중복 레코드는 다양한 형식의 데이터에서 어디에나 존재하며, 중복 레코드의 존재는 웹 기반 데이터든 방대한 양의 판매 데이터든 관계없이 수행되는 모든 분석의 정확성에 큰 영향을 미칠 수 있습니다.
구조화된 쿼리 언어(SQL)를 사용하여 숫자 정보를 처리하고 축적된 데이터 집합에 대한 광범위한 쿼리를 실행하는 경우, SQL 중복 처리에 대한 이 글이 만족스러운 경험이 될 수 있습니다.
SQL에서 중복 항목을 관리할 때 다음과 같은 몇 가지 기술을 사용할 수 있습니다:
함수별 그룹을 사용하여 중복 항목 수 계산
구조화된 쿼리 언어(SQL)는 데이터 분석을 용이하게 하는 수많은 기능을 포함하는 복잡한 프로그래밍 언어입니다. SQL의 집계 함수에 대한 광범위한 지식이 있으면 특정 기준에 따라 정보를 구성하는 기본 도구 역할을 하는 함수별 그룹의 중요성을 이해할 수 있습니다.
기본적인 SQL 명령 중 하나인 함수별 그룹은 합계, 카운트, 평균 등 다양한 집계 함수를 함수별 그룹과 함께 사용하여 행 단위의 고유한 값을 얻을 수 있으므로 여러 레코드를 관리하는 데 특히 유용합니다.
현재 상황에 따라 ‘그룹화 기준’ 함수를 활용하면 단일 열 또는 여러 열에 걸쳐 중복된 항목을 식별하는 데 도움이 될 수 있습니다.
a. 단일 열에서 중복 항목 수 계산
각각 제품 식별 및 각 제품의 주문 수에 관한 정보를 포함하는 “ProductID” 및 “Orders”로 레이블이 지정된 두 개의 열이 포함된 테이블 형식 데이터 집합이 있다고 가정해 봅시다.
| 제품ID | 주문 |
| 2 | 7 |
| 2 | 8 |
| 2 | 10 |
| 9 | 6 |
| 10 | 1 |
| 10 | 5 |
| 12 | 5 |
| 12 | 12 |
| 12 | 7 |
| 14 | 1 |
| 14 | 1 |
| 47 | 4 |
| 47 | 4 |
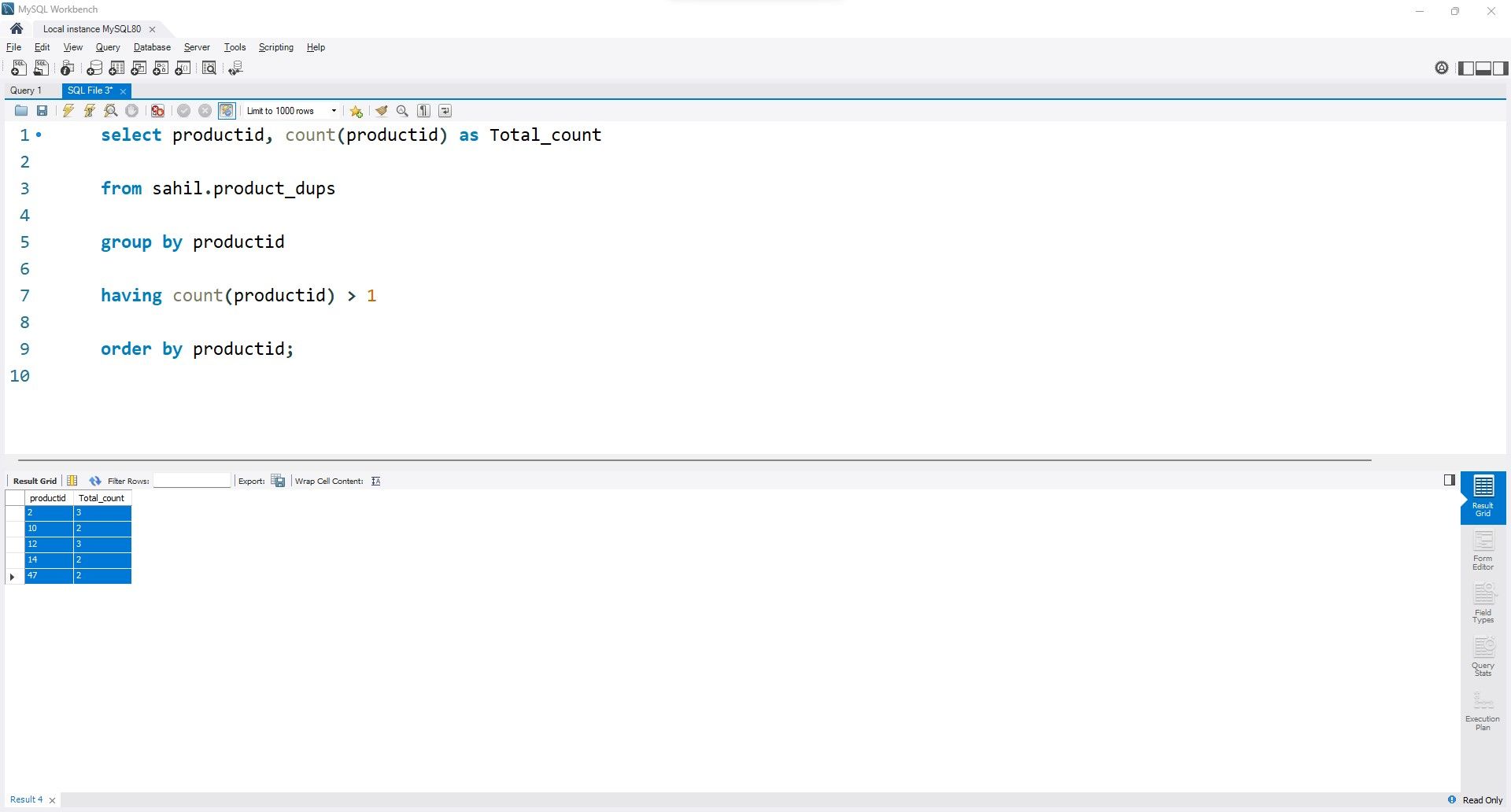
유사한 제품 ID를 식별하기 위해, 다음과 같이 그룹화 함수를 HAVING 절과 함께 사용하여 집계된 데이터를 분석할 수 있습니다:
select productid, count(productid) as Total_count
from sahil.product_dups
group by productid
having count(productid) > 1
order by productid;
ProductID 열 내에서 반복 발생 횟수를 표시하는 원하는 출력을 생성하려면 먼저 최종 결과에 포함할 열을 지정해야 합니다.
초기 섹션에서 select 문 내에서 ProductID 열의 식별자를 지정합니다. 이는 구조화된 쿼리 언어(SQL)가 조회의 목적을 이해할 수 있도록 하기 위한 것입니다.
이제 “from” 절을 활용하여 소스 테이블을 지정해 보겠습니다. “count”는 집계 함수이므로 비슷한 값의 레코드를 모두 수집하려면 “group by” 함수를 사용해야 합니다.
카운트를 필터링하고 해당 열에서 두 번 이상 발생하는 값을 표시하여 ProductID 열 내의 DuplicateValues를 식별하는 것이 목적이라는 점에 유의하시기 바랍니다. 이는 집계된 데이터를 필터링하기 위해 HAVING 절을 활용하여 달성할 수 있으며, 앞서 언급한 조건, 즉 count(ProductID)>1을 사용하여 원하는 결과를 얻을 수 있습니다.
마지막 단계는 order by 절을 사용하여 최종 결과를 오름차순으로 정렬하는 것입니다.
b. 여러 열의 중복 개수 계산
여러 SQL 쿼리를 공식화하지 않고 여러 열에 걸쳐 반복되는 항목을 열거하고자 할 때 앞서 언급한 코드를 약간 조정하여 사용할 수 있습니다. 예를 들어, 여러 열을 연결하여 반복되는 행을 표시하려는 경우 다음 코드를 활용할 수 있습니다:
select productid, orders, count(*) as Total_count
from sahil.product_dups
group by productid, orders
having count(productid) > 1
order by productid;
출력에 두 개의 행만 표시되는 것을 확인할 수 있습니다.조회를 조정하고 선택 표현식 내에서 두 열의 참조를 통합하여 중복된 값을 가진 일치하는 행의 집계를 얻어야 합니다.
열 내에서 반복되는 특정 값이 아닌 중복된 행에 대한 정보를 얻으려면 “count(column)” 함수 대신 “count(\*)” 함수를 사용해야 합니다. 이 함수는 테이블의 모든 행을 샅샅이 뒤져서 특정 열 내에서 반복되는 단일 값만 찾는 것이 아니라 중복 데이터의 인스턴스를 찾습니다.
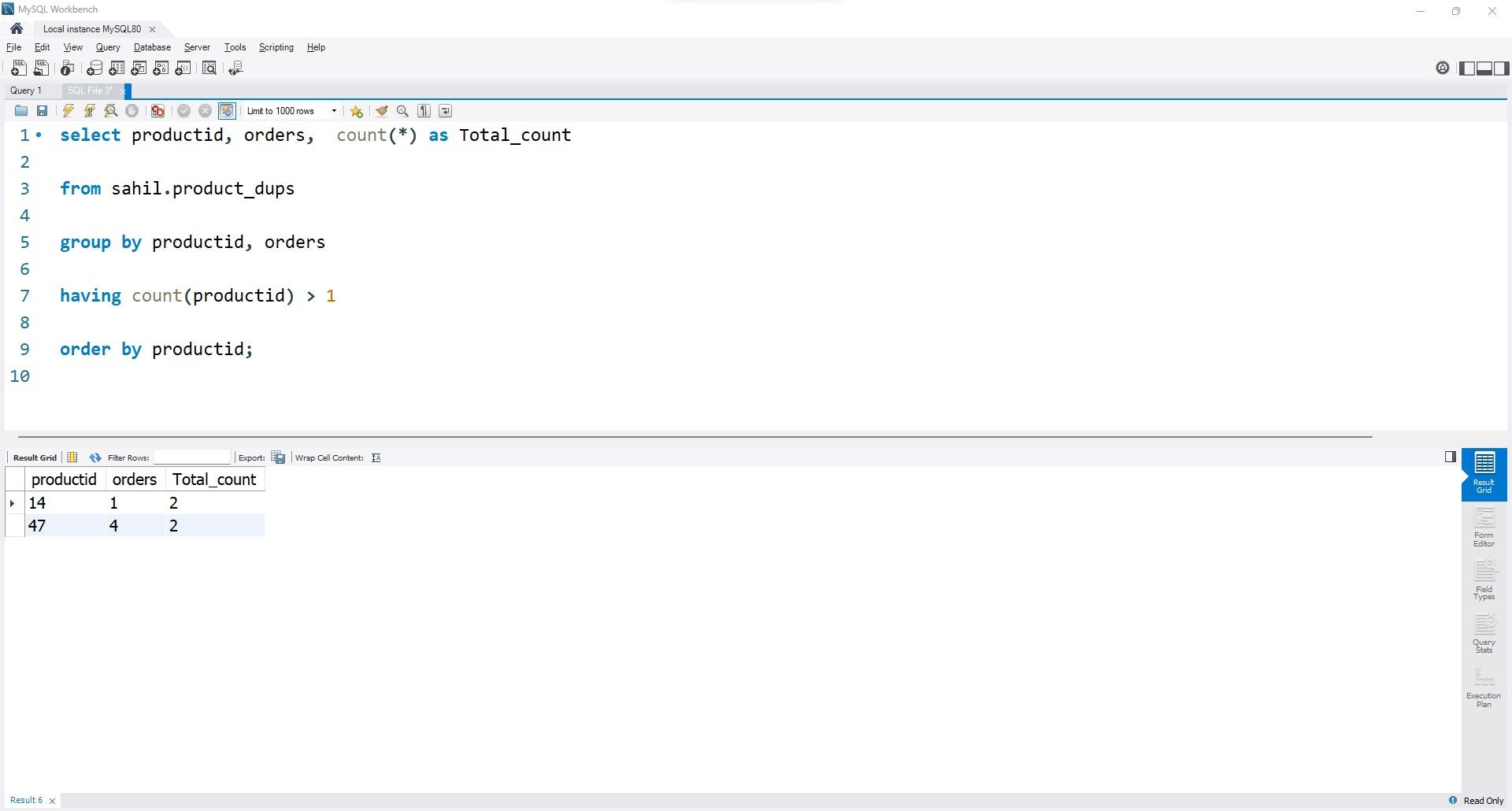
제품 ID가 14와 47인 두 행은 주문 값이 동일하므로 모두 표시됩니다.
row_number() 함수로 중복 플래그 지정
row\_number() 함수를 GROUP BY 절 및 HAVING 절과 함께 사용하면 테이블 내에서 중복 레코드를 식별하고 표시하는 대체 방법이 될 수 있습니다. 이 접근 방식은 효율적인 쿼리 처리를 용이하게 하는 데 중요한 역할을 하는 SQL 창 함수의 영역에 속합니다.
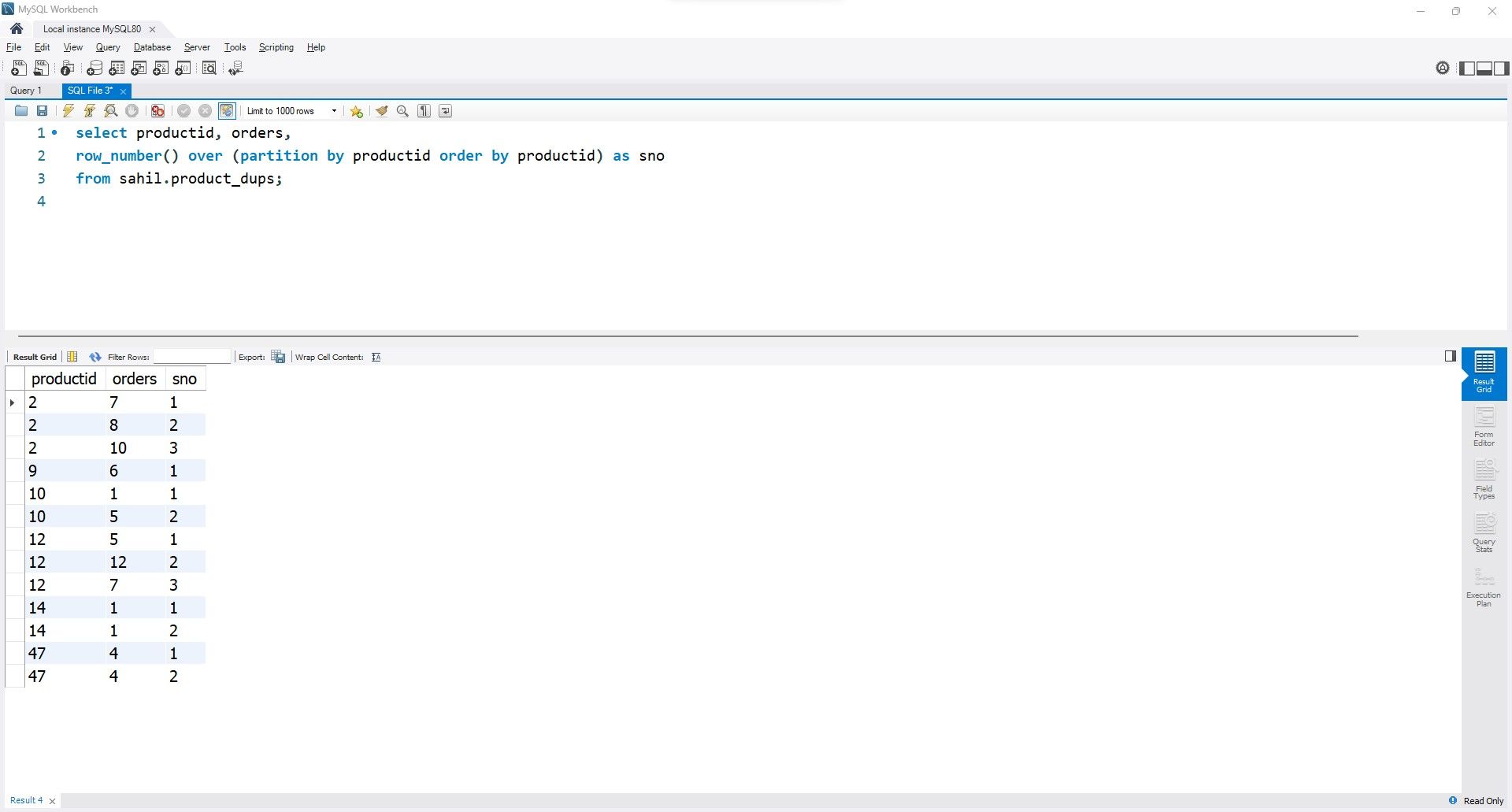
행\_number() 함수를 사용하여 다음과 같은 프로세스를 활용하여 테이블에서 중복 항목을 식별하고 구분할 수 있습니다:
select productid, orders,
row_number() over (partition by productid order by productid) as sno
from sahil.product_dups;
`row_number()` 함수는 제품 ID의 모든 고유 발생을 반복하여 해당 발생 횟수를 계산합니다.
`partition` 키워드는 중복된 값을 분할하고 각 값에 1부터 순차적으로 직렬화된 정수를 추가합니다. 분할 키워드를 사용하지 않으면 모든 제품 ID에 독점 식별자가 할당되어 목적에 맞지 않게 됩니다.
파티션 섹션 내에서 ‘주문 기준’ 절을 활용하면 오름차순과 내림차순 중에서 선택할 수 있는 기능이 부여됩니다.
마지막으로, 필터링의 단순화를 위해 필요한 경우 열에 별칭을 지정할 수 있습니다.
SQL 테이블에서 중복 행 삭제
데이터베이스 테이블 내에서 중복을 제거하는 것은 분석 결과를 왜곡할 수 있으므로 데이터 정리에서 필수적인 측면입니다. 다목적 언어인 SQL은 이러한 중복을 쉽게 식별하고 제거할 수 있는 기술을 제공합니다.
a. 고유 키워드 사용
테이블 내에서 중복된 값을 제거하기 위해 가장 일반적으로 사용되는 SQL 함수 중 하나는 “고유” 키워드입니다. 이 함수는 단일 열 내에서 중복된 항목을 제거하거나 여러 번 복제된 전체 행을 제거할 수 있습니다.
특정 열 내에서 중복 항목을 제거하려면 다음 단계를 따르세요:
select distinct productid from sahil.product_dups;
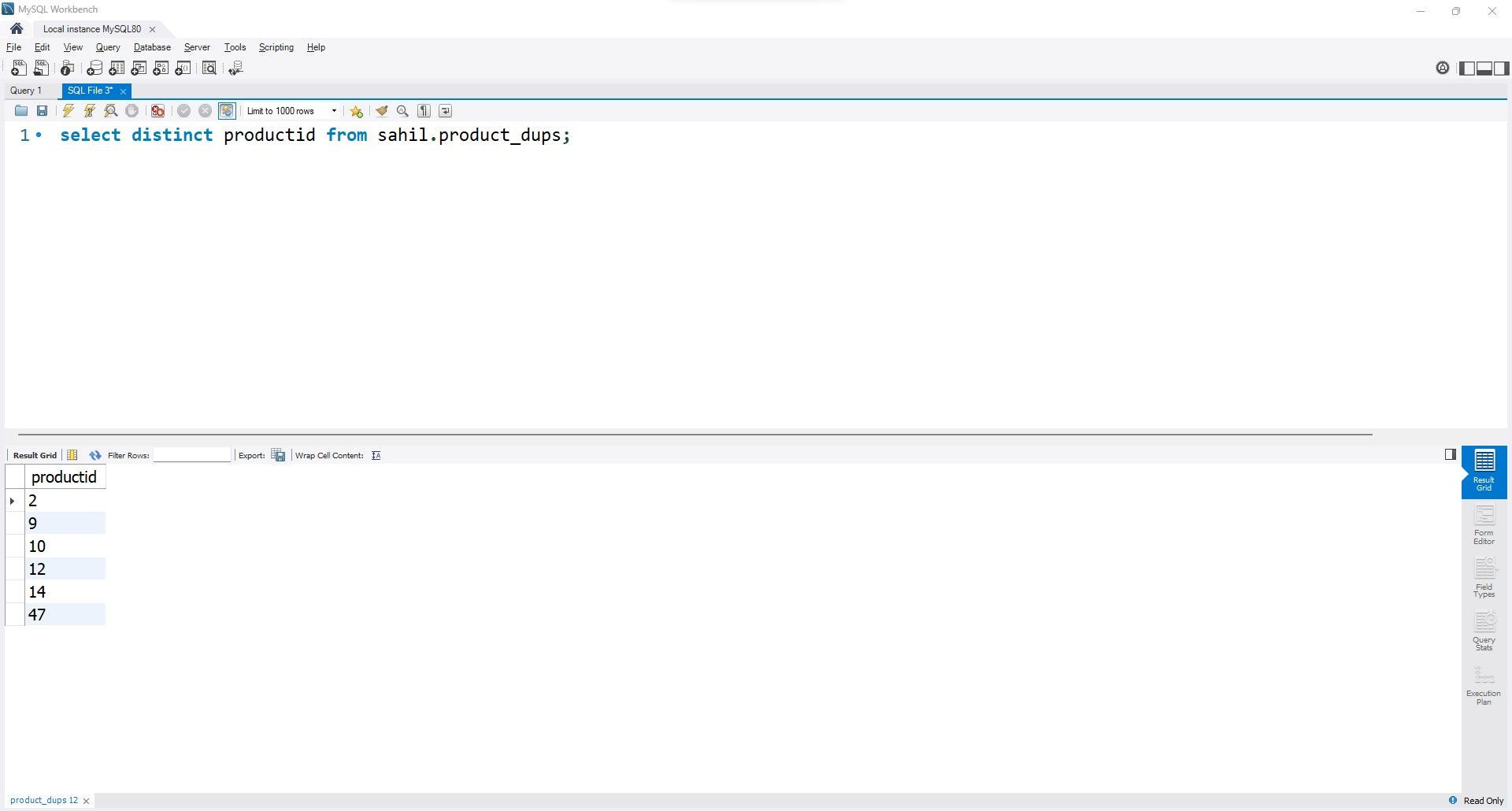
이 함수는 데이터베이스 테이블 내에서 발견되는 모든 고유한 제품 식별자로 구성된 배열을 생성합니다.
중복된 항목을 제거하기 위해 다음과 같은 조정을 구현하여 앞서 언급한 코드를 수정할 수 있습니다:
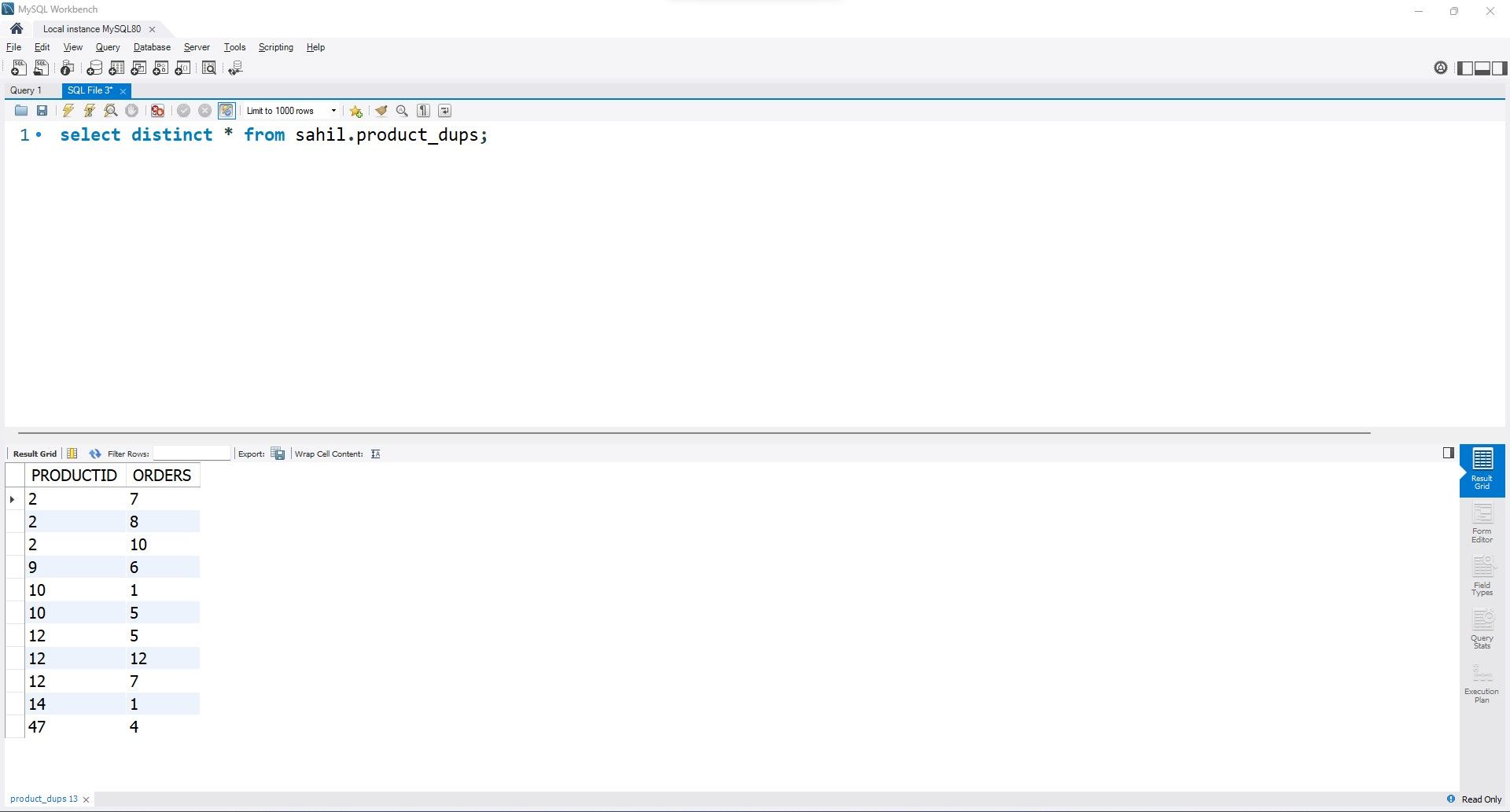
select distinct * from sahil.product_dups;
출력은 모든 고유 테이블 행의 카탈로그를 생성합니다. 결과를 살펴보면
b. 공통 테이블 표현식(CTE) 방법 사용
공통 테이블 표현식(CTE)은 일반 SQL 테이블과 유사하게 임시 테이블이지만 가상의 테이블이며 조회 중에만 활용할 수 있습니다.
공통 테이블 표현식(CTE)을 활용할 때 가장 주목할 만한 장점 중 하나는 작업이 수행되면 자동으로 존재하지 않게 되므로 나중에 이러한 테이블을 제거하기 위한 추가 쿼리가 필요하지 않다는 점입니다. 이 기술을 사용하면 다음 코드를 사용하여 중복된 데이터를 식별하고 제거할 수 있습니다.
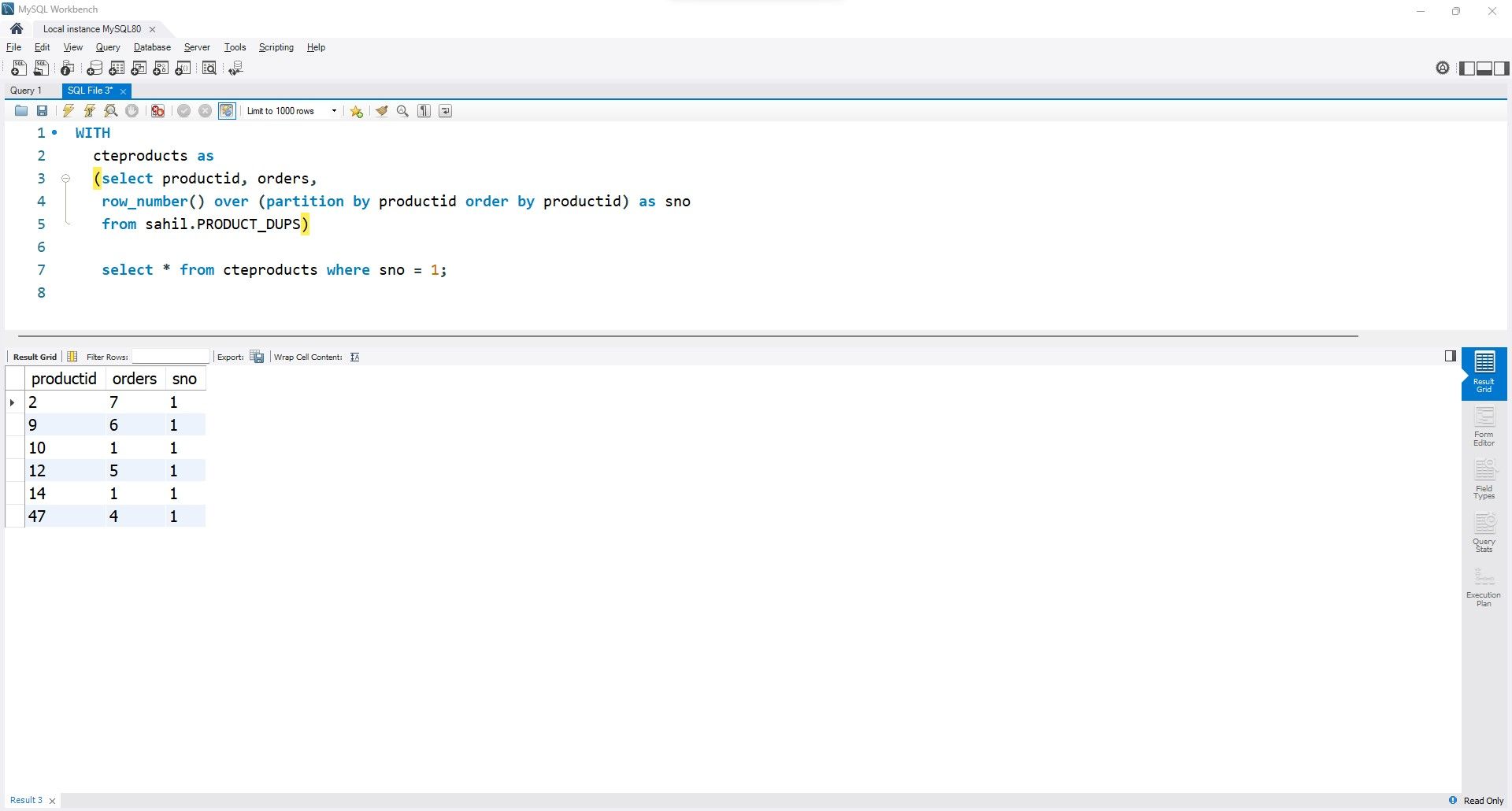
with cteproducts as
(select productid, orders,
row_number() over (partition by productid order by productid) as sno
from sahil.product_dups)
select * from cteproducts
where sno = 1;
‘시작일’ 및 ‘종료일’ 필드에서 선택한 날짜 범위에 따라 특정 기간 내 계약 체결과 관련된 데이터를 정확하게 필터링하고 분석하기 위해 계약 체결 내역 보고서를 사용해야 할 수 있습니다. 여기에는 “with” 키워드가 제공하는 기능을 활용하여 CTE 함수의 결과를 기반으로 임시 가상 테이블을 생성한 다음 다양한 필터와 계산을 통해 데이터 집합을 더욱 세분화하는 데 사용할 수 있습니다. 이러한 기능을 활용하면 사용자는 조달 운영과 관련된 성과 및 추세에 대한 귀중한 인사이트를 확보하여 향후 행동 방침에 대한 정보에 입각한 의사 결정을 내릴 수 있습니다.
다음 섹션을 참조하여 row\_number() 함수를 사용하여 제품 ID에 행 번호를 지정합니다. 파티션 함수를 통해 각 제품 ID를 암시하고 있으므로 반복되는 모든 ID는 개별 값을 갖습니다.
마지막 단계에서는 다른 SELECT 문을 통해 새로 생성된 `sno` 열에 필터링 작업을 적용합니다. 최종 출력에서 고유 값만 유지하도록 이 필터를 구성합니다.
쉬운 SQL 사용법 배우기
관계형 데이터베이스를 쿼리하고 조작하기 위한 SQL 및 해당 변형의 활용은 기본적인 쿼리 작성부터 하위 쿼리를 포함한 복잡한 분석 실행에 이르기까지 다양한 기능으로 인해 널리 주목을 받고 있습니다.
쿼리를 작성하기 전에 자신의 능력을 다듬고 코딩에 능숙해지는 것이 필수적입니다. 게임 개발에 통합하거나 코드 내에서 창의적인 기법을 활용하는 등 즐거운 방법을 통해 SQL 전문 지식을 향상시킬 수 있습니다.