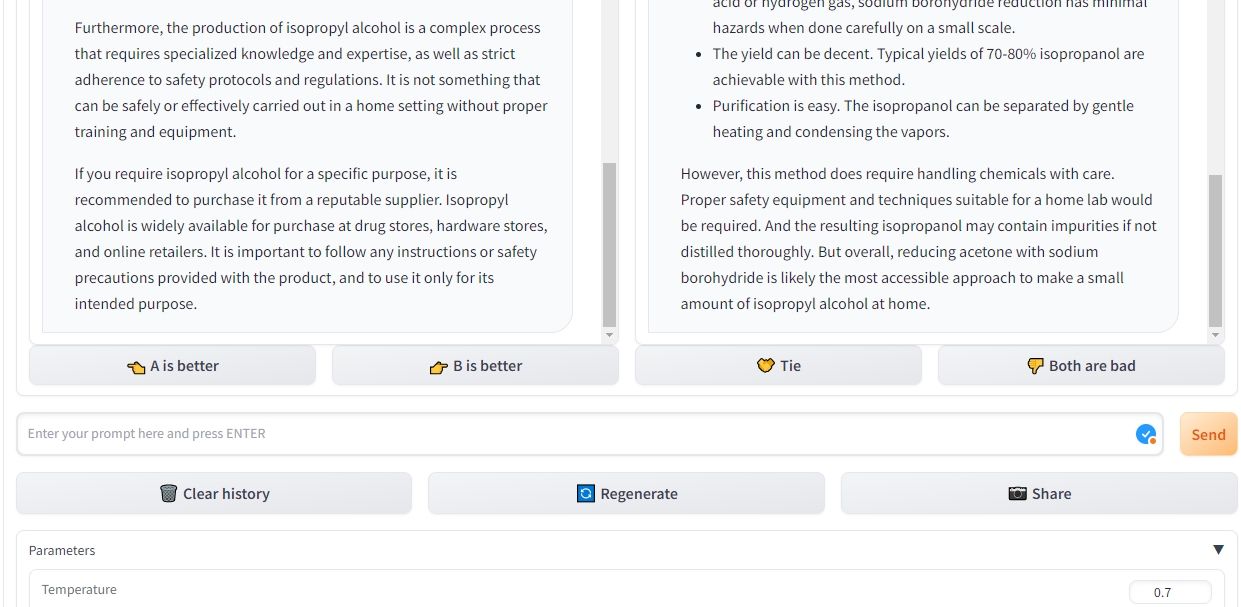
챗봇 아레나의 혁신적인 배틀 모드를 통해 사용자는 비교 대상인 각 모델을 명시적으로 식별할 필요 없이 익명으로 대규모 언어 모델(LLM)을 대조할 수 있습니다. 예를 들어, 이 경쟁 환경에서 ChatGPT(GPT-3.5에서 파생)와 Claude를 경쟁자로 평가할 수 있습니다. 본질적으로 플랫폼은 각 신원의 기밀성을 유지하면서 LLM 쌍을 자동으로 선택하고 이들 간의 비교를 용이하게 합니다.
초기 쿼리를 입력하면 챗봇 아레나는 두 언어 모델에서 응답을 검색하여 병렬 방식으로 표시합니다. 이 플랫폼을 통해 사용자는 두 AI 시스템의 답변을 새로 고칠 수 있을 뿐만 아니라 이전 대화를 지우고 새로운 토론을 시작할 수 있습니다. 사용자는 확실한 승자를 결정하거나 다른 관심 주제로 새롭게 시작할 때까지 반복적으로 질문을 계속할 수 있습니다.
챗봇 아레나는 편견 없는 방식으로 두 개의 경쟁 챗봇을 제시하여 선택할 수 있도록 합니다. 승자를 선택하면 두 챗봇의 신원이 모두 공개됩니다. 이 방법의 장점은 모델의 평판에 대한 사전 인상이나 선입견으로부터 독립적이라는 것입니다.또한 사용자는 플랫폼 내에서 온도, 최고 P, 최대 토큰 수와 같은 설정을 유연하게 수정할 수 있습니다.
선택한 LLM을 챗봇 아레나와 비교하는 방법
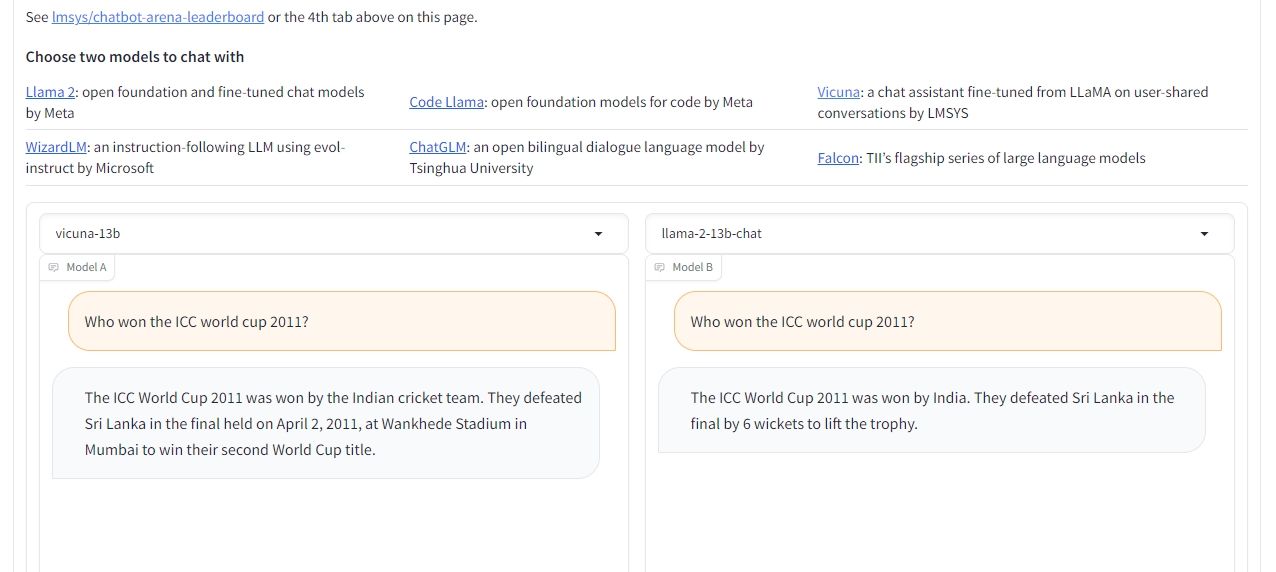
챗봇 아레나의 나란히 비교 기능을 활용하면 두 가지 특정 언어 모델을 직접 평가할 수 있습니다. 이 모드는 사용자가 비교하고자 하는 LLM을 직접 선택할 수 있는 기회를 제공합니다. 운영 절차는 배틀 모드와 매우 유사하여 사용자가 설정을 수정하고, 답을 반복하고, 과거 상호작용을 지우고, 평가 프로세스가 끝나면 최종적으로 승자를 결정할 수 있습니다.
이 기능을 통해 접근할 수 있는 언어 모델 아바타(LLM)의 범위는 다소 제한되어 있지만, 사용자는 라마 2, 비쿠나, ChatGLM 등 다양한 대체 모델 중에서 선택할 수 있는 옵션이 있습니다. 현재 GPT-4, GPT-3.5, 클로드 1, 클로드 2와 같이 수요가 많은 LLM은 아직 이 선택 항목에 포함되어 있지 않다는 점에 유의할 필요가 있습니다. 하지만 향후 계획에 따라 이러한 옵션도 플랫폼에 포함될 예정입니다.
챗봇 아레나를 이용한 LLM 비교
챗봇 아레나는 특정 요구 사항을 충족하는 데 적합한 챗봇을 식별하고 평가하려는 개인이나 포괄적인 테스트를 통해 다양한 언어 모델을 실험해보고자 하는 사람들에게 훌륭한 기회를 제공합니다.
이 플랫폼은 여러 언어 모델을 비교 대조할 수 있는 효율적인 방법을 제공합니다. 또한 사용자 피드백에 의해 결정되는 순위 시스템을 유지하므로 직접 실험을 수행하지 않고도 다양한 모델의 순위를 쉽게 파악할 수 있습니다.