파이썬은 데이터를 처리하는 다양하고 효과적인 방법을 제공합니다. 깊게 중첩된 목록, 사전 또는 사용자 정의 객체와 같은 복잡한 데이터 구조를 다룰 때는 얕은 복사본과 깊은 복사본을 구분하는 것이 필수적입니다.
얕은 복사와 깊은 복사를 사용하면 복제본 데이터 구조를 만들 수 있지만 중첩된 데이터를 처리할 때는 동작이 달라집니다.
얕은 복사 사용
얕은 복사는 초기 데이터 엔티티의 기본 아키텍처의 복제본을 생성합니다. 따라서 원본 요소가 동봉된 엔티티로 구성된 경우 두 복사본 모두 이러한 내장된 구성 요소를 참조합니다. 간단히 말해, 항목의 얕은 복제본을 생성하면 깊은 중첩은 복제하지 않고 외부 프레임워크만 복제됩니다.
Python에서 객체의 표면 복제를 실행하려면 복사 모듈의 copy() 함수를 사용하거나 객체에 직접 .copy() 메서드를 적용하여 원본 데이터 구조를 변경하지 않고 복제를 수행할 수 있습니다.
파이썬에서는 목록과 사전을 사용하여 데이터를 효율적으로 조작할 수 있습니다. 예를 들어, 코드 예제를 사용하여 이러한 데이터 구조에 대한 연산을 수행하는 방법을 보여주는 그림을 살펴보겠습니다.
import copy
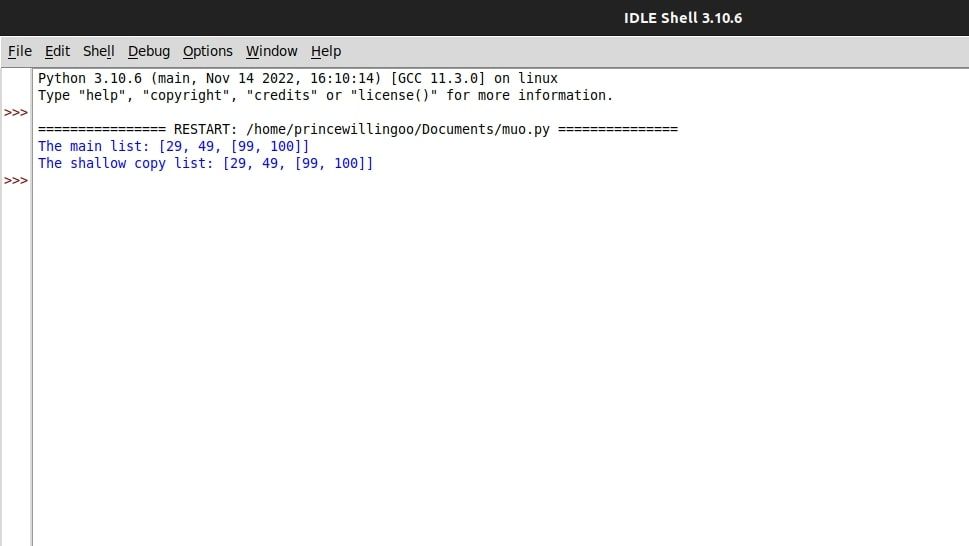
main_list = [29, 49, ["Q", "R"]]
shallow_copy = copy.copy(main_list)
# Modify the nested list
shallow_copy[2][0] = 99
main_list[2][1] = 100
print(f"The main list: {main_list}")
print(f"The shallow copy list: {shallow_copy}")
앞서 언급한 코드에는 두 개의 중첩된 구성 요소로 구성된 데이터 구조가 포함되어 있습니다. 구체적으로 ‘main_list’로 표시되는 기본 컬렉션은 배열과 같은 숫자 값 배열로 구성되며, 일련의 알파벳 문자로 구성된 ‘내부 목록’ 또는 ‘중첩 객체’로 특징지어지는 하위 요소와 함께 구성됩니다. 그 후, ‘copy’ 메서드는 앞서 언급한 ‘main_list’의 복제본을 생성하고, 이 복제본은 ‘shallow_copy’라는 다른 지정 내에 저장됩니다.
shallow\_copy 중첩 목록 내의 요소에 대한 변경 사항은 동일한 참조를 공유하기 때문에 main\_list 내의 요소에도 즉각적인 영향을 미칩니다. 이는 shallow\_copy에 포함된 내부 또는 하위 목록이 메인\_목록에 있는 원본 목록에 대한 참조 링크일 뿐이므로 전자에 적용된 모든 수정 사항이 후자에 자동으로 반영된다는 것을 보여줍니다.
반면, 딥 카피와 원본 목록 모두에서 정수로 표시되는 외부 요소에 대한 변경 사항은 해당 특정 복제본에만 영향을 미칩니다. 앞서 언급한 외부 구성 요소는 개별적인 무결성을 가지므로 단순히 참조 포인터로만 간주해서는 안 됩니다.
import copy
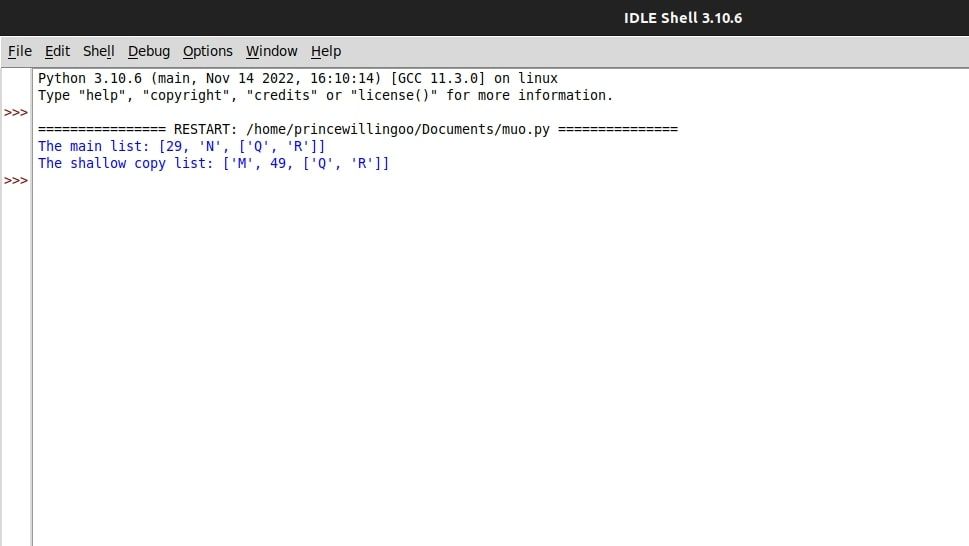
main_list = [29, 49, ["Q", "R"]]
shallow_copy = copy.copy(main_list)
# Modify the outer items
shallow_copy[0] = "M"
main_list[1] = "N"
print(f"The main list: {main_list}")
print(f"The shallow copy list: {shallow_copy}")
두 목록 모두 출력에서 알 수 있듯이 각 요소 간의 상호 의존성이 부족합니다.
사전을 활용할 때도 비슷한 원칙이 적용됩니다.
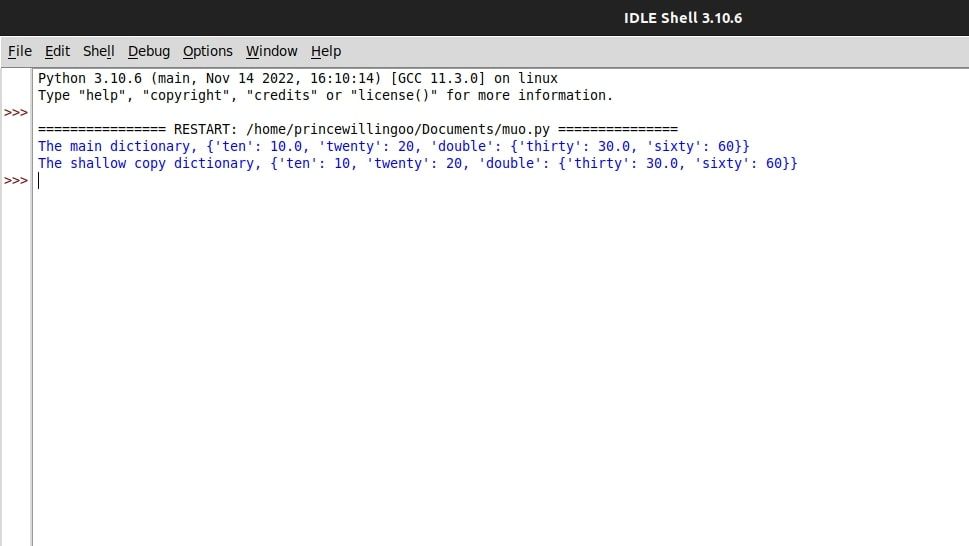
dict1 = {'ten': 10, 'twenty': 20, 'double':{'thirty': 30, 'sixty': 60}}
dict2 = dict1.copy()
# Modify inner and outer elements
dict1['double']['thirty'] = 30.00
dict1['ten'] = 10.00
print(f"The main dictionary, {dict1}")
print(f"The shallow copy dictionary, {dict2}")
dict1 내의 내부 딕셔너리에 적용된 수정 사항은 dict1과 dict2 모두에 영향을 미칩니다. 반대로, dict1의 외부 요소에 대한 변경은 dict1 자체에만 영향을 미칩니다.
심층 복제 사용
심층 복제는 소스 복사본 내의 내부 개체에 대한 참조에 의존하는 대신 모든 포함된 구성 요소와 함께 전체 원본 항목의 독립적인 복제본을 생성합니다. 두 버전은 서로 독립적으로 존재하므로 한 버전을 변경해도 다른 버전에는 아무런 영향을 미치지 않으며, 두 버전 간에 공유되는 정체성이 없습니다.
Python에서 객체의 심층 복제본을 만들려면 `copy` 모듈 내에 있는 내장 `deepcopy()` 함수가 제공하는 기능을 활용하세요.
목록 데이터 구조를 처리하는 예시를 살펴봅시다.
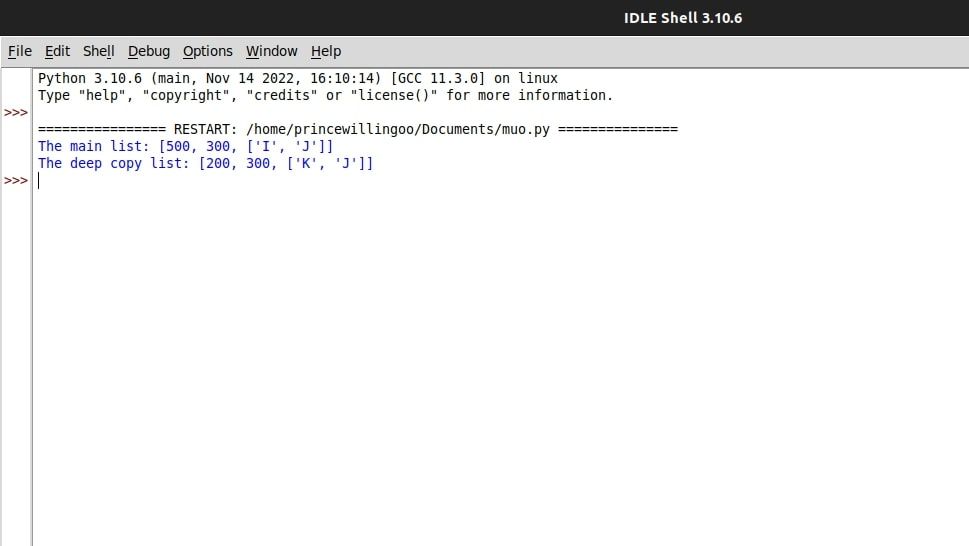
import copy
main_list = [200, 300, ["I", "J"]]
deep_copy = copy.deepcopy(main_list)
# Modify the inner and outer list
deep_copy[2][0] = "K"
main_list[0] = 500
print(f"The main list: {main_list}")
print(f"The deep copy list: {deep_copy}")
이 프로그램의 현재 반복은 원본 목록의 포괄적인 복제본(`deep_copy`라고 함)을 생성하며, 이 복제본은 원본 목록과 독립적으로 작동합니다.
딥 카피의 고유한 특성은 동봉된 내부 목록이나 외부 구성 요소 중 하나를 수정해도 다른 하나에 영향을 미치지 않으며, 이는 두 당사자가 어떤 공통점도 공유하지 않는다는 것을 설명합니다.
사용자 정의 객체로 작업하기
파이썬 클래스를 묘사하고 해당 클래스의 구현을 인스턴스화하는 과정을 통해 개인화된 엔티티를 만들 수 있습니다.
다음은 `Book` 클래스의 기본 인스턴스를 구성하는 예제입니다:
class Book:
def __init__(self, title, authors, price):
self.title = title
self.authors = authors
self.price = price
def __str__(self):
return f"Book(title='{self.title}', author='{self.authors}', \
price='{self.price}')"
파이썬에 내장된 `copy` 모듈을 사용하여 Book 클래스의 인스턴스의 얕은 복사본과 깊은 복사본을 모두 생성합니다.
import copy
# Create a Book object
book1 = Book("How to All Things N Shallow Copy", \
["Bobby Jack", "Princewill Inyang"], 1000)
# Make a shallow copy
book2 = copy.copy(book1)
# Modify the original object
book1.authors.append("Yuvraj Chandra")
book1.price = 50
# Check the objects
print(book1)
print(book2)
본질적으로 책 엔티티의 표면 복제(book2로 지정됨)는 독립적인 인스턴스를 구성하지만, 그 조상(book1로 식별됨)과 공통된 기본 구조를 유지합니다. 따라서 원본의 권위 있는 콘텐츠를 수정하면 두 복제본(책1과 책2) 모두에 영향을 미치지만, 포괄적인 요소(이 경우 가격)를 변경하면 원본 자료(즉, 책1)에만 영향을 미칩니다.
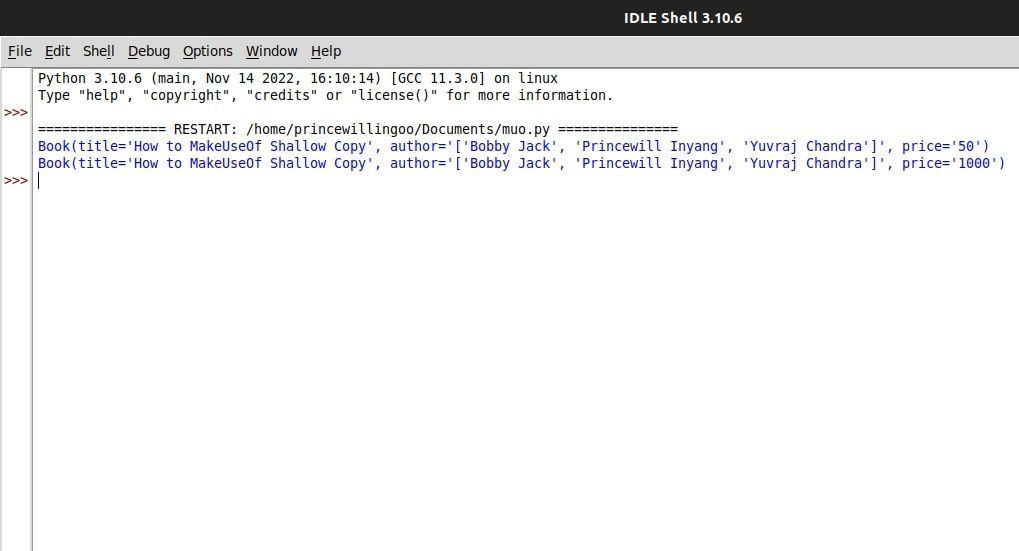
또는 심오한 복제본을 생성하면 그 안에 중첩된 모든 요소의 복제본을 포함하는 초기 엔티티의 자족적인 복제본이 생성됩니다.
# Create a Book object
book1 = Book("Why All Things N Deep Copy?", \
["Bobby Jack", "Yuvraj Chandra"], 5000)
# Make a deep copy
book2 = copy.deepcopy(book1)
# Modify the original object
book1.authors.append("Princewill Inyang")
book1.price = 60
# Check the objects
print(book1)
print(book2)
예제에서 책1과 같은 개체의 심층 복제본을 생성할 때, 이 경우 책2라고 하는 결과 복사본은 원본과 독립적으로 작동하는 별도의 엔티티로 존재합니다.즉, 원본 개체인 책1을 수정해도 복사된 버전인 책2에는 영향을 미치지 않습니다.
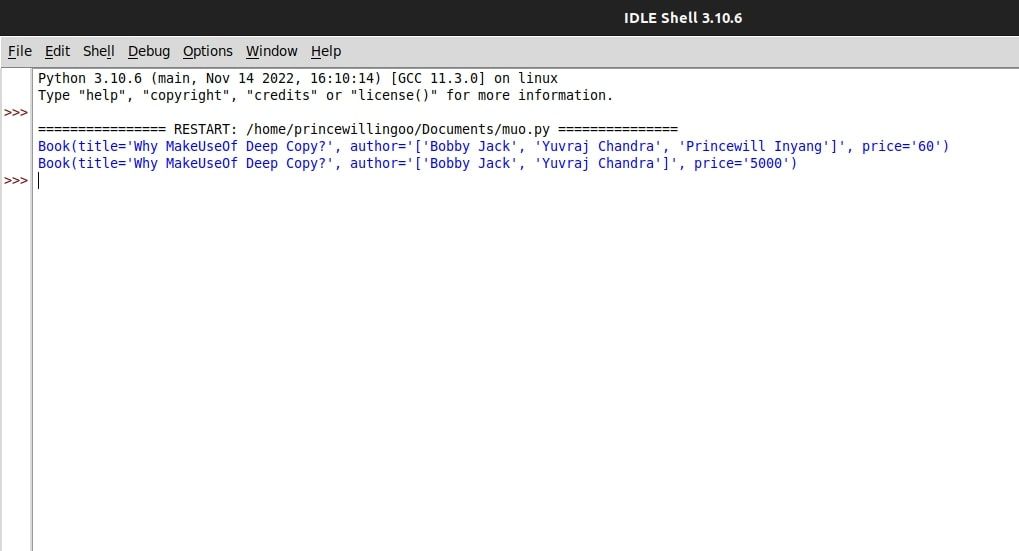
얕은 복사와 깊은 복사의 용도
정보를 효과적으로 처리하는 데 가장 적합한 방법을 결정하려면 깊은 복사와 얕은 복사 기법을 모두 포괄적으로 이해해야 합니다. 다음 예는 각 유형의 복사가 사용될 수 있는 상황을 보여줍니다:
복잡한 항목의 사본을 만들 때 “얕은 복사”를 활용하면 추가 인스턴스화가 필요하지 않으면서도 포함된 하위 개체를 보존하는 데 유리할 수 있습니다. 모든 수준의 중첩을 복제하는 “심층 복사”와 비교할 때, 이 방법은 중첩된 구성 요소에 대한 복제본을 만들 필요가 없으므로 메모리와 시간 모두 효율적인 것으로 입증되었습니다.
초기 인스턴스와 복제된 항목 모두 해당 공통 풀의 혜택을 받더라도 기초에 특정 공유 데이터를 보존하여 엔티티 상태의 표면적인 복제본을 유지합니다.
원래 상태를 유지하면서 개체를 변경하려는 경우 ‘심층 복제본’을 사용하는 것이 좋습니다. 이 방법은 복잡한 구조의 정확한 복제본을 생성하므로 소스 자료에 영향을 주지 않고 개별적으로 수정할 수 있습니다.
복잡한 중첩 데이터 구조의 여러 복제본이 필요한 경우, 특히 재귀적이거나 복잡한 객체 계층 구조가 포함된 경우 딥 카피의 활용이 매우 중요합니다.
성능 및 고려 사항
얕은 복사는 깊게 포함된 객체의 인스턴스를 새로 생성하지 않으므로 깊은 복사와 비교할 때 메모리 사용량을 줄이면서 더 효율적인 성능을 발휘하는 경우가 많습니다. 하지만 이 접근 방식은 복사된 객체 내의 공유 구성 요소에 대한 수정으로 인해 의도하지 않은 결과를 초래할 수 있습니다.
크고 복잡한 데이터 구조가 포함된 경우 재귀를 통해 심층 복사를 생성하면 처리 시간이 느려지고 메모리 사용량이 증가할 수 있습니다. 그럼에도 불구하고 이 접근 방식은 원본과 복사된 객체 간의 완전한 분리를 보장하며, 이는 의도하지 않은 수정이나 결과를 방지하기 위해 섬세한 데이터 작업을 처리할 때 필수적입니다.
데이터에 가장 적합한 복사 옵션
다양한 프로그래밍 언어에서 얕은 복사와 깊은 복사를 활용하는 것은 데이터 조작을 다룰 때 이해해야 할 중요한 측면으로, 이러한 작업으로 인해 발생할 수 있는 의도하지 않은 결과를 피할 수 있기 때문입니다.
얕은 복사와 깊은 복사 방법을 모두 사용하면 데이터 구조를 안전하게 복제할 때 신중한 선택을 할 수 있습니다.데이터에 대한 의미를 파악하면 프로그래밍 코드에서 보다 일관되고 신뢰할 수 있는 결과를 예측할 수 있습니다.