XML은 다양한 애플리케이션에 활용되는 다목적 포맷으로, 그 중 하나는 데이터 보존을 위한 수단으로 사용됩니다. JSON이 주목받기 전에는 XML이 구조화된 정보를 캡슐화, 보관 및 전송하는 주요 방법으로 널리 선호되었습니다.
현대에는 그 보급률이 감소했지만 여전히 간헐적으로 XML을 접할 수 있으므로 XML 작업에 능숙해지는 것이 현명합니다. 이 문서에서는 기본 프로그래밍 언어인 Java를 사용하여 문서 객체 모델(DOM) 애플리케이션 프로그래밍 인터페이스(API)를 활용하여 XML 문서를 열람하고 작성하는 방법을 보여드립니다.
Java에서 XML 처리를 위한 요구 사항
Java SE(표준 버전)에는 다음과 같은 XML 처리와 관련된 다양한 기능으로 구성된 포괄적인 프레임워크인 JAXP(XML 처리를 위한 Java API)가 포함되어 있습니다:
문서 객체 모델에는 요소, 노드 및 속성을 포함한 XML 구성 요소의 조작을 용이하게 하는 클래스 집합이 포함되어 있습니다. 그러나 처리 중에 XML 파일 전체를 메모리에 로드하는 고유한 설계로 인해 DOM API는 광범위한 XML 문서를 처리할 때 최적이 아닙니다.
SAX는 XML용 Simple API의 약자로, XML 문서 처리를 위해 특별히 설계된 프로그래밍 인터페이스입니다. 데이터를 검색하기 전에 전체 문서를 완전히 구문 분석해야 하는 DOM 또는 XPath와 같은 다른 구문 분석 방법과 달리 SAX는 이벤트 기반으로 XML 파일을 읽으므로 텍스트 내에서 특정 트리거가 발생할 때만 정보를 처리합니다. 따라서 다른 방식에 비해 메모리 사용량은 낮지만, 이벤트 기반이라는 특성으로 인해 DOM과 같은 다른 방식보다 작업하기가 더 어려울 수 있습니다.
StAX 또는 XML용 스트리밍 API는 XML 처리 분야에서 가장 최근에 개발된 기술입니다. 이 혁신적인 접근 방식을 사용하면 전체 문서를 동시에 메모리에 로드할 필요 없이 소스에서 직접 스트리밍하여 XML 데이터를 효율적으로 필터링, 조작 및 분석할 수 있습니다. StAX는 이벤트 기반 모델 대신 풀 기반 모델을 사용하지만, 일반적으로 SAX API에 비해 사용자 친화적인 설계로 간주되어 코딩 요구 사항이 덜 복잡합니다.
Java 애플리케이션 내에서 XML(확장 가능한 마크업 언어) 데이터를 처리하려면 이 기능을 용이하게 하는 특정 패키지를 통합해야 합니다. 이러한 패키지는 XML 문서를 구문 분석, 조작 및 생성하기 위한 도구와 메서드를 제공합니다. 이러한 패키지를 활용하면 개발자는 Java 애플리케이션에서 XML 데이터로 효율적으로 작업할 수 있습니다.
import javax.xml.parsers.*;
import javax.xml.transform.*;
import org.w3c.dom.*;
샘플 XML 파일 준비
샘플 코드와 그 이면의 개념을 이해하려면 Microsoft에서 제공하는 이 샘플 XML 파일 을 사용하세요. 다음은 발췌한 내용입니다:
<?xml version="1.0"?>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications
with XML.</description>
</book>
<book id="bk102">
<author>Ralls, Kim</author>
...snipped...
DOM API로 XML 파일 읽기
Java에서 DOM(문서 객체 모델) API로 작업할 때는 일련의 기본 절차를 따라야 XML(확장 가능한 마크업 언어) 파일을 성공적으로 읽고 조작할 수 있습니다. 처음에는 XML 문서를 구문 분석하는 기본 도구 역할을 하는 DocumentBuilder 클래스의 인스턴스를 만들어야 합니다.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
이제 XML 루트 요소(이 경우 “카탈로그” 요소에 해당)부터 시작하여 문서 전체를 메모리 내에 저장하도록 선택할 수 있습니다.
// XML file to read
File file = "<path_to_file>";
Document document = builder.parse(file);
Element catalog = document.getDocumentElement();
결과적으로 루트 엔티티인 카탈로그부터 시작하여 XML 문서 전체를 탐색할 수 있는 권한이 부여됩니다.
DOM API를 사용하여 정보 추출하기
XML 루트 요소가 주어지면 DOM(문서 객체 모델) API를 활용하여 중요한 정보에 액세스할 수 있습니다. 이를 위해 `getChildNodes()` 메서드를 사용하여 루트 요소의 모든 자식 노드를 검색할 수 있습니다. 그러나 이 메서드는 텍스트 및 댓글 노드를 포함한 모든 유형의 자식을 검색한다는 점에 유의해야 합니다. 목적에 따라 원하는 자식 요소만 분리하려면 이러한 불필요한 노드를 필터링해야 합니다.
NodeList books = catalog.getChildNodes();
for (int i = 0, ii = 0, n = books.getLength() ; i < n ; i++) {
Node child = books.item(i);
if ( child.getNodeType() != Node.ELEMENT_NODE )
continue;
Element book = (Element)child;
// work with the book Element here
}
부모 요소 내에서 특정 자식 노드를 찾으려면 원하는 요소를 검색하거나 존재하지 않는 경우 null을 반환하는 정적 메서드를 만들 수 있습니다. 이 프로세스에는 모든 자식 노드의 컬렉션을 가져와서 지정된 이름을 가진 노드를 식별하기 위해 반복하는 과정이 수반됩니다.
static private Node findFirstNamedElement(Node parent,String tagName)
{
NodeList children = parent.getChildNodes();
for (int i = 0, in = children.getLength() ; i < in ; i++) {
Node child = children.item(i);
if (child.getNodeType() != Node.ELEMENT_NODE)
continue;
if (child.getNodeName().equals(tagName))
return child;
}
return null;
}
DOM API는 요소 안에 포함된 개별 텍스트 단위를 TEXT\_NODE 클래스로 분류된 별개의 엔티티로 인식합니다. 텍스트 콘텐츠는 여러 개의 상호 연결된 텍스트 요소로 구성될 수 있으므로 요소의 내용을 효과적으로 검색하려면 특정 처리가 필요합니다:
static private String getCharacterData(Node parent)
{
StringBuilder text = new StringBuilder();
if ( parent == null )
return text.toString();
NodeList children = parent.getChildNodes();
for (int k = 0, kn = children.getLength() ; k < kn ; k++) {
Node child = children.item(k);
if (child.getNodeType() != Node.TEXT_NODE)
break;
text.append(child.getNodeValue());
}
return text.toString();
}
제공된 유틸리티 함수를 활용하여 다양한 도서 목록이 포함된 카탈로그가 포함된 XML 파일에서 데이터를 추출하는 방법을 예로 들어 보겠습니다. 아래 코드 스니펫은 카탈로그 내의 각 개별 출판물에 대한 포괄적인 세부 정보를 표시합니다:
NodeList books = catalog.getChildNodes();
for (int i = 0, ii = 0, n = books.getLength() ; i < n ; i++) {
Node child = books.item(i);
if (child.getNodeType() != Node.ELEMENT_NODE)
continue;
Element book = (Element)child;
ii++;
String id = book.getAttribute("id");
String author = getCharacterData(findFirstNamedElement(child, "author"));
String title = getCharacterData(findFirstNamedElement(child, "title"));
String genre = getCharacterData(findFirstNamedElement(child, "genre"));
String price = getCharacterData(findFirstNamedElement(child, "price"));
String pubdate = getCharacterData(findFirstNamedElement(child, "pubdate"));
String descr = getCharacterData(findFirstNamedElement(child, "description"));
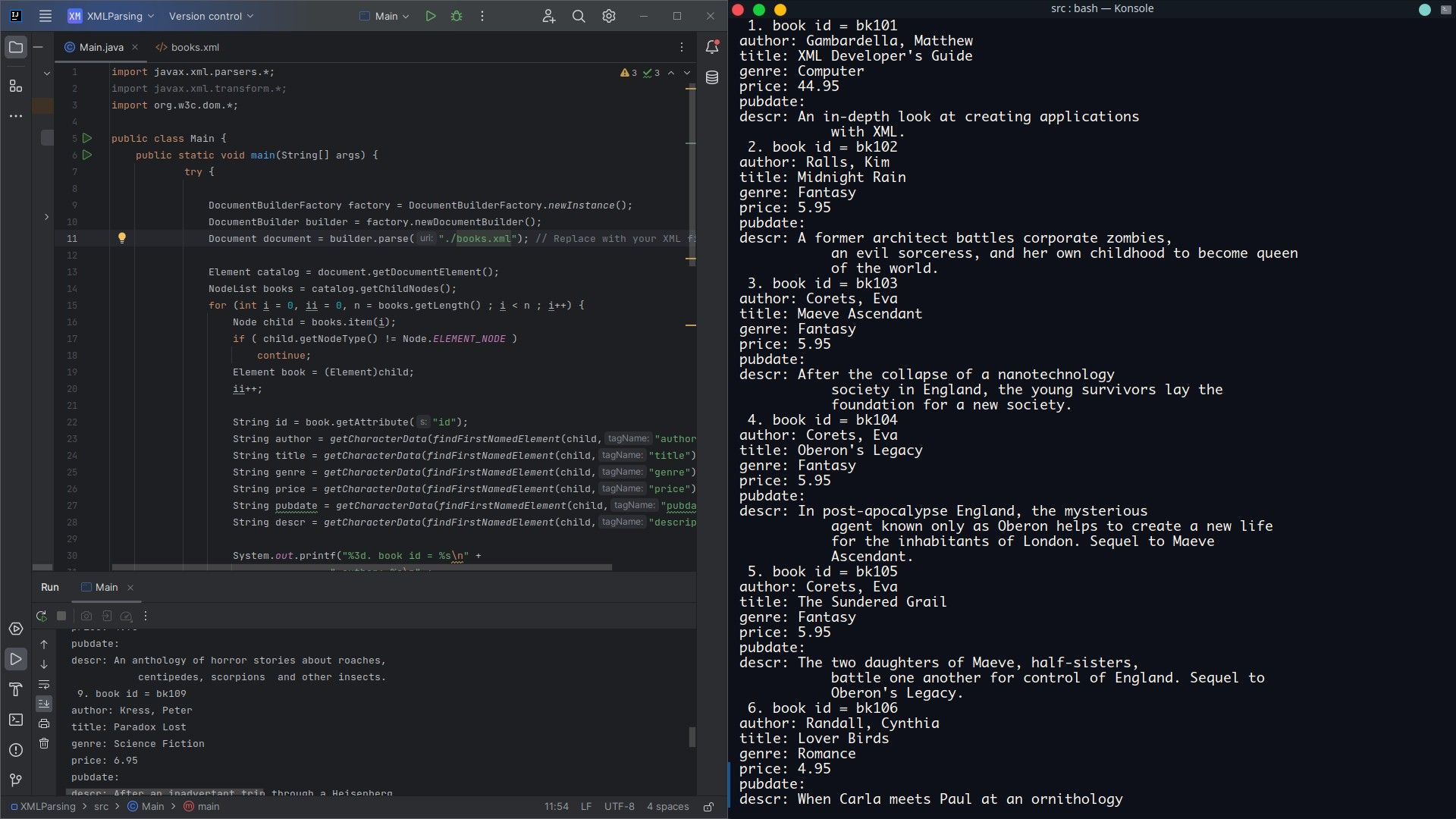
System.out.printf("%3d. book id = %s\n" +
" author: %s\n" +
" title: %s\n" +
" genre: %s\n" +
" price: %s\n" +
" pubdate: %s\n" +
" descr: %s\n",
ii, id, author, title, genre, price, pubdate, descr);
}
제공된 코드는 출력을 생성하기 위해 순차적으로 실행되는 일련의 복잡한 명령어로 구성되어 있습니다. 각 단계는 완료에 필요한 작업과 조건을 자세히 설명하면서 세심하게 정의되어 있습니다.알고리즘은 엄격한 프로토콜을 준수하고 고급 기술을 활용하여 의도한 결과를 얻기 위해 체계적으로 정밀하게 진행됩니다.
이 코드는 XML 문서에서 루트 노드 역할을 하는 카탈로그 요소의 하위 노드를 순회합니다.
특정 도서에 해당하는 모든 개별 하위 노드에 대해 프로그램은 해당 데이터 유형이 ELEMENT\_NODE로 분류되는지 확인합니다. 불일치하는 경우 프로세스는 다음 반복으로 이동합니다.
ELEMENT\_NODE 타입의 자식 노드가 발견되면 (엘리먼트)child는 이를 엘리먼트 객체로 변환합니다.
이 코드는 ‘id’, ‘저자’, ‘제목’, ‘장르’, ‘가격’, ‘출판일’, ‘요약’ 등의 식별자를 포함하여 책 요소와 관련된 포괄적인 특성 및 문학 요소 배열을 검색하기 위해 계속 진행합니다. 그런 다음 Java 언어에 내장된 인쇄 함수, 즉 System.out.printf()를 사용하여 이러한 세부 정보를 표시합니다.
텍스트의 수정된 버전은 다음과 같습니다: “소프트웨어 개발 프로젝트에서 위험을 식별하고 완화하는 것은 어려울 수 있으며, 특히 적절한 문서화나 자동화가 부족한 레거시 시스템으로 작업할 때는 더욱 그렇습니다. 이러한 경우 품질 보증을 보장하기 위해 수동 테스트 기법에 의존해야 할 수도 있습니다.
변환 API를 사용하여 XML 출력 작성
Java 프로그래밍 언어에는 XML 데이터를 다양한 방식으로 조작하고 변경할 수 있는 XML 변환 API라는 기능이 있습니다. 이 기능은 미리 정의된 매개변수를 기반으로 특정 유형의 출력을 생성하는 ‘ID 변환’이라고 하는 기능을 활용하여 사용할 수 있습니다. 이 개념을 설명하기 위해 이전에 제공된 샘플 카탈로그의 컨텍스트에 새 요소를 추가하는 것을 고려해 보겠습니다.
속성 파일이나 관계형 데이터베이스와 같은 외부 소스에서 문학 작품과 관련된 정보(예: 저작자 및 제목)를 검색할 수 있습니다. 다음 속성 파일은 참조용 모델입니다:
id=bk113
author=Jane Austen
title=Pride and Prejudice
genre=Romance
price=6.99
publish_date=2010-04-01
description="It is a truth universally acknowledged, that a single man in possession of a good fortune must be in want of a wife." So begins Pride and Prejudice, Jane Austen's witty comedy of manners-one of the most popular novels of all time-that features splendidly civilized sparring between the proud Mr. Darcy and the prejudiced Elizabeth Bennet as they play out their spirited courtship in a series of eighteenth-century drawing-room intrigues.
먼저 이 문서의 앞부분에 설명된 기술을 사용하여 현재 XML 데이터를 처리합니다:
File file = ...; // XML file to read
Document document = builder.parse(file);
Element catalog = document.getDocumentElement();
Java 프로그래밍 언어에 내장된 속성 클래스를 활용하면 속성 파일에 저장된 정보를 효율적으로 검색하고 처리할 수 있습니다. 이 작업에는 최소한의 코딩 작업만 필요하며 데이터 관리 프로세스를 간소화합니다.
String propsFile = "<path_to_file>";
Properties props = new Properties();
try (FileReader in = new FileReader(propsFile)) {
props.load(in);
}
속성을 로드하면 속성 파일에서 원하는 값을 액세스하고 추출하여 추가할 수 있습니다.
String id = props.getProperty("id");
String author = props.getProperty("author");
String title = props.getProperty("title");
String genre = props.getProperty("genre");
String price = props.getProperty("price");
String publish_date = props.getProperty("publish_date");
String descr = props.getProperty("description");
JavaScript를 사용하여 새로운 `book` 요소를 생성하여 HTML 파일에 추가했습니다.
Element book = document.createElement("book");
book.setAttribute("id", id);
출판물의 개별 구성 요소를 페이지 내에 통합하는 것은 컬렉션에서 필요한 구성 요소 레이블을 구성하고 해당 데이터 포인트를 반복적으로 추가함으로써 효율적으로 실행할 수 있는 복잡하지 않은 프로세스입니다.
List<String> elnames =Arrays.asList("author", "title", "genre", "price",
"publish_date", "description");
for (String elname : elnames) {
Element el = document.createElement(elname);
Text text = document.createTextNode(props.getProperty(elname));
el.appendChild(text);
book.appendChild(el);
}
catalog.appendChild(book);
이제 새로 추가된 “도서” 엔티티를 포함하여 “카탈로그” 구성 요소는 더욱 포괄적인 제품 목록을 자랑합니다. 다음 단계는 이러한 변경 사항을 정확하게 반영하기 위해 업데이트된 버전의 XML 파일 초안을 작성하는 것입니다.
Transformer 모델을 사용하여 XML 문서를 작성하려면 먼저 제공된 코드 스니펫을 실행하여 “Transformer” 유형의 객체를 인스턴스화해야 합니다:
TransformerFactory tfact = TransformerFactory.newInstance();
Transformer tform = tfact.newTransformer();
tform.setOutputProperty(OutputKeys.INDENT, "yes");
tform.setOutputProperty("{http://xml.apache.org/xslt}indent-amount", "3");
`setOutputProperty()` 메서드를 사용하여 생성된 출력에 대해 원하는 들여쓰기 수준을 지정할 수 있습니다.
변환 프로세스를 실행하기 위해 출력은 `System.out` 스트림에 표시됩니다.
tform.transform(new DOMSource(document), new StreamResult(System.out));
출력 내용을 파일에 저장하려면 다음 방법을 활용하십시오.
tform.transform(new DOMSource(document), new StreamResult(new File("output.xml")));
Java 프로그래밍 언어를 사용하여 XML(확장 가능한 마크업 언어) 파일에 대한 읽기 및 쓰기 작업을 성공적으로 수행하려면 적절한 클래스 또는 패키지의 인스턴스를 생성하고 필요한 매개 변수를 구성하고 원하는 파일의 구조를 정의한 다음 해당되는 경우 최종적으로 변경 사항을 저장하는 일련의 단계를 수행해야 합니다.
이제 Java로 XML 파일을 읽고 쓰는 방법을 알았습니다
Java를 사용하여 XML(확장 가능한 마크업 언어)을 구문 분석하고 조작하는 데 능숙해지는 것은 실제 애플리케이션에 자주 요구되는 필수 능력입니다. 특히 문서 객체 모델(DOM)과 트랜스포머 API는 상당한 유용성을 제공합니다.
웹 애플리케이션이나 웹사이트를 위한 클라이언트 측 스크립트를 만들려는 개발자에게는 DOM(문서 객체 모델)에 대한 포괄적인 이해가 중요합니다. DOM의 인터페이스는 Java 및 JavaScript를 비롯한 다양한 프로그래밍 언어에 걸쳐 표준화되어 있어 선호하는 언어에 관계없이 일관된 코딩 작업을 수행할 수 있습니다.