Scikit-LLM은 광범위한 scikit-learn 에코시스템 내에 최첨단 대규모 언어 모델(LLM)을 원활하게 통합하도록 설계된 고급 Python 라이브러리입니다. 이러한 통합을 통해 다양한 텍스트 분석 작업을 쉽게 실행할 수 있습니다. 사용자는 scikit-learn에 능숙해지면 Scikit-LLM의 기능을 보다 효과적으로 탐색하고 활용할 수 있습니다.
Scikit-LLM과 scikit-learn은 서로 다른 두 개의 라이브러리이며, 전자는 텍스트 분석에 맞춤화된 반면 후자는 보다 광범위하게 적용할 수 있는 머신 러닝 도구로 사용됩니다. 이 두 라이브러리는 이름 접두사를 공유하지만 서로 바꿔서 사용할 수 없다는 점에 유의해야 합니다.
Scikit-LLM 시작하기
Scikit-LLM 을 시작하려면 라이브러리를 설치하고 API 키를 구성해야 합니다. 라이브러리를 설치하려면 IDE를 열고 새 가상 환경을 만듭니다. 이렇게 하면 잠재적인 라이브러리 버전 충돌을 방지하는 데 도움이 됩니다. 그런 다음 터미널에서 다음 명령을 실행합니다.
pip install scikit-llm
이 명령을 실행하면 필요한 모든 전제 조건과 함께 Scikit-LLM을 쉽게 설치할 수 있습니다.
대규모 언어 모델(LLM) 제공업체에서 사용할 API 키를 설정하려면 먼저 해당 제공업체로부터 키를 확보해야 합니다. OpenAI API 키를 활용하고자 하는 경우 다음 지침을 참조하세요:
OpenAI API 페이지 로 이동합니다. 그런 다음 창 오른쪽 상단에 있는 프로필을 클릭합니다. API 키 보기를 선택합니다. 그러면 API 키 페이지로 이동합니다.
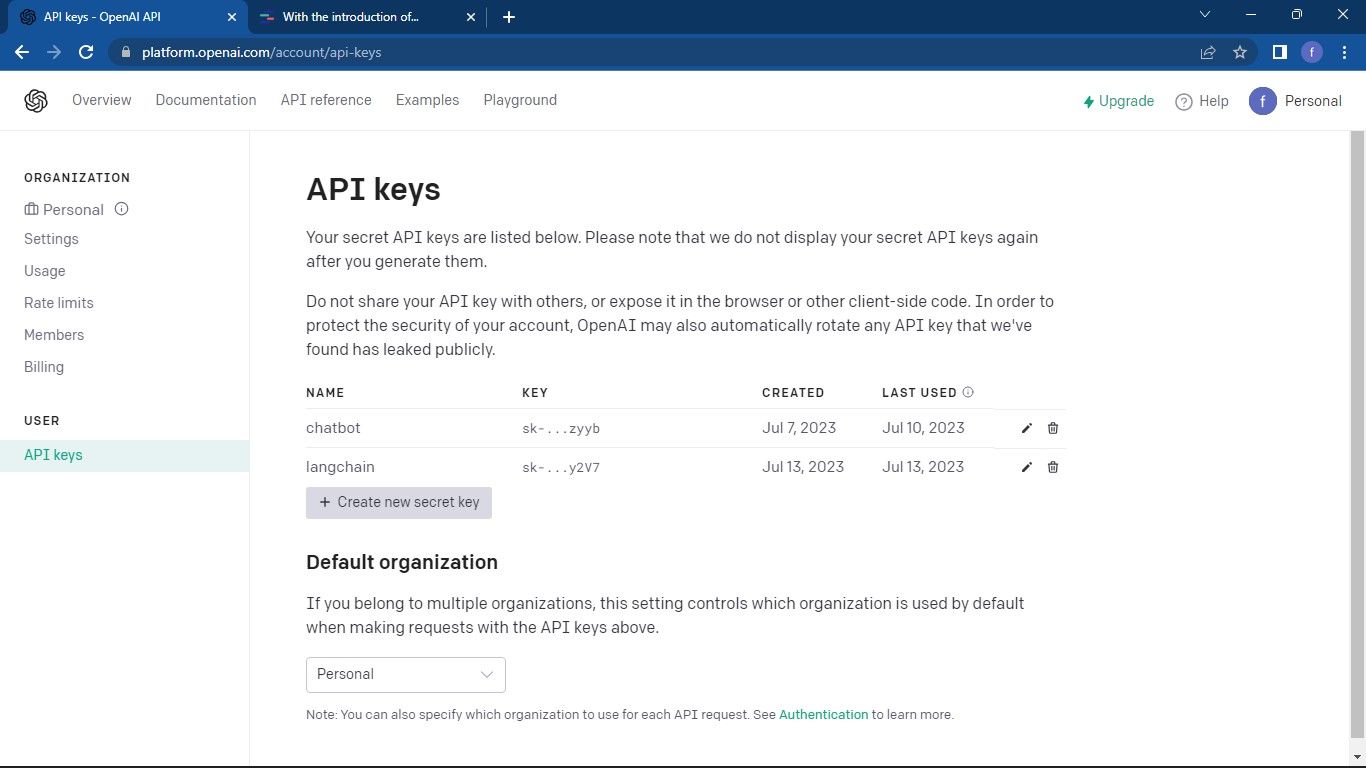
새 비밀 API 키를 생성하려면 API 키 관리 페이지로 이동하여 제공된 ‘새 비밀 키 생성’ 버튼을 클릭하여 새 비밀 키 생성 옵션을 선택합니다.
트위터 서비스에서 사용할 API 키를 생성하려면 키 이름을 입력하고 “비밀 키 생성” 버튼을 누르기만 하면 됩니다. 생성된 후에는 나중에 참조할 수 있도록 정보를 보관하지 않으므로 이 고유 식별자를 안전하게 기록해 두시기 바랍니다. 키를 분실하거나 잊어버리신 경우, 새로운 키를 다시 생성하셔야 서비스를 계속 이용하실 수 있습니다.
전체 코드베이스는 다양한 애플리케이션 및 소프트웨어 개발 프로젝트를 위한 광범위한 프로그래밍 솔루션을 제공하는 GitHub 리포지토리를 통해 액세스할 수 있습니다.
API 키를 손에 들고 원하는 통합 개발 환경(IDE)으로 이동하여 Scikit-LLM 라이브러리의 SKLLMConfig 클래스를 통합합니다. 이 통합을 통해 애플리케이션 내에서 대규모 언어 모델 배포와 관련된 설정을 쉽게 사용자 지정할 수 있습니다.5
from skllm.config import SKLLMConfig
이 코스의 필수 요구 사항인 OpenAI API 키 및 관련 조직 정보를 구성했는지 확인하시기 바랍니다.
# Set your OpenAI API key
SKLLMConfig.set_openai_key("Your API key")
# Set your OpenAI organization
SKLLMConfig.set_openai_org("Your organization ID")
조직 ID와 이름이 동일하지 않습니다. 조직 ID는 조직의 고유 식별자입니다. 조직 ID를 얻으려면 OpenAI 조직 설정 페이지로 이동하여 복사하세요. 이제 Scikit-LLM과 대규모 언어 모델 간의 연결이 설정되었습니다.
Scikit-LLM을 활용하기 위해서는 무료 평가판 OpenAI 계정으로는 한계가 있으므로 종량제 서비스 플랜에 가입해야 합니다. 해당 계정은 사용자가 분당 3건의 요청만 할 수 있도록 제한하고 있어 Scikit-LLM에서 요구하는 수요를 충족시키지 못합니다.
무료 평가판 계정을 사용하려고 하면 텍스트 분석을 수행할 때 다음 메시지와 유사한 오류가 발생할 수 있습니다:

속도 제한에 대해 자세히 알아보려면 로 이동하세요. OpenAI 속도 제한 페이지 을 참조하세요.
LLM을 활용하는 것은 OpenAI에만 국한되지 않으며, 다른 LLM 서비스 제공업체도 고려할 수 있습니다.
필요한 라이브러리 가져오기 및 데이터 세트 로드
분석에 필요한 라이브러리를 가져오는 것부터 시작하겠습니다. 특히, 데이터셋을 쉽게 로드하기 위해 Pandas를 사용해야 합니다. 또한 Scikit-LLM과 Scikit-Learn 모두에서 관련 클래스를 가져오는 것이 필수적입니다.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
특정 데이터 세트에 대한 텍스트 분석을 수행하려면 먼저 해당 데이터 세트를 메모리에 로드해야 합니다. 제공된 코드는 IMDb 영화 데이터셋을 예로 사용하지만, 사용자 정의 데이터셋으로 작업하기 위해 이 코드를 수정할 수 있습니다.
# Load your dataset
data = pd.read_csv("imdb_movies_dataset.csv")
# Extract the first 100 rows
data = data.head(100)
반드시 데이터 세트의 초기 100개 행만 활용해야 하는 것은 아닙니다. 대신 포괄적인 데이터 집합을 사용할 수도 있습니다.
그 후, 데이터에서 특징과 라벨 속성을 분리합니다. 이 프로세스에 따라 데이터 집합을 훈련 및 테스트 하위 집합으로 나눕니다.
# Extract relevant columns
X = data['Description']
# Assuming 'Genre' contains the labels for classification
y = data['Genre']
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
장르 카테고리는 예측하고자 하는 분류 레이블을 포함합니다.
Scikit-LLM을 사용한 제로 샷 텍스트 분류
대규모 언어 모델에는 주석이 달린 데이터에 대한 사전 학습 없이 라벨이 없는 텍스트 콘텐츠를 미리 정해진 분류로 분류하는 제로 샷 텍스트 분류 기능이 있습니다. 이 기능은 모델 학습 단계에서 고려되지 않은 범주로 텍스트를 분류해야 하는 상황에서 매우 유용합니다.
Scikit-LLM을 활용하여 제로 샷 텍스트 분류 작업을 수행하기 위해서는 ZeroShotGPTClassifier 클래스를 사용해야 합니다.
# Perform Zero-Shot Text Classification
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
# Print Zero-Shot Text Classification Report
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))
제공된 데이터를 분석한 결과, 관심 변수들 간에 유의미한 상관관계가 있는 것으로 나타났습니다. 특히, 회사가 직원을 대상으로 종합적인 교육 프로그램을 시행했을 때 판매 수익과 고객 만족도가 증가하는 것을 관찰했습니다.
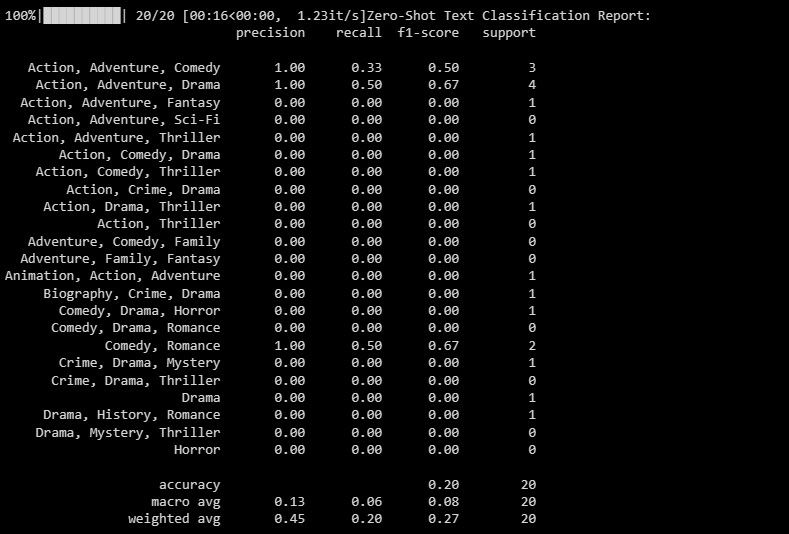
분류 보고서는 모델이 분류하고자 하는 각 라벨과 관련된 정량적 측정값을 제공하며, 정확성과 정밀도 측면에서 성능에 대한 종합적인 평가를 포함합니다.
Scikit-LLM을 이용한 다중 라벨 제로샷 텍스트 분류
강력한 텍스트 분류 도구인 Scikit-LLM은 주어진 텍스트가 여러 범주 분류와 동시에 연관될 수 있는 상황을 처리할 수 있는 혁신적인 솔루션을 제공합니다. 기존의 분류 기법으로는 이러한 복잡성을 처리하는 데 어려움을 겪을 때가 많습니다. 이 기능을 사용하면 하나의 텍스트 인스턴스에 여러 개의 라벨 지정을 할당함으로써 보다 미묘하고 정확한 분석이 가능합니다. 다중 라벨 제로샷 텍스트 분류의 중요성은 단일 텍스트 표본에 여러 개의 설명 태그를 할당하여 분류 프로세스의 전반적인 포괄성과 정확성을 향상시킬 수 있다는 데 있습니다.
멀티라벨제로샷GPTClassifier를 사용하여 각 텍스트 샘플에 적합한 태그를 지정합니다.
# Perform Multi-Label Zero-Shot Text Classification
# Make sure to provide a list of candidate labels
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
# Convert the labels to binary array format using MultiLabelBinarizer
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
# Print Multi-Label Zero-Shot Text Classification Report
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
앞서 언급한 코드는 주어진 텍스트 콘텐츠에 대한 잠재적인 라벨 분류를 설정합니다.
한 남자가 의자에 앉아 책을 읽고 있습니다.
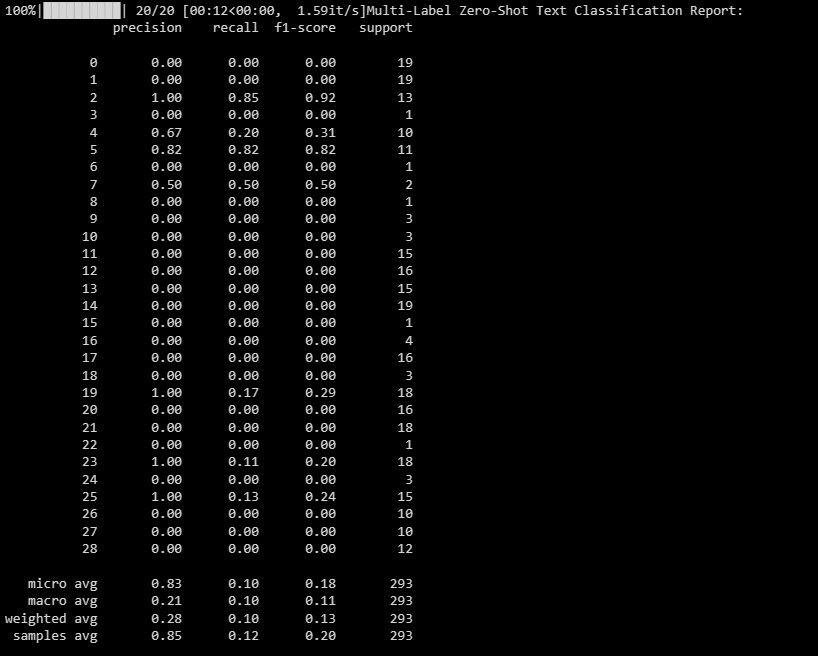
본 문서는 단일 인스턴스 내에서 여러 레이블을 분류하는 능력 측면에서 모델의 성능에 대한 종합적인 분석을 제공합니다. 이 평가는 모든 관련 범주에서 모델 예측의 효율성을 평가하여 향후 성능을 개선하고 전반적인 정확도를 높이는 데 활용할 수 있는 귀중한 통찰력을 제공합니다.
Scikit-LLM을 사용한 텍스트 벡터화
Scikit-LLM은 텍스트 데이터를 머신 러닝 알고리즘이 이해할 수 있는 숫자 형식의 표현으로 변환할 수 있는 GPTVectorizer를 제공합니다. 텍스트 벡터화라고 하는 이 프로세스에는 GPT 모델을 사용하여 텍스트를 고정 차원 벡터로 변환하는 작업이 포함됩니다.
이를 달성하는 한 가지 방법은 용어 빈도-역문서 빈도 접근 방식을 활용하는 것입니다.
# Perform Text Vectorization using TF-IDF
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
# Print the TF-IDF vectorized features for the first few samples
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5]) # Change to X_test_tfidf if you want to print the test set
최근 연구에 따르면 부정적인 뉴스와 사건에 노출된 사람은 그렇지 않은 사람에 비해 불안 증상을 경험할 가능성이 더 높은 것으로 나타났습니다. 이 연구 결과는 부정적인 정보에 대한 노출을 줄이는 것이 불안 장애를 예방하거나 완화하는 데 도움이 될 수 있음을 시사합니다.
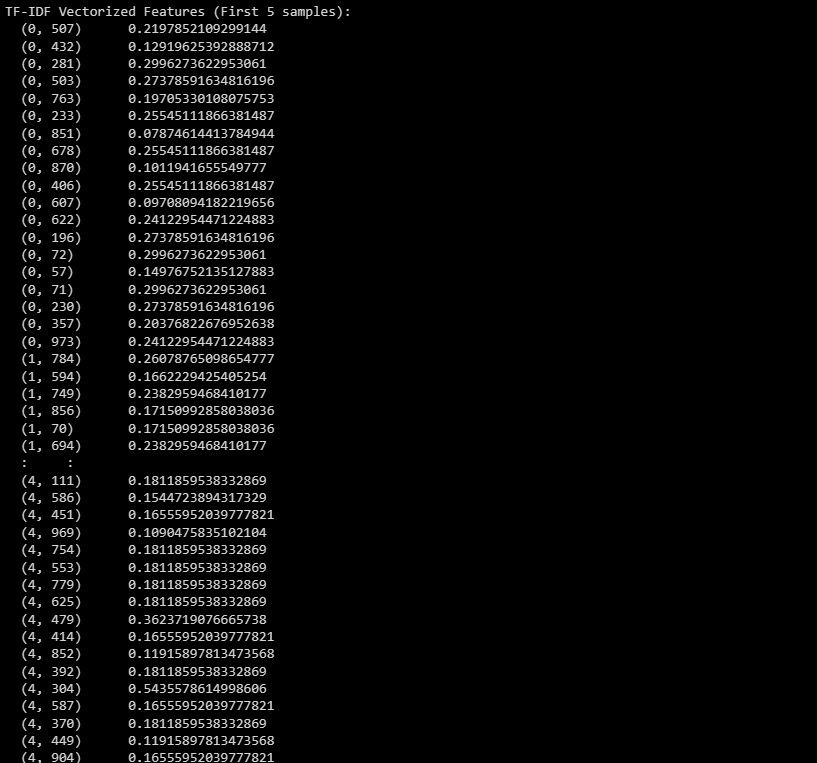
출력은 주어진 데이터 세트 내에서 상위 5개 인스턴스의 용어 빈도 역 문서 빈도(TF-IDF) 표현을 나타냅니다.
Scikit-LLM을 사용한 텍스트 요약
Scikit-LLM의 GPTSummarizer는 GPT 모델을 활용하여 텍스트 요약을 통해 원본 콘텐츠의 필수적인 세부 사항을 유지하는 간결한 요약을 생성합니다.
# Perform Text Summarization
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
재무 및 투자 관리를 위한 포괄적인 솔루션을 제공하도록 설계된 제품으로, 사용자에게 복잡한 재무 프로세스를 간소화하는 직관적인 플랫폼을 제공합니다.
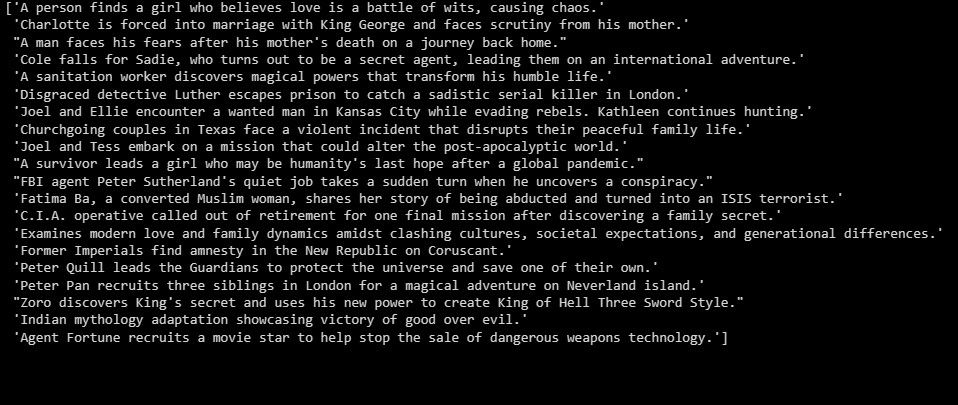
위에 요약된 심사 결과 개요가 제공되었습니다.
LLM을 기반으로 애플리케이션 구축
Scikit-LLM의 기능을 활용하면 강력한 대규모 언어 모델을 활용하여 포괄적인 텍스트 분석을 위한 광범위한 기회를 확보할 수 있습니다. 이러한 첨단 기술의 복잡성을 파악하는 것은 이러한 첨단 혁신을 기반으로 매우 효과적인 솔루션을 구축하는 데 필수적인 고유한 특징과 한계에 대한 통찰력을 얻기 위해 필수 불가결합니다.