양질의 데이터셋을 확보하는 것은 현대의 데이터 기반 의사 결정에 있어 필수 불가결한 요소가 되었습니다. 공개적으로 액세스할 수 있는 수많은 데이터 세트가 존재하지만, 특정 상황에서는 특정 요구사항에 맞는 맞춤형 데이터 세트를 만들어야 할 수도 있습니다. 웹 스크래핑 프로세스를 통해 웹사이트에서 데이터를 추출할 수 있으며, 이를 활용하여 맞춤형 데이터 세트를 구축할 수 있습니다.
데이터 수집 방법 개요
수동 입력, API(애플리케이션 프로그래밍 인터페이스), 공개적으로 사용 가능한 데이터베이스, 웹 페이지 추출 등 다양한 데이터 수집 기법이 존재합니다. 각 접근 방식에는 고유한 장단점이 있습니다.
데이터를 수동으로 입력하는 프로세스는 지루할 뿐만 아니라 특히 많은 양의 정보를 처리할 때 사람의 실수로 인한 부정확성이 발생할 수 있습니다. 그럼에도 불구하고 소규모 데이터 수집 작업이나 대체 데이터 소스를 쉽게 구할 수 없는 경우에는 여전히 유용할 수 있습니다.
API를 사용하면 개발자가 체계적인 방식으로 데이터를 얻고 처리할 수 있습니다. 이러한 인터페이스는 일반적으로 최신 또는 주기적으로 새로 고쳐지는 정보를 제공합니다. 그럼에도 불구하고 API에 대한 액세스가 제한되거나, 인증이 필요하거나, 사용 제한이 부과될 수 있습니다.
공개적으로 이용 가능한 수많은 데이터 세트는 다양한 주제와 분야를 포괄하며, 일반적으로 구조화된 방식으로 구성되어 있어 검색이 용이합니다. 이러한 데이터 세트는 필요한 정보가 데이터 세트에 포함되어 있다면 데이터 수집에 소요되는 시간과 노력을 줄여주는 귀중한 자원이 될 수 있습니다. 하지만 이러한 데이터 세트가 항상 특정 요구 사항을 충족하거나 최신 정보가 아닐 수도 있다는 점에 유의해야 합니다.
웹 스크래핑은 애플리케이션 프로그래밍 인터페이스(API)를 제공하지 않거나 액세스가 제한된 웹사이트에서 정보를 추출하는 방법론입니다. 이 접근 방식을 사용하면 맞춤형 추출, 확장성 및 다양한 소스에서 데이터를 얻을 수 있습니다. 하지만 프로그래밍에 대한 숙련도, HTML 아키텍처에 대한 친숙함, 법적 및 윤리적 규범 준수는 필수 전제 조건입니다.
데이터 수집을 위한 웹 스크래핑 선택
웹 스크래핑 기술을 활용하면 웹페이지 콘텐츠에서 정보를 직접 추출할 수 있어 광범위한 데이터 소스를 제공할 수 있습니다. 또한, 추출된 데이터의 선택 및 구성에 대한 제어권을 부여하여 특정 요구에 맞는 맞춤형 추출과 다양한 프로젝트에 적합한 고도로 타겟팅된 정보 획득이 가능합니다.
데이터 소스 식별
웹 스크래핑의 첫 번째 작업은 추출하고자 하는 정보를 저장하는 플랫폼을 구성하는 데이터 제공업체를 선택하는 일입니다. 데이터 제공업체를 선택할 때는 데이터 제공업체가 정한 규정을 준수하는 것이 필수적입니다. 현재 상황에서는 설명 목적으로 IMDb(인터넷 영화 데이터베이스)를 데이터 소스로 활용하는 데 중점을 둡니다.
환경 설정
pip install requests beautifulsoup4 pandas
요청 라이브러리를 활용하여 HTTP 조회를 수행하고, HTML 콘텐츠의 파싱을 위해 BeautifulSoup4를 활용하여 웹 페이지에서 정보를 추출합니다. 이후 획득한 데이터의 조작 및 분석을 위해 판다를 사용합니다.
전체 소스 코드는 GitHub 리포지토리를 통해 액세스할 수 있습니다.
웹 스크래핑 스크립트 작성
스크립트 내에서 활용하고자 하는 필요한 라이브러리를 가져와서 해당 기능 및 기능에 액세스할 수 있도록 하세요.
import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
import re
시간 및 재 모듈은 Python 표준 라이브러리에 미리 포함되어 있으므로 별도로 설치할 필요가 없습니다.
시간이 경과하면 추출 프로세스가 중단될 수 있지만, 정규 표현식을 활용하면 수집되는 웹 페이지 내의 데이터 패턴을 쉽게 관리할 수 있습니다.
아름다운가게의 기기를 활용하여 지정된 웹사이트를 샅샅이 뒤져주세요.
이 작업은 지정된 대상 URL로 HTTP GET 요청을 쉽게 전송할 수 있는 함수를 생성한 다음 BeautifulSoup 라이브러리를 사용하여 후속 응답을 검색하고 파싱해야 합니다. 구문 분석된 결과 콘텐츠는 추가 처리를 위해 BeautifulSoup 객체에 저장될 것으로 예상됩니다.
def get_soup(url, params=None, headers=None):
response = requests.get(url, params=params, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
return soup
앞서 파싱된 콘텐츠에서 데이터를 검색하는 것은 BeautifulSoup 객체를 사용하여 수행할 수 있습니다.
웹사이트에서 원하는 정보를 수집하기 위해서는 웹사이트의 기본 구조를 이해하는 것이 중요합니다. 이는 추출하고자 하는 데이터를 담고 있는 요소와 속성을 식별할 수 있는 사이트의 HTML 코드를 검토함으로써 달성할 수 있습니다. 대상 웹사이트에 액세스하려면 웹 브라우저에서 해당 URL을 열고 스크랩할 데이터가 포함된 특정 페이지로 이동하기만 하면 됩니다.
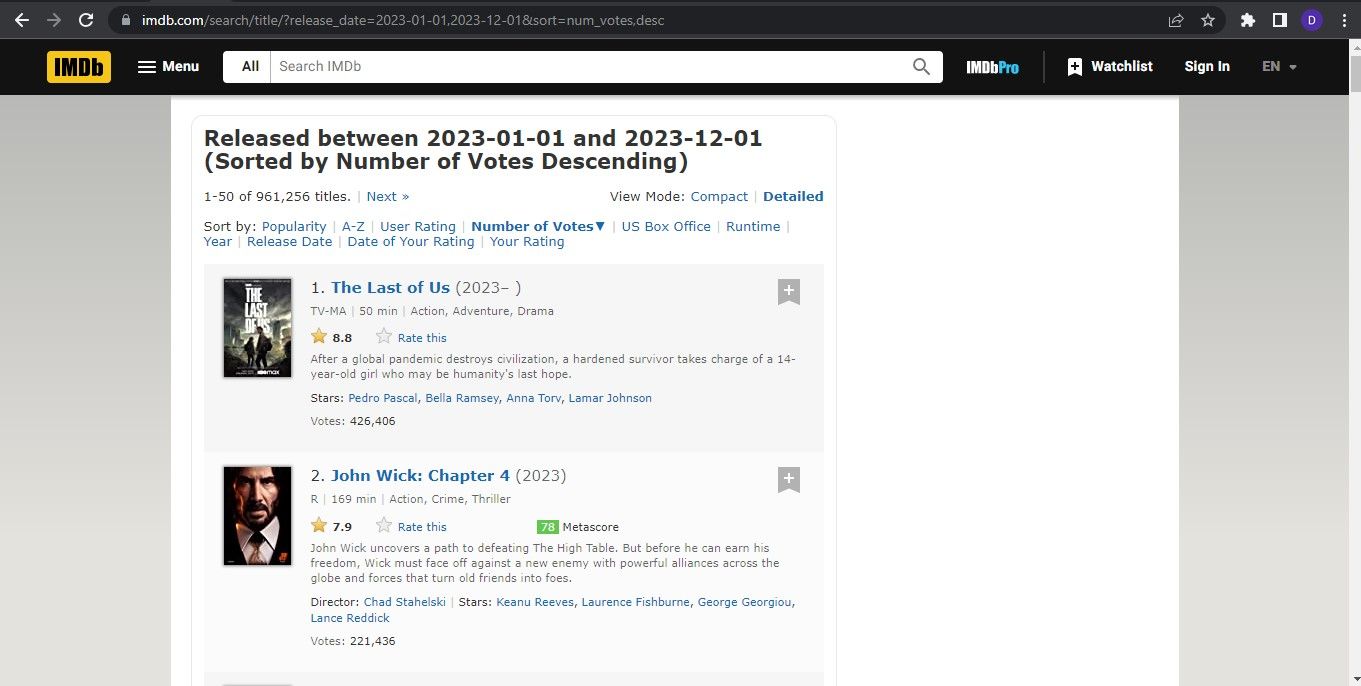
웹페이지를 마우스 오른쪽 버튼으로 클릭하고 이어지는 컨텍스트 메뉴에서 ‘검사’를 선택하면 브라우저의 개발자 도구가 열립니다.
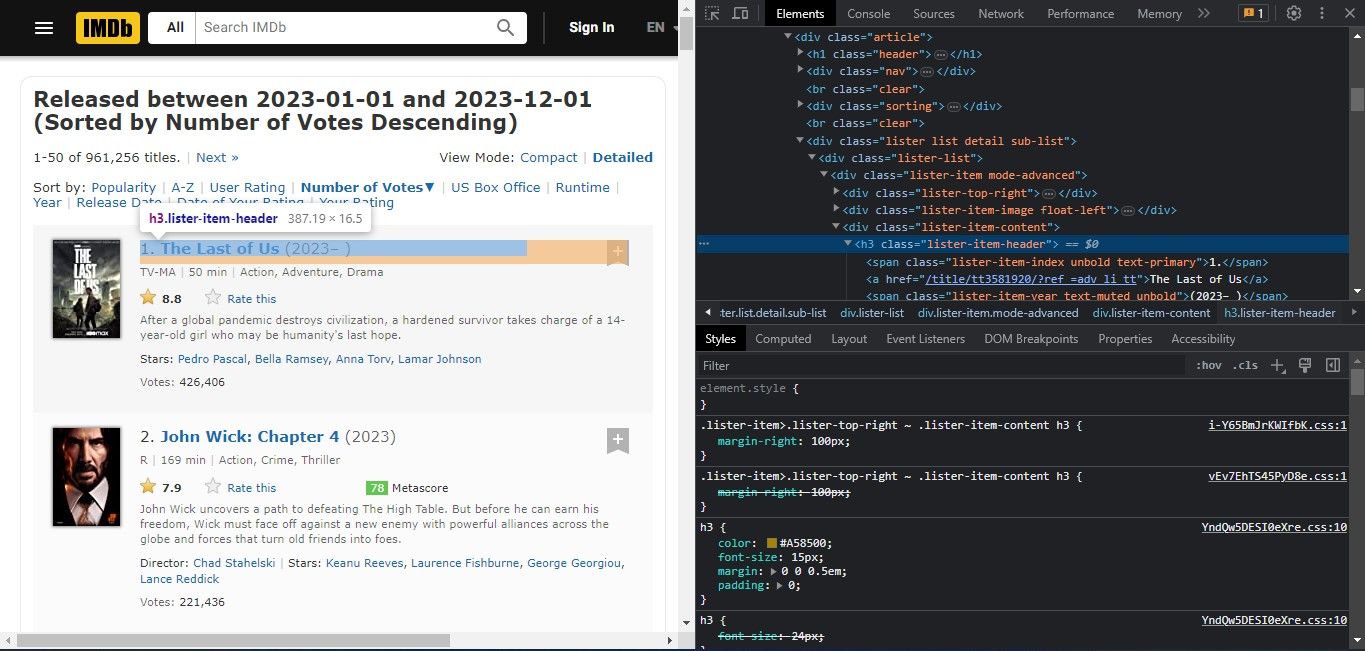
웹 스크래핑은 HTML 태그, 클래스, 속성 등 다양한 기능을 활용하여 웹사이트의 HTML 코드 내에서 특정 데이터를 검색하는 과정입니다. 웹 페이지에서 원하는 정보를 효율적으로 추출하기 위해서는 이러한 지표들을 면밀히 검토하고, 뷰티풀수프와 같은 라이브러리를 활용하여 적절한 선택기를 사용해야 합니다. 제공된 스크린샷에서 볼 수 있듯이, 영화 제목은 “lister-item-header” 클래스를 가진 요소 내에 있습니다. 추출을 진행하기 전에 추출하고자 하는 각 특성을 철저히 분석하는 것이 중요합니다.
제목, 평점, 설명, 장르, 개봉일, 감독
def extract_movie_data(movie):
title = movie.find("h3", class_="lister-item-header").find("a").text
rating = movie.find("div", class_="ratings-imdb-rating").strong.text
description = movie.find("div", class_="lister-item-content").find_all("p")[1].text.strip()
genre_element = movie.find("span", class_="genre")
genre = genre_element.text.strip() if genre_element else None
release_date = movie.find("span", class_="lister-item-year text-muted unbold").text.strip()
director_stars = movie.find("p", class_="text-muted").find_all("a")
directors = [person.text for person in director_stars[:-1]]
stars = [person.text for person in director_stars[-1:]]
movie_data = {
"Title": title,
"Rating": rating,
"Description": description,
"Genre": genre,
"Release Date": release_date,
"Directors": directors,
"Stars": stars
}
return movie_data
궁극적으로 앞의 두 함수를 활용하여 실제 웹 스크래핑 작업을 용이하게 하는 함수를 개발합니다. 이 함수는 연도와 격언을 허용해야 합니다
def scrape_imdb_movies(year, limit):
base_url = "https://www.imdb.com/search/title"
headers = {"Accept-Language": "en-US,en;q=0.9"}
movies = []
start = 1
while len(movies) < limit:
params = {
"release_date": year,
"sort": "num_votes,desc",
"start": start
}
soup = get_soup(base_url, params=params, headers=headers)
movie_list = soup.find_all("div", class_="lister-item mode-advanced")
if len(movie_list) == 0:
break
for movie in movie_list:
movie_data = extract_movie_data(movie)
movies.append(movie_data)
if len(movies) >= limit:
break
start += 50 # IMDb displays 50 movies per page
time.sleep(1) # Add a delay to avoid overwhelming the server
return movies
웹 스크래핑을 수행하기 위해 `scrape_imdb_movies` 함수를 활용합니다.
# Scrape 1000 movies released in 2023 (or as many as available)
movies = scrape_imdb_movies(2023, 1000)
앞서 언급한 작업으로 원본 소스에서 데이터를 추출했습니다.
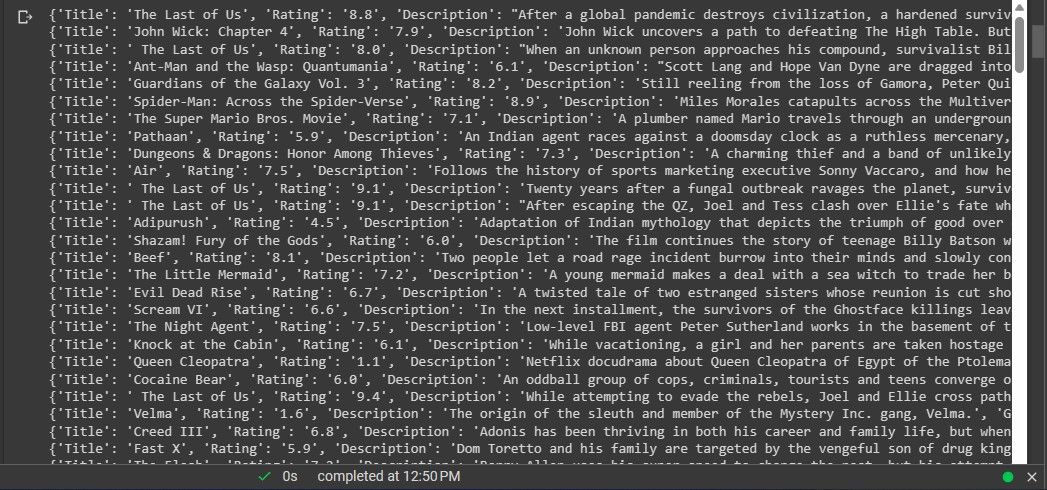
다음 단계는 앞서 언급한 정보를 활용하여 데이터셋을 생성하는 단계입니다.
스크랩된 데이터에서 데이터 세트 생성
Pandas 라이브러리를 활용하여 추출된 정보를 처리하여 데이터 프레임을 생성합니다.
df = pd.DataFrame(movies)
데이터 전처리 및 정리 작업을 수행한 후, 먼저 누락된 값이 포함된 행을 제거했습니다. 다음으로 출시일로부터 연도를 추출하여 숫자 형식으로 변환했습니다. 또한 불필요한 열을 제거하고 평점 열을 숫자 형식으로 변환했습니다. 마지막으로 제목 열에서 문자를 제거하여 알파벳 문자만 남도록 했습니다.
df = df.dropna()
df['Release Year'] = df['Release Date'].str.extract(r'(\d{4})')
df['Release Year'] = pd.to_numeric(df['Release Year'],
errors='coerce').astype('Int64')
df = df.drop(['Release Date'], axis=1)
df['Rating'] = pd.to_numeric(df['Rating'], errors='coerce')
df['Title'] = df['Title'].apply(lambda x: re.sub(r'\W+', ' ', x))
나중에 프로젝트에서 활용할 수 있도록 지정된 파일에 정보를 검색하여 저장합니다.
df.to_csv("imdb_movies_dataset.csv", index=False)
마지막으로, 데이터 집합의 초기 다섯 행을 인쇄하여 데이터 집합의 미리 보기를 생성합니다. 이렇게 하면 데이터의 모양을 검토하고 모든 것이 예상대로 표시되는지 확인할 수 있습니다.
df.head()
결과는 아래 제공된 그래픽 표현에서 확인할 수 있습니다.
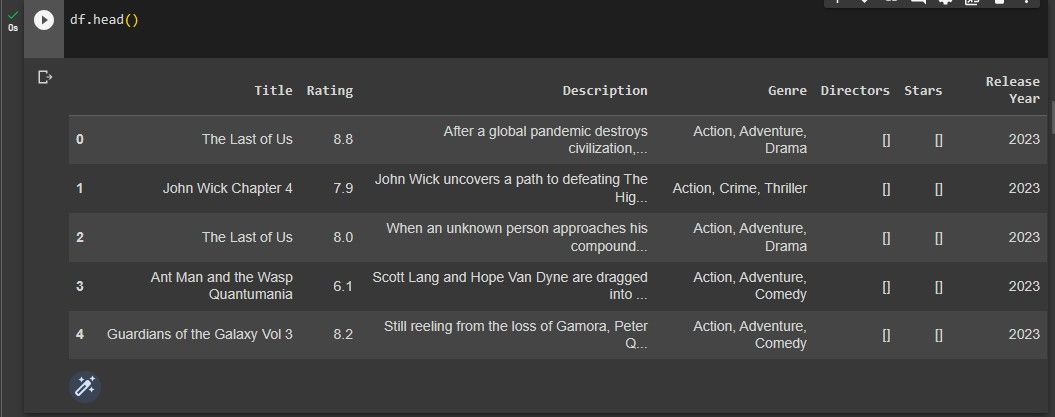
앞서 언급한 데이터 세트는 웹 스크래핑 기법을 통해 수집되었습니다.
다른 Python 라이브러리를 사용한 웹 스크래핑
Beautiful Soup은 여전히 Python에서 웹 스크래핑을 위한 인기 있는 선택이지만, 유일한 옵션은 아닙니다.다양한 특징과 기능을 갖춘 다른 라이브러리도 존재하므로 주어진 애플리케이션에 가장 적합한 라이브러리를 결정하기 위해 각각의 장단점을 철저히 조사해야 합니다.