디지털 콘텐츠의 보급이 증가함에 따라 이러한 자료를 무단 복제 및 도용으로부터 보호하는 것이 무엇보다 중요해졌습니다. 표절 탐지 소프트웨어 애플리케이션을 구현하면 교육자는 학생의 제출물을 평가하고, 연구 기관은 학술 출판물을 면밀히 조사하며, 창작 전문가는 자신의 독점 아이디어를 도용하는 사례를 식별할 수 있습니다.
표절 감지 소프트웨어를 개발하면 염기서열 정렬, 파일 처리 및 사용자 인터페이스 설계에 대한 심층적인 이해가 가능합니다. 또한 자연어 처리 방법을 탐구함으로써 애플리케이션의 기능을 더욱 개선할 수 있습니다.
Tkinter와 Difflib 모듈
플랫폼에 구애받지 않고 쉽게 접근할 수 있는 도구인 Tkinter를 Difflib 모듈과 함께 활용하면 표절 탐지 시스템 개발을 용이하게 할 수 있습니다.
Difflib 모듈은 파이썬 표준 라이브러리의 필수 구성 요소로, 문자열, 목록, 파일 등 다양한 시퀀스 유형의 비교를 용이하게 하도록 설계된 포괄적인 클래스와 함수를 제공합니다. 개발자는 이 다재다능한 리소스를 활용하여 자동 텍스트 수정, 간소화된 버전 관리 시스템, 간결한 콘텐츠 요약과 같은 작업을 포괄하는 혁신적인 애플리케이션을 만들 수 있습니다.
Python을 사용하여 표절 감지기를 구축하는 방법
Python을 활용하여 표절 감지 도구를 구축하기 위한 전체 코드베이스는 이 Github 리포지토리에서 찾을 수 있습니다.
임포트 문을 사용하여 필요한 모듈을 통합합니다. 두 개의 매개변수, 즉 항목과 텍스트 위젯을 받아들이는 “load\_file\_or\_display\_contents”라는 제목의 함수를 작성합니다. 이 메서드의 목적은 텍스트 파일의 콘텐츠를 검색하여 사용자가 열람할 수 있도록 텍스트 위젯 내에 표시하는 것입니다.
`get()` 함수를 사용하여 파일 경로를 검색합니다. 사용자가 아무런 입력을 제공하지 않은 경우 `askOpenFilename()` 메서드를 사용하여 표절 검사에 적합한 파일을 선택할 수 있는 파일 대화 상자를 호출합니다. 사용자가 파일 경로를 선택하도록 선택한 경우, 이전에 입력한 내용을 처음부터 끝까지 모두 지우고 선택한 경로로 대체합니다.
import tkinter as tk
from tkinter import filedialog
from difflib import SequenceMatcher
def load_file_or_display_contents(entry, text_widget):
file_path = entry.get()
if not file_path:
file_path = filedialog.askopenfilename()
if file_path:
entry.delete(0, tk.END)
entry.insert(tk.END, file_path)
지정된 파일을 읽기 전용 모드로 열어 콘텐츠를 검색한 후 ‘텍스트’ 변수 내에 저장하세요. 그런 다음 텍스트 위젯의 현재 내용을 지우고 마지막으로 파일에서 이전에 가져온 데이터를 텍스트 위젯에 삽입하여 표시합니다.
with open(file_path, 'r') as file:
text = file.read()
text_widget.delete(1.0, tk.END)
text_widget.insert(tk.END, text)
본 과제에서는 Python의 Difflib 라이브러리를 사용하여 두 텍스트를 비교하는 정교한 방법을 구현하는 것입니다. 이 기법은 텍스트 간의 유사성을 백분율로 평가하는 데 사용됩니다. 이 프로세스는 Difflib의 SequenceMatcher() 클래스를 활용하는 “compare\_text()”라는 메서드를 정의하는 것으로 시작됩니다. 사용자 지정 비교 함수를 None으로 설정하면 기본 비교가 활성화되어 시퀀스 유사성을 효율적으로 평가할 수 있습니다. 마지막으로 원하는 텍스트를 입력 매개변수로 전달하면 분석이 시작됩니다.
“비율 방법”을 사용하여 유사도의 소수점 표현을 얻으면, 유사도의 비율을 실수 형식으로 계산하는 데 사용할 수 있습니다. “get\_opcodes()” 함수를 사용하여 일치하는 텍스트 세그먼트를 강조하는 데 사용할 수 있는 연산 모음을 획득하고 유사도 비율과 함께 반환합니다.
def compare_text(text1, text2):
d = SequenceMatcher(None, text1, text2)
similarity_ratio = d.ratio()
similarity_percentage = int(similarity_ratio * 100)
diff = list(d.get_opcodes())
return similarity_percentage, diff
다음은 제공한 JavaScript 코드에 대한 Python 구현 예제입니다: “`python def show_similarity(text1, text2): # get() 메서드를 사용하여 텍스트 상자에서 텍스트 추출 text1 = entry1.get() text2 = entry2.get() # compare_text() 함수를 사용하여 텍스트 비교 유사도 = compare_text(text1, text2) # 유사도를 백분율로 표시 label1.config(text=f’유사도: {int(유사도 * 100)}%’) # 이전 하이라이트 지우기 label1.config(state=”normal”) label2.config(state=”normal”)
def show_similarity():
text1 = text_textbox1.get(1.0, tk.END)
text2 = text_textbox2.get(1.0, tk.END)
similarity_percentage, diff = compare_text(text1, text2)
text_textbox_diff.delete(1.0, tk.END)
text_textbox_diff.insert(tk.END, f"Similarity: {similarity_percentage}%")
text_textbox1.tag_remove("same", "1.0", tk.END)
text_textbox2.tag_remove("same", "1.0", tk.END)
연산 문자 문자열, 초기 시퀀스의 시작 위치, 기본 시퀀스의 끝, 보조 시퀀스의 시작, 보조 시퀀스의 종료.
치환, 생략, 삽입 또는 동일. 이러한 지정은 두 개의 개별 시퀀스에 포함된 텍스트의 일부가 한 세그먼트를 다른 세그먼트로 대체해야 하는 불일치를 보이거나 특정 구절이 단일 시퀀스 내에서만 나타나고 다른 시퀀스에는 나타나지 않을 때 트리거됩니다.
초기 텍스트와 수정된 텍스트에 서로 다른 세그먼트가 포함된 경우 “삽입”이 결과로 지정됩니다. 반대로 두 시퀀스 모두 주어진 세그먼트에 대해 동일한 콘텐츠를 가지고 있으면 “동일”이 지정됩니다. 이러한 결과는 적절한 변수에 저장됩니다. 연산 코드가 변경되지 않은 경우 해당 태그가 텍스트 시퀀스에 추가됩니다.
for opcode in diff:
tag = opcode[0]
start1 = opcode[1]
end1 = opcode[2]
start2 = opcode[3]
end2 = opcode[4]
if tag == "equal":
text_textbox1.tag_add("same", f"1.0+{start1}c", f"1.0+{end1}c")
text_textbox2.tag_add("same", f"1.0+{start2}c", f"1.0+{end2}c")
적절한 제목을 지정하여 Tkinter 메인 창을 시작한 다음 그 안에 포함 프레임을 만듭니다. 각 면에 적절한 테두리 간격을 사용하여 내부 공간을 고르게 분배합니다. 텍스트 1과 텍스트 2를 각각 표시하기 위해 두 개의 개별 레이블 구성 요소를 지정합니다.각각의 상위 요소와 표시되는 콘텐츠를 결정합니다.
세 개의 항목이 있는 텍스트 위젯을 만들고 첫 번째 항목은 참조 텍스트로, 두 번째 항목은 비교할 새 텍스트를 나타냅니다. 비교 결과를 표시할 다른 텍스트 위젯을 만듭니다. 첫 번째 텍스트 위젯의 앵커 속성을 “nw”(북서쪽)로 설정하여 프레임의 왼쪽 상단 모서리와 정렬되도록 합니다.
root = tk.Tk()
root.title("Text Comparison Tool")
frame = tk.Frame(root)
frame.pack(padx=10, pady=10)
text_label1 = tk.Label(frame, text="Text 1:")
text_label1.grid(row=0, column=0, padx=5, pady=5)
text_textbox1 = tk.Text(frame, wrap=tk.WORD, width=40, height=10)
text_textbox1.grid(row=0, column=1, padx=5, pady=5)
text_label2 = tk.Label(frame, text="Text 2:")
text_label2.grid(row=0, column=2, padx=5, pady=5)
text_textbox2 = tk.Text(frame, wrap=tk.WORD, width=40, height=10)
text_textbox2.grid(row=0, column=3, padx=5, pady=5)
GridLayoutManager를 사용하여 행과 열이 있는 그리드에 이러한 모든 구성 요소를 배치하고 각 요소를 해당 행과 열 내에 배치합니다. Packer 위젯을 활용하여 화면에서 원하는 위치에 “비교” 버튼과 TextTextBoxDiff 위젯을 배치합니다. 또한 최적의 레이아웃을 위해 필요에 따라 적절한 양의 패딩을 적용합니다.
file_entry1 = tk.Entry(frame, width=50)
file_entry1.grid(row=1, column=2, columnspan=2, padx=5, pady=5)
load_button1 = tk.Button(frame, text="Load File 1", command=lambda: load_file_or_display_contents(file_entry1, text_textbox1))
load_button1.grid(row=1, column=0, padx=5, pady=5, columnspan=2)
file_entry2 = tk.Entry(frame, width=50)
file_entry2.grid(row=2, column=2, columnspan=2, padx=5, pady=5)
load_button2 = tk.Button(frame, text="Load File 2", command=lambda: load_file_or_display_contents(file_entry2, text_textbox2))
load_button2.grid(row=2, column=0, padx=5, pady=5, columnspan=2)
compare_button = tk.Button(root, text="Compare", command=show_similarity)
compare_button.pack(pady=5)
text_textbox_diff = tk.Text(root, wrap=tk.WORD, width=80, height=1)
text_textbox_diff.pack(padx=10, pady=10)
라이언 홈즈 , Hootsuite의 CEO는 2020년에 이렇게 말했습니다: “소셜 미디어가 비즈니스 전략의 일부가 아니라면 다음을 놓치고 있는 것입니다.
text_textbox1.tag_configure("same", foreground="red", background="lightyellow")
text_textbox2.tag_configure("same", foreground="red", background="lightyellow")
`mainloop()` 함수는 Python이 닫힐 때까지 GUI와의 사용자 상호 작용을 모니터링하는 역할을 하는 Tkinter 이벤트 루프를 활성화하도록 지시합니다.
root.mainloop()
당면한 과제는 학술 논문이나 온라인 콘텐츠와 같은 다양한 텍스트 소스에서 표절 사례를 식별할 수 있는 프로그램을 만드는 것입니다. 이를 위해 데이터를 분석하고 조작할 수 있는 다양한 도구를 제공하는 Python 프로그래밍 언어를 사용할 것입니다. 첫 번째 단계는 원본 소스 자료와 표절이 의심되는 버전의 사본을 모두 확보하는 것입니다. 일단 확보된 문서는 문서 간의 유사성을 식별하도록 설계된 일련의 알고리즘을 통해 처리됩니다. 유사성이 충분히 감지되면 소프트웨어는 해당 문서에 표절된 콘텐츠가 포함되어 있을 가능성이 있는 것으로 플래그를 지정합니다. 이 시점에서 실제 표절이 발생했는지 여부를 확인하기 위해 전문가가 추가 조사를 수행할 수 있습니다.
표절 탐지기의 출력 예
프로그램을 실행하면 두 개의 텍스트 상자가 포함된 인터페이스가 표시됩니다. “파일 1 로드” 버튼을 클릭하면 비교할 문서를 선택할 수 있는 파일 선택 대화 상자가 나타납니다. 선택이 완료되면 선택한 콘텐츠가 첫 번째 텍스트 상자에 자동으로 렌더링됩니다. 마찬가지로 파일 경로를 입력하고 “파일 2 로드” 옵션을 선택하면 두 번째 텍스트 상자에 다른 문서를 로드할 수 있습니다. “비교” 버튼을 클릭하면 프로그램이 두 문서 간의 유사도를 계산하여 두 텍스트 상자에서 100% 일치하는 세그먼트를 강조 표시합니다.
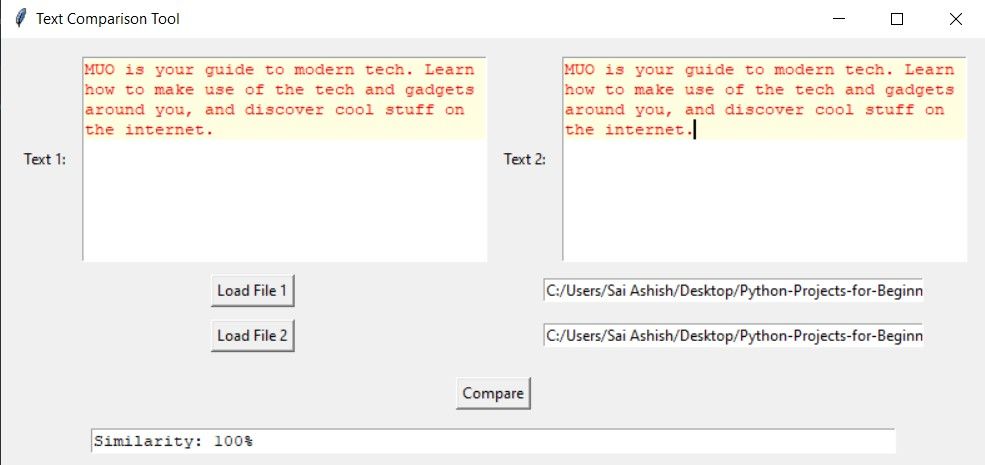
텍스트 상자 중 하나에 항목을 추가하고 “비교”를 클릭하면 소프트웨어가 나머지 콘텐츠는 무시하고 해당 구절에 주의를 기울입니다.
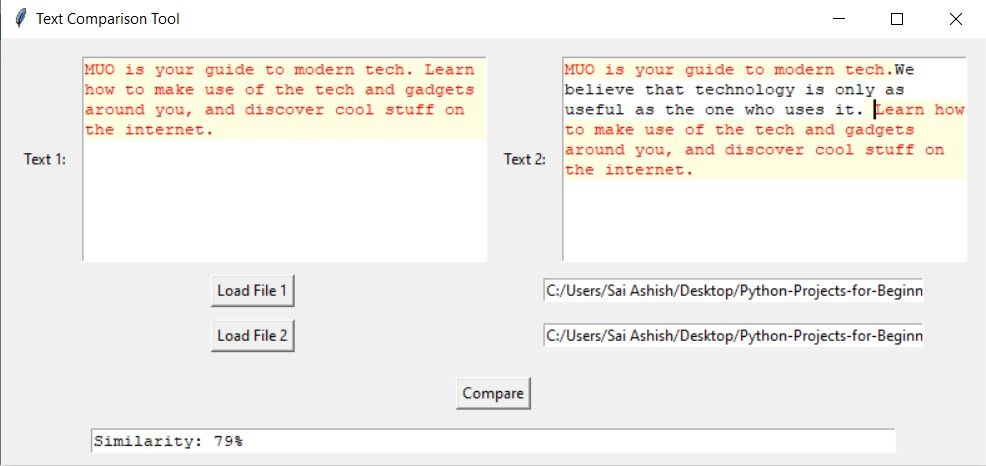
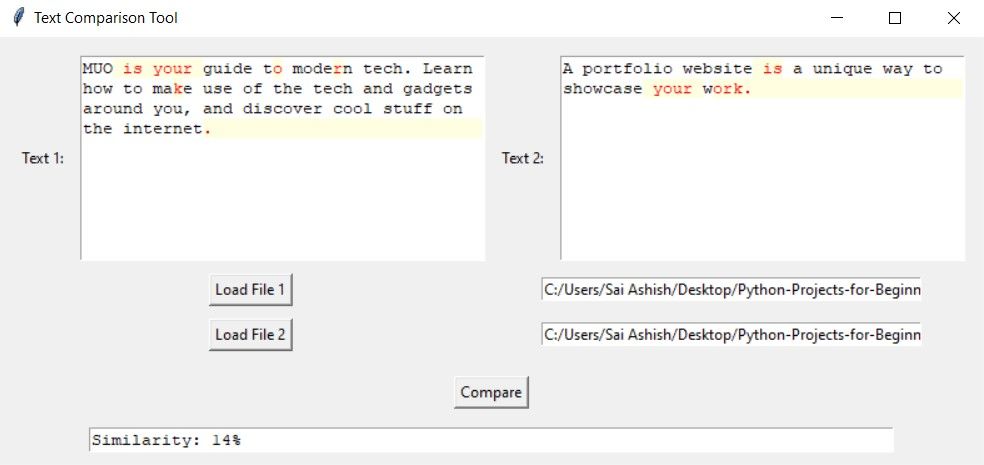
두 텍스트 사이에 일치하는 부분이 거의 없거나 전혀 없는 경우, 소프트웨어는 유사도가 비교적 낮은 특정 문자 또는 구문을 표시할 수 있습니다.
표절 감지를 위해 NLP 사용
Difflib은 텍스트 비교에서 강력한 성능을 발휘하지만 사소한 변경에 민감하고 문맥 이해력이 제한적이며 광범위한 구절에 적용할 경우 만족스러운 결과를 제공하지 못하는 경우가 많습니다. 이에 대한 대안으로 텍스트의 의미 검사를 가능하게 하고, 의미적으로 관련된 특징을 해명하며, 문맥 중심의 지능을 부여하는 자연어 처리의 영역을 살펴볼 수 있습니다.
또한 다양한 언어적 맥락에 맞게 모델을 조정하고 편의성을 위해 최적화하여 성능을 향상시킬 수 있습니다. 표절을 탐지하는 데 사용할 수 있는 방법에는 자카드 유사도, 코사인 유사도, 단어 임베딩, 잠재 시퀀스 분석, 시퀀스 간 모델 등이 있습니다.